# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

2026年具身智能这么热,
美国旧金山PI Robotics这家机器人创业公司,
你真得知道。
我也常看他们团队发的新模型,
当然,很多国内具身智能小伙伴,
比我关注多了,
因为这家公司走开源路线,
有些东西国内也能跟着用。
公司投入大,工作扎实,高速发展,
是一个很好的观察行业的“锚点”。
用新闻体说,就是,
PhysicalIntelligence是美国具身智能领域的翘楚,
(简称PI或π),他们家的模型叫π系列。
讲真,机器人还没有真正的记忆系统。
当然,有些短的记忆,
也能记清楚一些事情的先后顺序。
这里有两个概念,请看漫画:
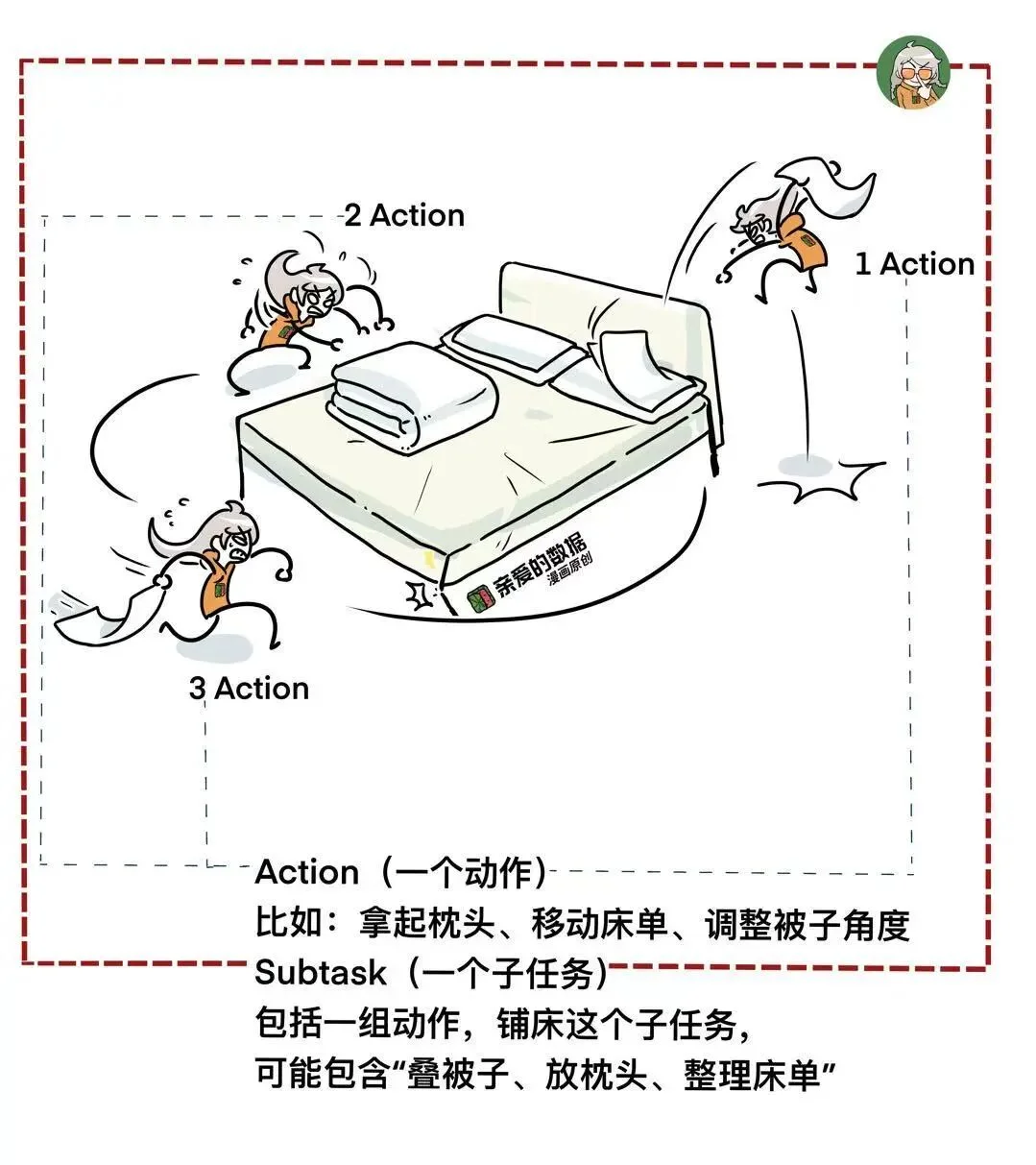
为啥说没有记忆系统呢?
