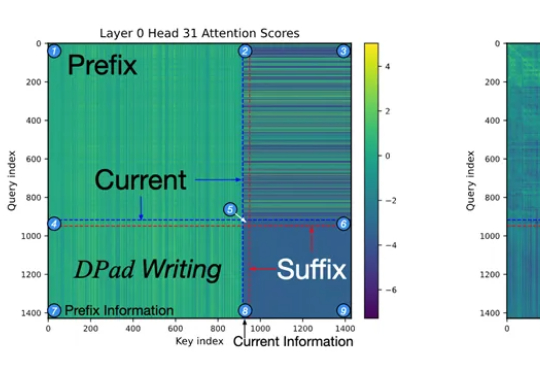
免训练加速61倍!陈怡然团队新作DPad:仅关注「彩票token」
免训练加速61倍!陈怡然团队新作DPad:仅关注「彩票token」杜克大学团队发现,扩散大语言模型只需关注少量「中奖」token,就能在推理时把速度提升61-97倍,还能让模型更懂格式、更听话。新策略DPad不训练也能零成本挑出关键信息,实现「少算多准」的双赢。
来自主题: AI技术研报
8719 点击 2025-09-28 09:51
 搜索
搜索
杜克大学团队发现,扩散大语言模型只需关注少量「中奖」token,就能在推理时把速度提升61-97倍,还能让模型更懂格式、更听话。新策略DPad不训练也能零成本挑出关键信息,实现「少算多准」的双赢。
「思维链劫持」(H-CoT)的攻击方法,成功攻破了包括OpenAI o1/o3、DeepSeek-R1等在内的多款大型推理模型的安全防线。研究表明,这些模型的安全审查过程透明化反而暴露了弱点,攻击者可以利用其内部推理过程绕过安全防线,使模型拒绝率从98%骤降2%。