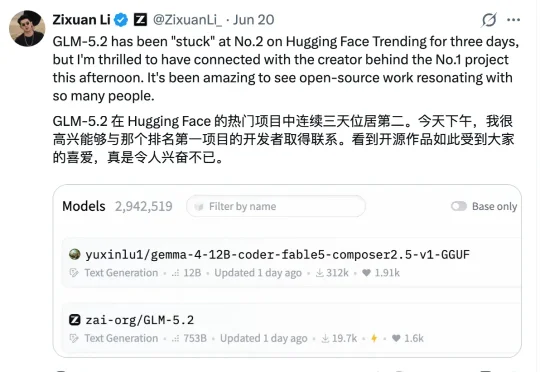
抱抱脸模型TOP榜,我现在只服yuxinlu1
抱抱脸模型TOP榜,我现在只服yuxinlu1一位个人开发者,竟然在一众大厂中,杀进了抱抱脸Models Trending榜的前排?!突然出现了一个个人账号:yuxinlu1。再一看下载量——最新数据已高达20.7万和53.6万。好家伙,这是什么神仙模型来了?
来自主题: AI资讯
8491 点击 2026-06-28 15:28
 搜索
搜索
一位个人开发者,竟然在一众大厂中,杀进了抱抱脸Models Trending榜的前排?!突然出现了一个个人账号:yuxinlu1。再一看下载量——最新数据已高达20.7万和53.6万。好家伙,这是什么神仙模型来了?

最近几天,一个 3B 的小模型在 X 上火了,因为在一些难度可验证的推理任务上(比如编程),它进入了 Gemini 3 Pro、GPT-5 high、Claude Opus 4.5、GLM-5、Kimi K2.5 等前沿模型的性能区间,而它的体积远小于这些模型。

大模型再强,也读不懂你公司那一柜子的合同、发票和扫描件。在"纸张世界"和"LLM世界"之间,缺一座桥——而百度开源的 PaddleOCR,可能就是当下最稳的那座。
就在刚刚,Siri借谷歌的1.2万亿参数Gemini「重生」了!在今夜的苹果WWDC 2026上,Siri彻底迎来新生。结合设备端小模型,苹果打造了混合智能架构,让Siri在各个APP之间无缝穿梭。
