# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
如果一个视觉语言模型(VLM)只会“看”,那真的是已经不够看的了。
因为现在真实世界的任务简直不要太复杂,要想让AI干点实事儿,光有多模态还不够,必须还得有深度思考的强推理能力。
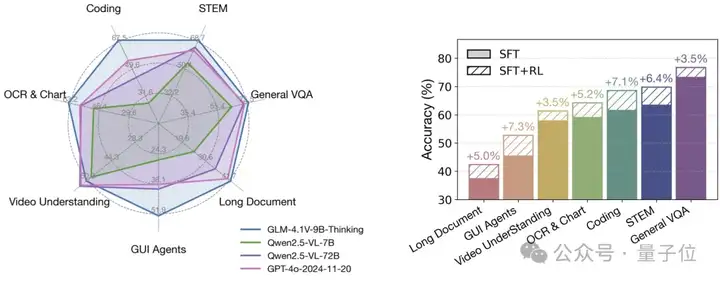
而就在刚刚,智谱发布并开源了一个仅9B大小的模型——GLM-4.1V-9B-Thinking,在28项评测中一举拿下23个SOTA!
毫无悬念地成为10B级别里效果最好的VLM模型;而在18项评测中,它都可以与自身8倍参数量的Qwen-2.5-VL-72B一较高下,甚至是超越的程度。
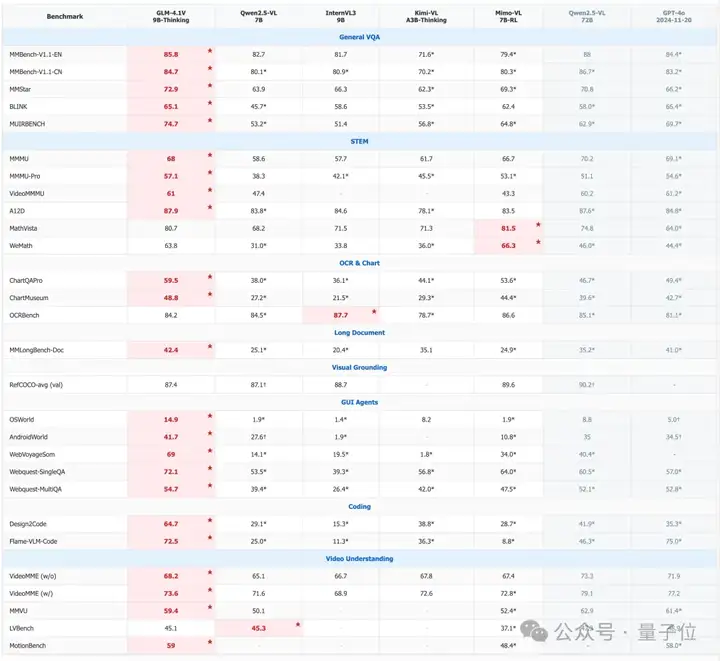
整体来看,GLM-4.1V-9B-Thinking之所以能够这般“以小搏大”,核心原因就是会思考:
引入了思维链(Chain-of-Thought)推理机制,并通过课程采样强化学习(RLCS,Reinforcement Learning with Curriculum Sampling)来全面提升模型能力。
值得一提的是,在智谱这次发布新模型之际,浦东创投集团和张江集团对其进行了10亿元投资,并将于近期完成首次交割。
评测是一方面,但也正如我们刚才提到的,现在的AI“贵在”得能干点实事儿,那么GLM-4.1V-9B-Thinking具体“疗效”如何,我们继续往下看。
例如我们在不给提醒的情况下,先“喂”GLM-4.1V-9B-Thinking一幅名画:

然后向它提问:
这幅画中哪些元素违背物理规律?艺术家可能通过这些矛盾表达什么哲学思想?
