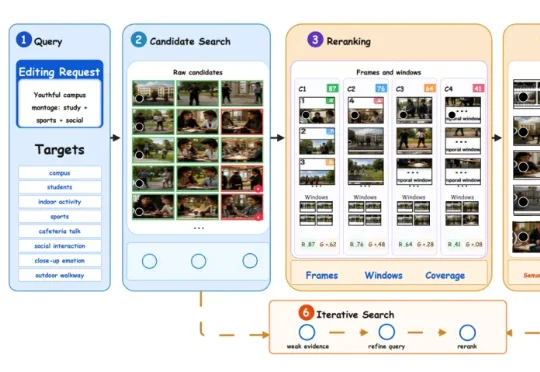
从“一句成片”到“长轨推演”:探究多模态智能体在长视频编辑中的应用
从“一句成片”到“长轨推演”:探究多模态智能体在长视频编辑中的应用近年来,大语言模型(LLMs)在长篇视觉叙事中展现出卓越潜力,生产方式正迅速从单一模型生成转向面向生产的智能体系统。但长视频剪辑仍然是一个极难控制的长期任务。模型有时会在缺乏素材依据的情况下强行生成,甚至在面对明显断档的转场或人物不一致时依然“盲目拼接”。
来自主题: AI技术研报
9831 点击 2026-06-21 10:41
 搜索
搜索
近年来,大语言模型(LLMs)在长篇视觉叙事中展现出卓越潜力,生产方式正迅速从单一模型生成转向面向生产的智能体系统。