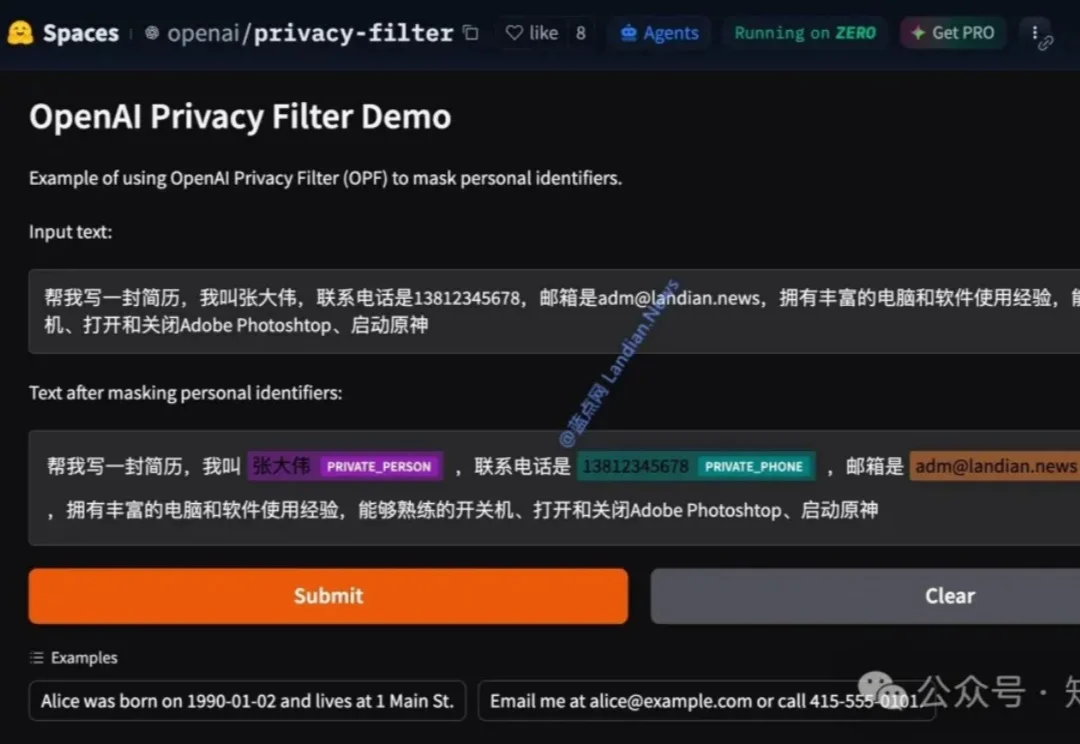
你有没有过这样的经历:把聊天记录、用户反馈或内部文档丢给大模型时,总担心里面夹杂着真实姓名、手机号、邮箱甚至 API key,最后只能手动一条条删?或者团队在处理海量数据时,规则写的正则永远漏掉那些“藏在句子里的隐私”。
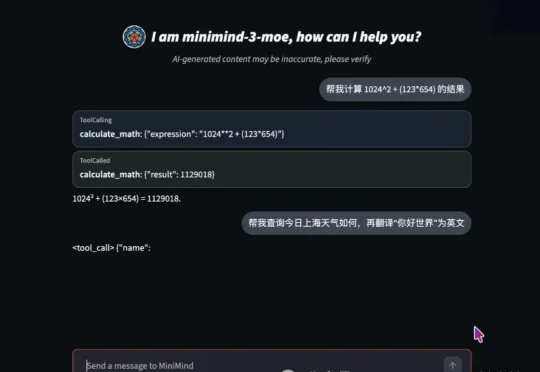
我最近当 AI 班狗刷抖音,一周里被同一个项目推流了三次。项目叫 MiniMind。打开 GitHub,50.4K stars,持续上涨种。这个项目大致就是:几块钱,几个小时,从 0 开始训练一个几十 MB 的小模型。

jina-embeddings-v5-omni正式发布,我们把 v5-text 向量模型的能力延伸到图像、音频和视频。文本侧不变,v5-omni 产出的文本向量与 v5-text逐字节一致,无需重建任何已有索引。
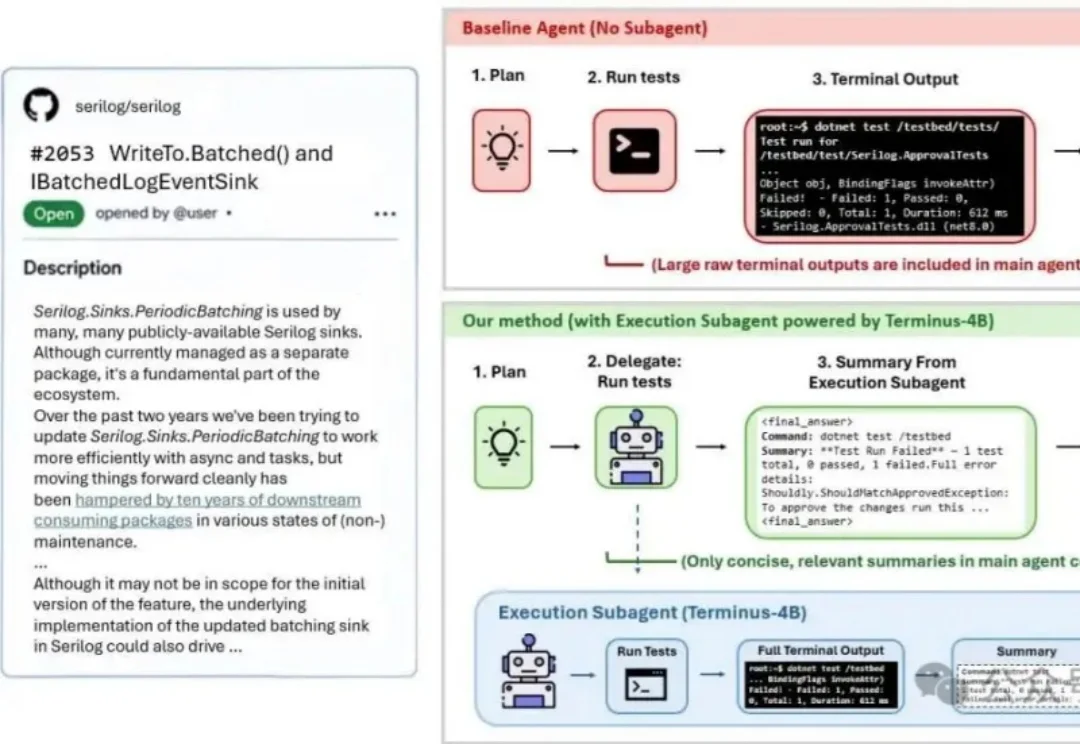
您有没有想过:在代码Agent里,执行终端命令、跑测试、读报错、总结日志这种任务,用Claude Opus、Claude Sonnet、GPT-5.3-Codex这类昂贵Token的大模型来执行,是不是有点浪费?一定要这么做吗?