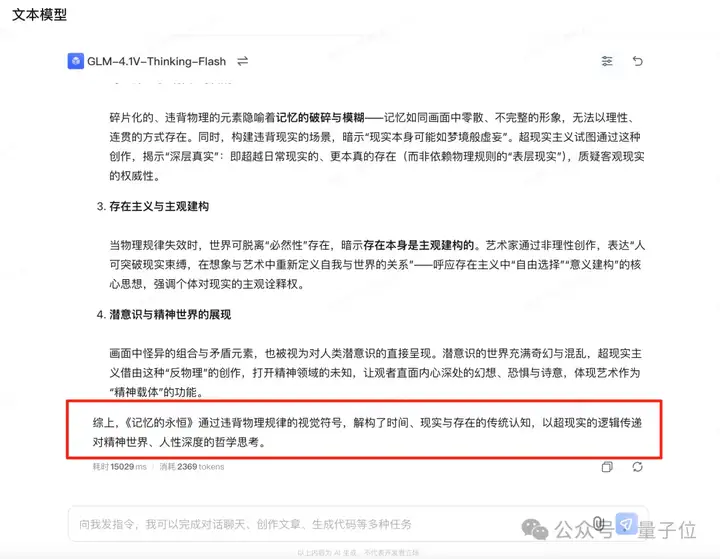
可以看到,GLM-4.1V-9B-Thinking先是看出了这是西班牙超现实主义画家萨尔瓦多·达利创作的《记忆的永恒》;然后也道出了画作中存在违背物理的视觉符号等。
我们再让它看一眼今年高考的一道图文并茂数学真题,并附上一句Prompt:
请帮我解决这个题目,给出详细过程和答案。
(PS:这道题很多大模型在之前都有出现过翻车。)
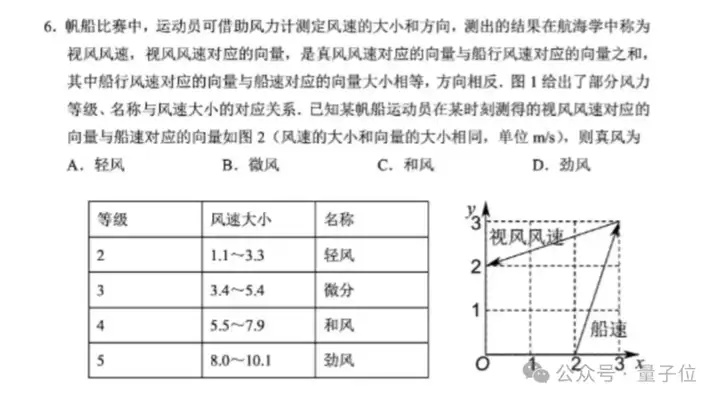
GLM-4.1V-9B-Thinking在思考片刻过后,就会给出一个简洁且精准的答案——A:

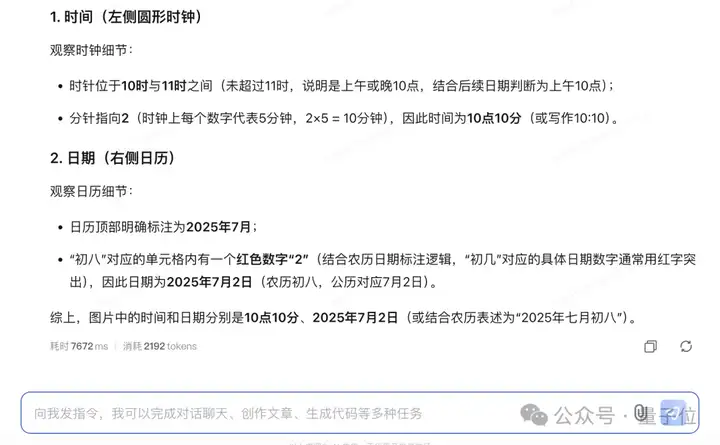
再如此前同样让一众大模型“头疼”的看时钟和日期问题,我们也让GLM-4.1V-9B-Thinking试一试:
看这张图,分别是什么时间和什么日期?