要么没法存数分钟到数小时的任务情况(上下文),
要么堆砌大量原始数据,导致反应迟缓。
这也是为什么大多数具身智能干活,
只能在“严格控制“几分钟”“短任务”里打转,
还有说法是单点任务(技能)还行。
多个子任务串联,
长时间,多阶段就尴尬了。
也就是说,即便当下的模型,
单步技能点数很高,
但在面对长达十几分钟,
跨多个阶段的任务时,
它们往往表现得像“金鱼”:
只能记住最近几秒钟的视觉信息(摄像头画面里),
一旦时间长,
即使是最先进的机器人也会丢失状态,
导致错判和重复错误。

机器人干活缺啥能力?
第一,先前啥状态;
第二,规划后续做啥动作;
第三,环境变了,怎么动态调整;
真实环境从来不简单。
我说得很婉转,
在文艺晚会舞台上跳舞的机器人,
这类机器人在仿真系统提升能力,
技能点很单一。
而在受限环境下行动,
换个新环境干别的活,
恐怕要犯老年痴呆。
35岁以上排队领鸡蛋的老年人表示,
这是史上被黑的最惨的一次。
对机器人来说,和金鱼一样的记忆力是不够的。
1.记不住过去做过啥(步骤);
2.一件东西,摄像头照的那个区里看不见,
以前放哪也不记得了。
PI机器人的记忆模块,
居然是可插拔的?
是的。
我观察PI团队,
是在模型大版本迭代后,
才单独推出了一个可插拔的模块,
(叫MEM,Multi-scaleEmbodiedMemory)。
按道理,应该和大版本一起推出,
然而并没有。
中科视语CEO赵朝阳博士告诉我,
PI公司的模型,从π0.5到π0.6,
技术提升点很多,
记忆模块并不在其中,
一方面是值得单独拿出来解决,
另一个比较合理的解释,
就是做大版本的时候,
这个模块,还没有准备好;
AI行业主打一个,
冲刺总在截止日期前,
每家AI公司都一样,
好在,记忆模块(MEM)是相对独立的。
“记忆模块是一个必备的技能。
所以只不过是去年这个节点上,
我们认为记忆这件事儿在具身上也可以弄了,
不像原来那样那么虚了。”
谁不想要记忆模块呢,
我也想要。
所以,有了记忆模块有啥好?
以前的记忆技术要么只记细节记不住流程,
要么只记流程没细节,
记忆模块(MEM)直接全搞定,
还解决了两个大问题:
第一,不卡壳。
视频编码器优化了速度,
哪怕处理多摄像头画面,
反应延迟也低。
第二,不翻车。
多源数据训练避免了“记混动作”,
加了记忆还不影响操作精度,
以前加记忆会变慢的毛病彻底根治。
说实话,这都是长期困扰业界的难题。
似乎人人都在“记忆”上下功夫,
两个月前,开源团队Deepseek,
也推出了人家的记忆模块(Engram)。
市面上的知名团队都在下“记忆力”的功夫。
看上去,“记住”将是智能的下一个拐点。
从学术到产业,
围绕AI记忆能力的研究正在迅速积聚。
具身智能也没落下。
中科紫东太初具身智能部门负责人,
刘荣博士告诉我:
“大家紧盯着VLA狂卷,
因为VLA本身的难点实在也很多。”
具身智能常用的模型类型就是,
视觉-语言-动作一体化,简称VLA;
俗称技术路线。
这个类型的模型,
核心概念已经清晰,
但方法、优化、跨任务能力仍在优化。
我的观点是,该技术(模型)处于快速迭代阶段,
其实目前这个架构不错,
红利还没有吃完。
所以,大家都在这条道路上狂奔。
当然,还是得和行业一线专家聊一下。
中科紫东太初董事长王金桥,
他给了我更本质的理解:
“这个架构只是科研人员,
沿袭着大模型大力出奇迹的思路,
惯性探索,技术路线远没有定型。”
而中科紫东太初具身智能部门负责人,
刘荣博士告诉我:
“实现方法、跨本体跨任务能力仍要优化。”
我又和中科视语CEO赵朝阳博士,
聊了如何兼顾研发和工程实战的打法:
一种思路,要么模型(VLA),
直接输出机器人行动,
模型把“看到的东西,
得到的指令”和“该怎么动”,
结合在一起思考+行动,
视觉模块,让它知道所处环境长什么样,
语言模块,让它理解任务目标,
动作模块则把理解变成行为。
另一种思路,也是参考行业标杆,
FigureAI的路线。
要么用VLM+VLA,
追求极致工程化,
VLM模型协调指挥,决策判断,
VLA模型负责单步动作执行,
如,拉开冰箱门是一个单步技术点,;
关上则可能是另一个。
而打扫客厅卫生,就涉及到客厅多大,
窗户多高,几件家具之类;
打扫客厅卫生,需要先擦玻璃、擦桌子,
再扫地,最后拖地。
没做过保洁的人可能压根不知道,
地,从来都是留到最后拖的。
没搞过科研学术的人可能压根不知道,
小环节小动作,都是“多个子任务”。
“两个模型各负其责,
工程上也好调整。”刘荣博士如是说。
美国旧金山PI机器人团队的出发点,
是想在长程任务上做得好。
阻碍机器人做一系列任务的核心障碍,
是记忆。
何时记住?
记住什么?
如何记住?
接着,用这些记忆去指导,
后面行为与策略规划。
简单地把机器人看见的(所有视觉帧),
填进模型的上下文窗口既不现实,
机器人会误把无关过去行为,
当成当前决策依据。
比如,机器人试图拿起一根小筷子。
如果没有记忆功能,
机器人往往会反复以同样的方式失败。
因为它不记得之前的尝试,
所以只会重复相同的行为。
配上BGM,
估计就成了一刀不剪的B站鬼畜视频。
而有了记忆功能,
第一次失败后,
会设法成功拿起筷子。
于是,他们团队为具身智能设计的记忆架构,
就分为两层。
第一层是短期记忆,
它记录当下的视觉信息,
保持机器人对环境的持续感知。
第二层是长期记忆,
它用文字形式,
保存经验和规则,
让机器人能够跨越较长时间,
保持任务状态,
按需调整。
这里有点太技术了,
按中科视语CEO赵朝阳博士的说法,
从科研直觉去理解,
人类好久之前的记忆,
会被总结成经验,
——一朝被蛇咬,十年怕井绳;
人类近期(短期)记忆,
更具体,更生动,更多细节,
非洲大草原上,
沉睡中的母狮,
被黑曼巴毒蛇咬了一口下巴,
狮头立刻肿成表情包。
学术说法是:
短期使用细节信息支持即时行为,
长期用抽象语义保持任务语境和目标逻辑。
赵朝阳博士也聊到:
“记忆分层能设计得更细致,
长短,长中短,超长期记忆,等等。
甚至有些永远不能被遗忘,比如安全底线。”
看来以后都可以这么玩了:
大大大记忆,小小小记忆,
久而久之,研发同学说话都结巴了,
这绝对是工伤。
细想起来,这倒是和很多年前,
阿西莫夫机器人三大定律遥相呼应:
机器人不会伤害人类。
记忆本身是个很宏大的主题,
记忆和现有系统未来会是什么形态?
记忆不只是存下什么,
而是进化的底层动力:
1.整体目标是什么
2.需要先做什么再做什么
3.现在做到哪一步了
4.这一步怎么做
5.下一步该做什么
具身智能目前在这个大趋势上,
要做出来真正有记忆的机器人,
如何在复杂、长期任务中持续成长和自适应。
具身智能只是会感知、会执行,不够。
而是会记住、会推理,
会运用过去的经验来塑造未来的策略。
具身智能这么热,还有一个原因,
中科紫东太初董事长王金桥
是这么说的:
“有太多事情可以做,
或者说,根本做不过来,
原因是走得最快的是大语言模型,
那么大语言模型踩过的坑,
一定指导多模态大模型。
多模态模型踩过的坑,
一定指导具身智能大模型。”

One More thing
下内容包含大量科研黑话和学术暴击,
看不懂不丢人,能看完的都是狠人,
建议非战斗人员提前服用冰美式。
为什么不用Transformer-XL自回归?