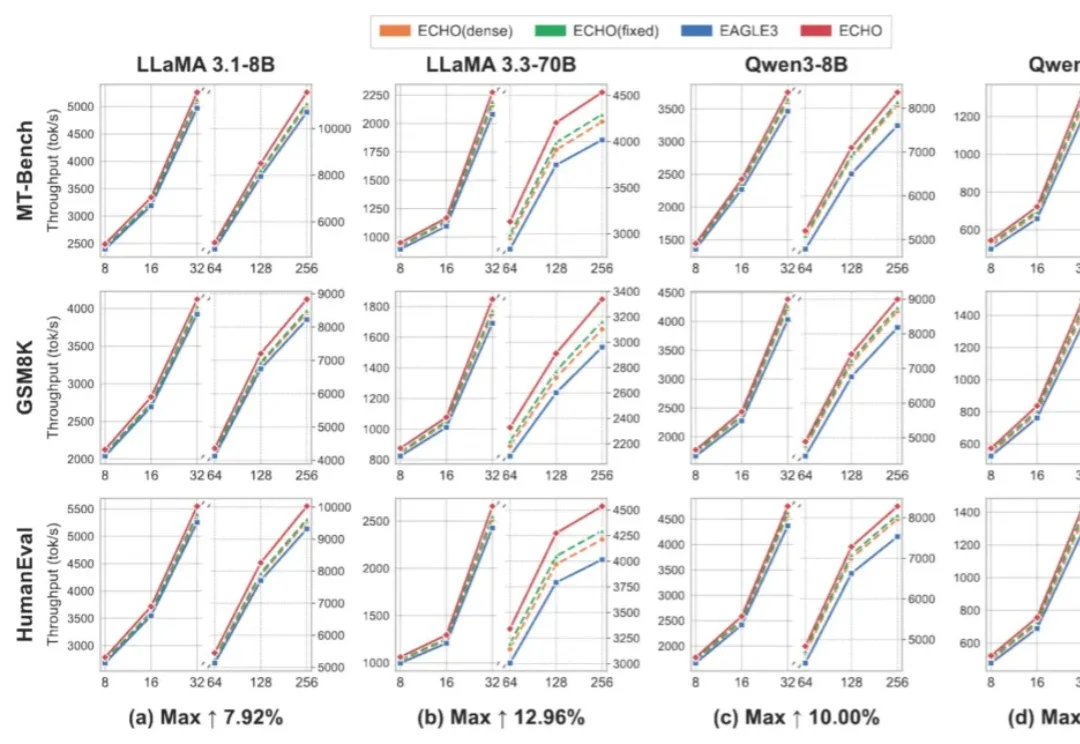
随着大模型参数规模持续扩大,推理成本已经成为生产级 LLM 服务的核心瓶颈。投机解码(Speculative Decoding, SD)通过「小模型 draft + 大模型 verify」的方式,将多个候选 token 放到一次目标模型前向中并行验证,从而缓解自回归解码的串行瓶颈。
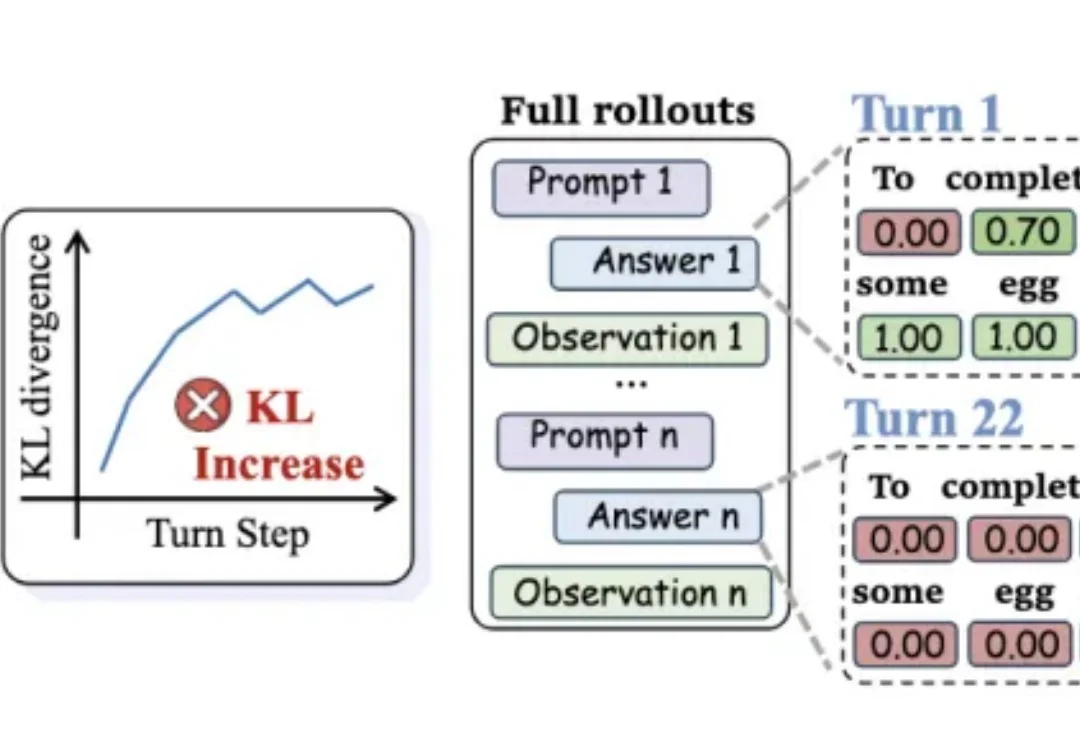
把强大模型的能力“蒸馏”给小模型,听起来很美—— 但放到多轮对话Agent场景里,效果往往一塌糊涂。