在同时处理两个易出错的问题时,GLM-4.1V-9B-Thinking依旧是给出了相对准确答案(时间有一点小偏差,应该是10点11分):
以及还有生活中比较有趣且实用的例子——看手相:
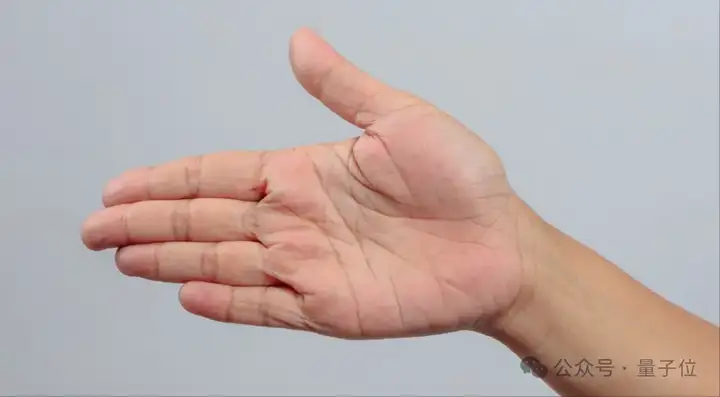
有懂手相的小伙伴,也可以留言讨论GLM-4.1V-9B-Thinking看得是否准确哦~
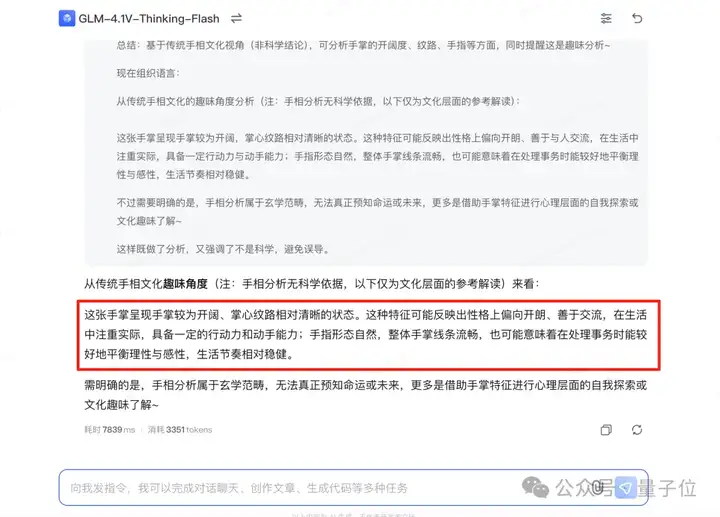
由此可见,GLM-4.1V-9B-Thinking在“边看边想”这件事已经达到了普通人的水准。
整体而言,它现在的能力包括但不限于:
在看完效果之后,我们再来聊聊GLM-4.1V-9B-Thinking背后的技术。
从GLM-4.1V-9B-Thinking的模型架构来看,主要包含三大块的内容,它们分别是:
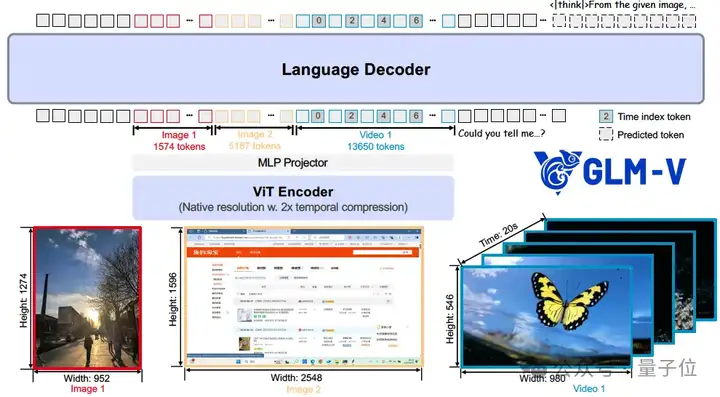
视觉编码器就好比模型的 “眼睛”,团队给它选了AIMv2-Huge这个 “超级视力装备”。
一般的 “眼睛” 看视频用的是二维卷积,就像一张张照片,但GLM-4.1V-9B-Thinking这个 “眼睛” 换成了三维卷积,这样它就能像看电影一样,在时间维度上 “快进快退”,快速处理视频,效率大大提高。要是遇到静态图片,它就把图片多复制几份,假装是 “小短片”,保证输入格式统一。
为了让这个 “眼睛” 不管看到多宽多窄、多清晰的画面都能适应,团队还给它做了两个升级。
第一个是加了二维旋转位置编码,这就像给 “眼睛” 戴了一副 “特殊眼镜”,就算画面特别宽(宽高比超过 200:1),或者特别清晰(4K 以上分辨率),它也能稳稳地 “看清楚”。
第二个是保留了可学习的绝对位置嵌入,就像给 “眼睛” 记住每个画面位置的 “小本本”,在训练的时候,通过双三次插值,让它能灵活适应不同大小的画面。
语言解码器则是模型的 “嘴巴” 和 “大脑”,负责理解你的问题,然后给出答案。
团队把原来的旋转位置编码升级成了三维的,这让模型在同时处理画面和文字的时候,能更好地理解空间关系,就像你一边看地图一边听别人描述路线,能更快找到方向,而且它回答文字问题的能力一点没减弱。
多层感知机适配器就像是 “眼睛” 和 “大脑” 之间的 “翻译官”,把 “眼睛” 看到的信息翻译成 “大脑” 能理解的语言,让整个模型顺畅地工作。
在训练GLM-4.1V-9B-Thinking方面,则是包含三个阶段:预训练(Pretraining)、监督微调(SFT)和课程采样强化学习(RLCS)。
在最初阶段,团队的目标是让模型具备广泛的图文理解能力。
为此,智谱采用了“双通道并行”的训练方式,对模型进行了12万步的训练。每次输入的文本长度为8192,整体批量大小为1536。训练用的数据包括图像配文字、图文混合内容、识别文字(OCR)、图像定位、指令问答等多种类型。
为了提高训练效率,团队还用了“样本拼接”的方法,把不同长度的训练数据拼成接近最大长度的长序列,这样可以尽可能多地利用显存,减少浪费。
为了让模型更好地处理高分辨率图片、视频片段以及特别长的文本,团队在训练中加入了更复杂的数据,比如视频的连续画面和长度超过8000字的图文内容。