答案:不用的原因有三个:
第一,必须逐步生成,每步依赖前一步输出,
不支持并行推理,效率低。
第二,视觉帧或连续动作序列很长时处理长序列会越来越慢。
第三,缺乏直接视觉结构建模能力。
为什么PI机器人的记忆模块可插拔?
这个问题,赵朝阳博士给我好好讲了讲。
模型π0.6和π0.6*一起发布的,
加入真机强化学习,
这将会是未来一段时间VLA的主流打法。
上一种利器尚且不够,
再把记忆模块也加持上。
而以前,
还在用Transformer-XL做自回归的,
现在都不用了。
MEM设计成可插拔不可谓不巧妙,
双重否定表达作者非常肯定。
MEM模型用了谷歌的Gemma3(4B),
这是在π0.5架构基础上的升级版本,
π0.5使用的是Gemma2.6。
MEM的可插拔特性主要体现在记忆增强模块上,
分为短期记忆和长期记忆两部分。
在短期记忆方面,
模型对ViT模块进行了优化,
使其能够处理更多历史观察帧,
从而提升视觉信息的吞吐量。
具体来说,优化主要集中在时间注意力和空间注意力结构上,
因为MEM很新,厂商尚未开源,也可以理解。
长期记忆部分,就更重要了,
甚至可以说是最重要的“弹药”,
那就是数据上下功夫。
用大语言模型生成训练数据的方式来增强。
先总结(抽象在数据里),再让模型学习。
Data teachingand machine learning.
模型会生成类似链式推理的摘要和总结数据,
造数据优化长期记忆,到底怎么做的呢?
我们认为:关键在于,
造一个带摘要+总结的样本数据,
还要跟他原本样本的视频帧情节时间步骤对应上
最后,再用这些数据训练主干网络,
(视觉-语言模型,Gemma),
这样,长期记忆不仅能记录下事件,
还抽象经验,用于后续推理。
我感慨整个设计很巧妙,
保证了短期记忆专注于即时操作信息,
而长期记忆提供跨任务的连续上下文支持。

陶大程是大晓机器人首席科学家。目前,他任职于新加坡南洋理工大学,担任杰出大学教授。同时,澳大利亚科学院院士,欧洲科学院外籍院士,当选IEEE、ACM、AAAS等多个国际权威学会会士。长期聚焦于将统计学和数学方法引入人工智能,在表征学习、计算机视觉与深度学习等方向具有奠基性贡献。
问题一:记忆是个宏大命题,
以记忆模块对现有具身系统的影响来看,
以您的见识,
未来会是个啥形态呢?
陶大程教授回答:未来的记忆,不会只是一个“外挂模块”,而会成为具身系统的时间操作系统。因为ACE-Brain-0其实告诉我们,具身统一的难点,不在于单个技能,而在于如何把不同域、不同阶段、不同粒度的知识组织起来并长期保留下来;它用spatialscaffold解决的是“跨embodiment的共享结构”问题。与之对称,记忆解决的其实是“跨时间的共享结构”问题。一个解决“不同机器人/不同场景之间怎么统一”,一个解决“同一个机器人在不同时间怎么连续”。所以未来真正强的具身系统,一定不是单纯的VLA,而是空间骨架+时间记忆的耦合系统。
因此,未来具身里的记忆形态,可能会有五层:
第一层是感知工作记忆。这层记最近几秒到几十秒的视觉、触觉、位姿和交互状态,用来处理遮挡、局部失误、抓取重试、视野之外的短时补偿。
第二层是情节记忆。它记录“刚刚发生了什么、哪一步成功了、哪一步失败了、失败后换过什么策略”,服务分钟级任务。
第三层是语义/程序记忆。它不是记细节画面,而是记“我现在做到哪一步、这个任务的标准顺序是什么、这个对象通常应该如何处理”。
第四层是空间记忆。这是ACE-Brain-0给你的重要启发:未来记忆不能只是文本摘要,还必须带有空间scaffold,也就是物体位置、相对关系、可达性、场景拓扑。
第五层是反事实记忆,也就是可执行的世界表征:不是只记“过去如何”,还要能内部模拟“未来可能如何”。这是worldmodel真正进入具身主干之后,记忆会新增的一层。
第六层是不可遗忘记忆。未来机器人一定会有一部分memory不是为了提升任务成功率,而是为了固化安全边界、人体禁区、设备极限、规范流程。
未来的具身记忆,不是更大的contextwindow,而是“分层的、空间化的、可调用的、可修订的、可执行的MemoryOS”。
问题二:具身借鉴LLM经验,
借鉴VLM经验是必然的,
本质该怎么理解?
