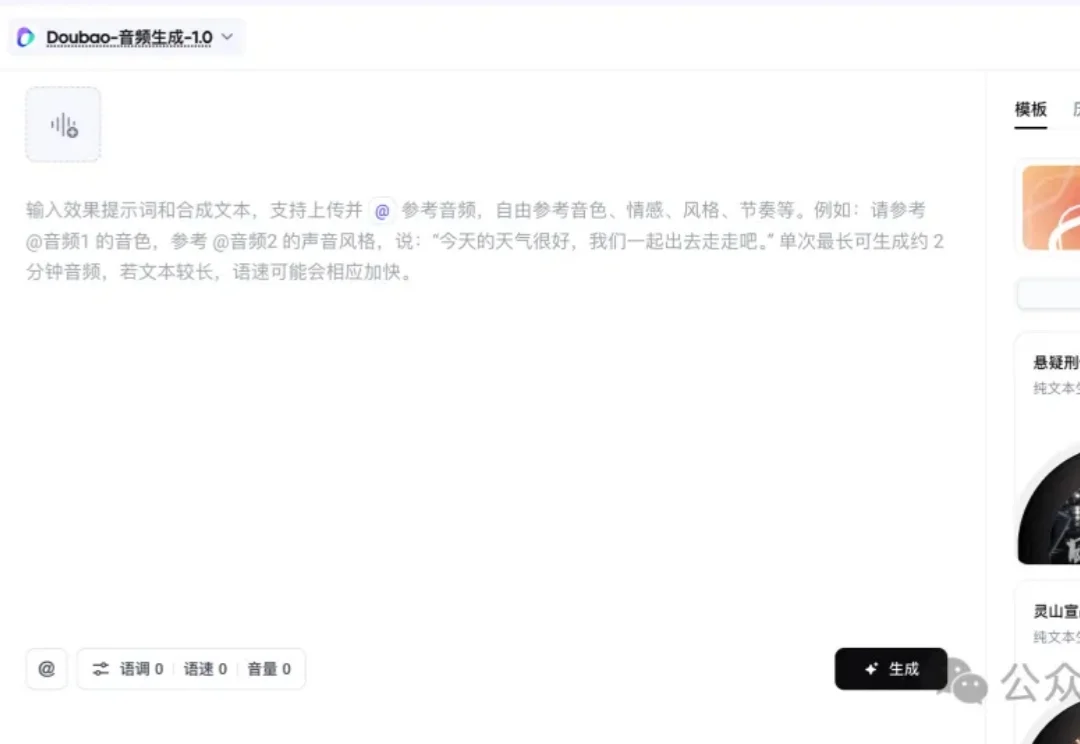
实测豆包音频生成模型:语音模型的Seedance2.0时刻来了!
实测豆包音频生成模型:语音模型的Seedance2.0时刻来了!火山引擎今天上线了全新的语音模型—— 豆包音频生成模型 1.0(Seed-Audio 1.0)。
来自主题: AI产品测评
8017 点击 2026-06-24 10:29
 搜索
搜索
火山引擎今天上线了全新的语音模型—— 豆包音频生成模型 1.0(Seed-Audio 1.0)。

ElevenLabs的声音克隆和长文本音频生成质量确实很好,但也太贵了。
ElevenLabs的声音克隆和长文本音频生成质量确实很好,但也太贵了。

自扩散模型提出以来,它不仅在图像、视频和音频生成方面取得了优异效果,也正逐渐成为解决图像复原、超分辨率、去模糊等逆问题的重要工具。

港科大团队提出音频生成统一模型AudioX,只需一个模型,就能从文本、视频、图像等任意模态生成高质量音效和音乐,在多项基准上超越专家模型。团队同时开源了700万样本的细粒度标注数据集IF-caps与可控T2A评测基准T2A-bench,并在该基准上大幅领先现有方法。论文已被ICLR 2026接收。

xAI“迄今为止最强大的视频音频生成模型”Grok Imagine 1.0版本,正式全面上线。

今天凌晨,马斯克的大模型独角兽xAI祭出最新视频生成模型Imagine v0.9,免费向所有用户开放。一周前,OpenAI发布了旗舰视频和音频生成模型Sora 2,此次更新或许是马斯克对Sora 2的直接回应。
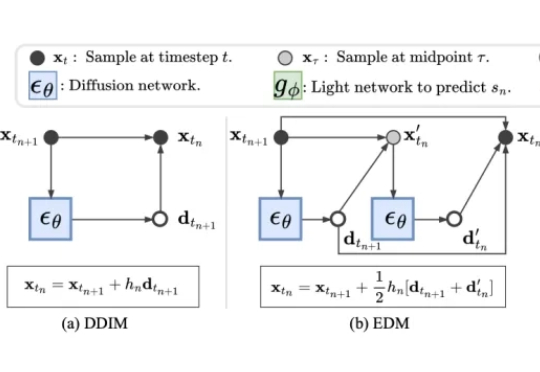
近年来,扩散模型(Diffusion Models)凭借出色的生成质量,迅速成为图像、视频、语音、3D 内容等生成任务中的主流技术。从文本生成图像(如 Stable Diffusion),到高质量人脸合成、音频生成,再到三维形状建模,扩散模型正在广泛应用于游戏、虚拟现实、数字内容创作、广告设计、医学影像以及新兴的 AI 原生生产工具中。
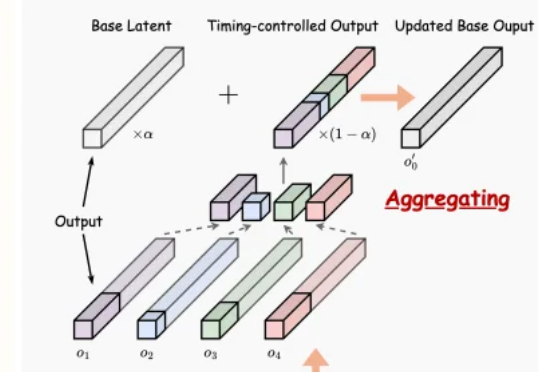
文生音频系统最新突破,实现精确时间控制与90秒长时音频生成!
AI 初创公司 Stability AI 发布了名为 Stable Audio Open Small 的“立体声”音频生成 AI 模型,该公司宣称这是市场上速度最快的模型,且效率高到足以在智能手机上运行。