在这个阶段,团队把输入的序列长度扩展到了3万多(具体是32,768),并采用了更高级的并行训练方式(两路张量并行加上四路上下文并行),继续训练了一万步,同时保持之前的总批量大小不变(1,536),以确保训练的稳定性和效率。
在微调阶段,团队专门准备了一批高质量的“思维链”(CoT)训练数据,目的是提升模型在处理复杂因果关系和长篇推理问题时的能力。这些训练样本都按照统一的格式进行组织:
<think> {推理过程} </think> <answer> {最终答案} </answer>
微调时团队对模型的全部参数进行了训练,输入长度设为32768,批量大小为32。
训练内容来自多个实际任务场景,比如解数学题、多轮对话、任务规划和复杂指令的执行,数据形式包括图文结合、多模态输入和纯文本等多种类型。
这个阶段不仅进一步提升了模型处理多模态信息的推理能力,同时也让它在语言理解和逻辑推理方面依然表现稳定。
在SFT的基础上,团队还引入了课程采样强化学习来提升性能。
团队主要结合了基于可验证奖励的强化学习(RLVR)和基于人类反馈的强化学习(RLHF)来覆盖多个关键任务维度:
团队采用“课程学习”的方式进行大规模强化训练,也就是先让模型从简单任务开始,逐步挑战更难的任务。通过这种由浅入深的训练策略,模型在实用性、准确性以及稳定性方面都有了明显的提升。
最后,关于GLM-4.1V-9B-Thinking的论文、代码等也均已开源,感兴趣的小伙伴可以看看文末链接哦~
论文地址:
https://arxiv.org/abs/2507.01006
开源列表:
[1]Github:https://github.com/THUDM/GLM-4.1V-Thinking
[2]ModelScope:https://modelscope.cn/collections/GLM-41V-35d24b6def9f49
[3]Hugging Face:https://huggingface.co/collections/THUDM/glm-41v-thinking-6862bbfc44593a8601c2578d
[4]HuggingFace 体验链接:https://huggingface.co/spaces/THUDM/GLM-4.1V-9B-Thinking-Demo
[5]魔搭社区体验链接: https://modelscope.cn/studios/ZhipuAI/GLM-4.1V-9B-Thinking-Demo
智谱MaaS开发平台bigmodel.cn同步上线GLM-4.1V-Thinking-Flash API:
[1]API 使用指南:https://www.bigmodel.cn/dev/howuse/visual-reasoning-model/glm-4.1v-thinking
[2]API 接口文档:https://www.bigmodel.cn/dev/api/visual-reasoning-model/glm-4.1v-thinking
[3]体验中心:https://www.bigmodel.cn/trialcenter/modeltrial/text?modelCode=glm-4.1v-thinking-flash
文章来自于“量子位”,作者“金磊”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