陶大程教授回答:具身借鉴LLM/VLM,不是在借一个模型外形,而是在借一整套“如何从海量异构数据中提炼共享先验、再把共享先验迁移到具体任务”的方法论。
第一层本质,是抽象压缩能力;
第二层本质,是跨模态对齐能力;
第三层本质,是空间共享能力
(ACE-Brain-0:sharedscaffold);
第四层本质,是自举改进能力
(self-evolutionlearning,
为worldmodel提供了机制性侧证);
第五层本质,是有组织的训练
(ACE-Brain-0)。
第三层:ACE-Brain-0给出了自动驾驶、无人机、机器人操作虽然形态不同、动作空间不同,但都依赖3D空间理解、物体布局建模、几何关系推理和空间后果预测。
第四层:ACE-Brain-0其实也在回答,
“为什么不能所有东西一锅炖”。
混合jointtraining会带来长尾分布、
梯度干扰、领域稀释;
顺序微调又会造成灾难性遗忘。所以需要Specialize-Reconcile:
先建专业能力,最后再融合。
问题三:您的论文中曾强调,
“通用具身智能要求在异构具身
(例如自动驾驶、机器人和无人机),
之间具备强大的泛化能力。”
具身作为前沿技术技术,
您是如何理解目前具身产业的?
陶大程教授回答:
第一,不能把具身产业只理解成,
“人形机器人产业”。
第二,产业真正的壁垒不是模型本身,
而是“经验回流闭环”。
产业中的记忆,不只是模型内部记忆,
更是企业级经验记忆。
第三,产业落地不是单靠端到端autonomy,
而是“自动化+人类兜底+再学习”的混合系统。
第四,世界模型(WorldModel),
将成为产业主战场,
支撑PhysicalAI的规模化训练。
未来PhysicalAI的真正基础设施,
会包括一个可扩展、可校准、可评测、可生成数据的worldmodel。
第五,数据供给方式本身,就是产业路线分水岭。
FYI,请自取:
π₀
论文标题:《π₀: A Vision-Language-Action Flow Model for General Robot Control》
论文地址:https://arxiv.org/pdf/2410.24164
π0.5
论文标题:《π0.5: a Vision-Language-Action Model with Open-World Generalization》
论文地址:https://arxiv.org/pdf/2504.16054
π*₀.₆
论文标题:《π*(0.6): a VLA That Learns From Experience》
论文地址:https://arxiv.org/pdf/2511.14759v2
Reference:
1. Ziyang Gong, Zehang Luo, Anke Tang, et al.: ACE-Brain-0: Spatial Intelligence as a Shared Scaffold for Universal Embodiments. arXiv:2603.03198
2. Shi Fu, Yingjie Wang, Yuzhu Chen, Xinmei Tian, Dacheng Tao: A Theoretical Perspective: How to Prevent Model Collapse in Self-consuming Training Loops. ICLR 2025
文章来自于"亲爱的数据",作者 "亲爱的数据"。



【开源免费】ai-comic-factory是一个利用AI生成漫画的创作工具。该项目通过大语言模型和扩散模型的组合使用,可以让没有任何绘画基础的用户完成属于自己的漫画创作。
项目地址:https://github.com/jbilcke-hf/ai-comic-factory?tab=readme-ov-file
在线使用:https://aicomicfactory.app/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