但长视频剪辑仍然是一个极难控制的长期任务。模型有时会在缺乏素材依据的情况下强行生成,甚至在面对明显断档的转场或人物不一致时依然“盲目拼接”。

随着视频生成技术的发展,模型正在从短视频片段合成,向流式长视频生成演进。然而,仅仅做到视觉上的逼真是不够的。一个功能完备的视频世界模型,必须能够在长时序交互中保持稳定的内部状态,并遵循真实世界的物理定律与逻辑规则。
京东首次开源长音视频生成框架JoyAI-Echo。它直击长视频生成中的角色一致性、声音稳定性和生成速度三大核心难题,一举在多个核心指标上超越行业标杆模型。根据公开评测结果,JoyAI-Echo在跨镜头一致性、语音准确率、用户偏好等关键指标上均取得领先表现,与业内主流长视频生成模型相比优势明显,出道即跻身全球第一梯队。
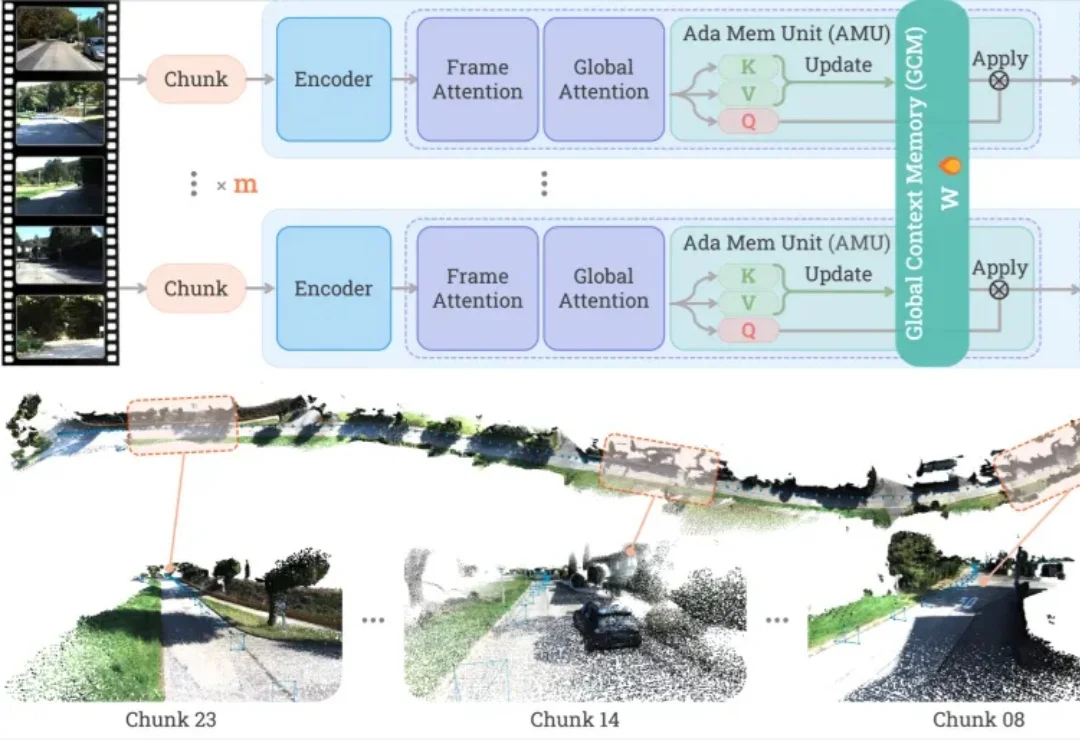
长视频 3D 重建最怕的,其实不是 "看不清"。
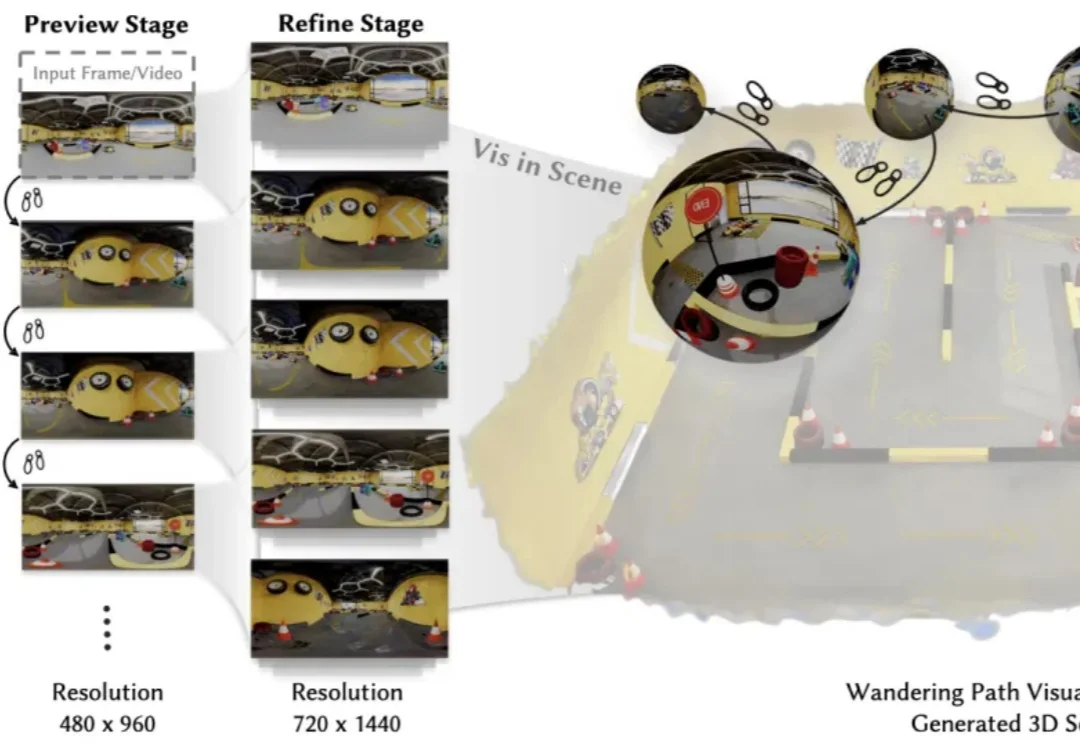
在生成式视频快速发展的今天,模型已经能够生成高质量的短视频片段,但一个更具挑战性的问题正逐渐成为研究焦点:
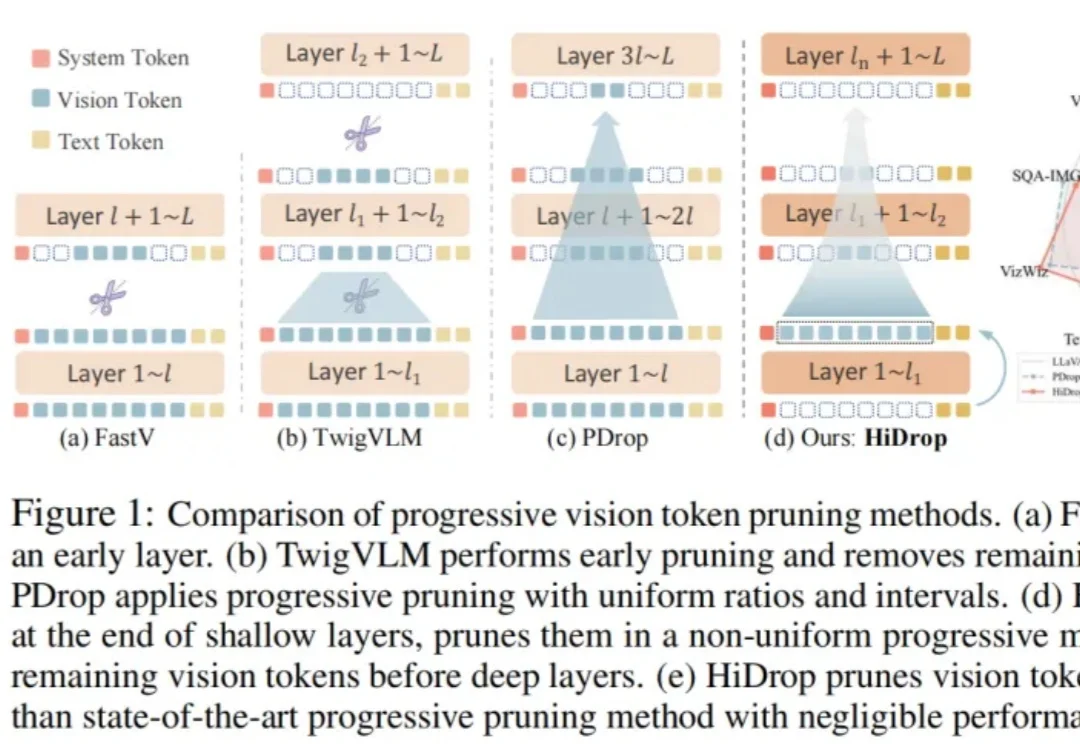
随着多模态大语言模型(MLLM)支持更长上下文,高分辨率图像和长视频会产生远多于文本的视觉 Token,在自注意力二次复杂度下迅速成为效率瓶颈。
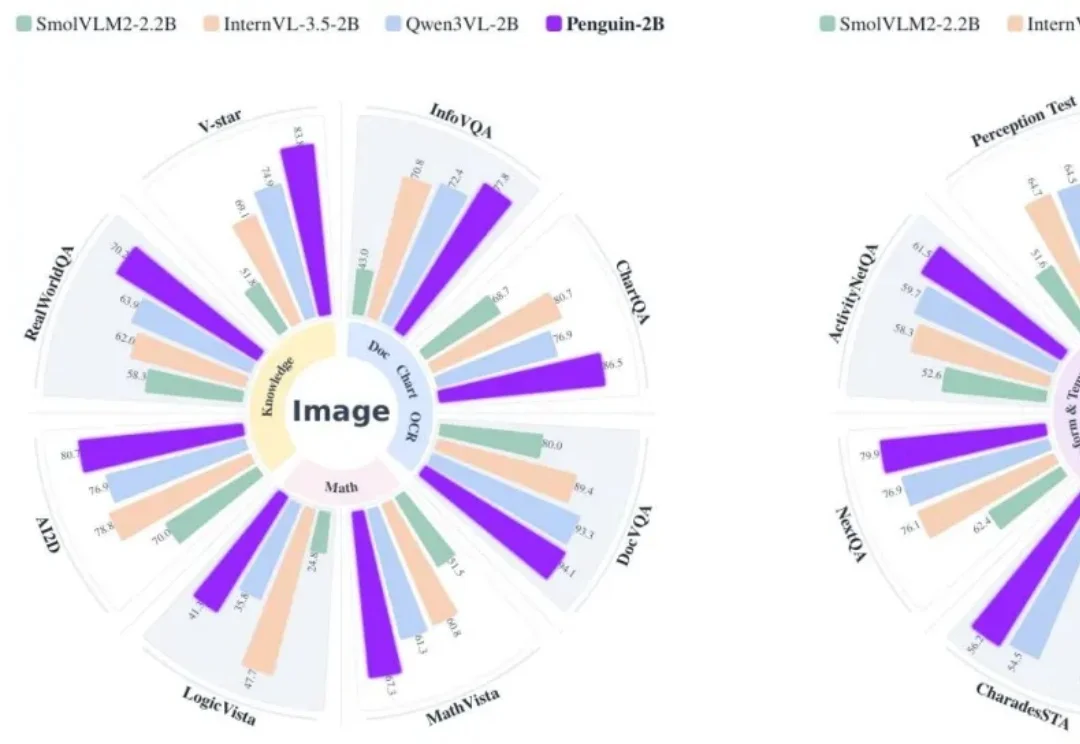
打破多模态视觉+语言拼接套路!

自回归视频生成越往后越崩的问题有救了!
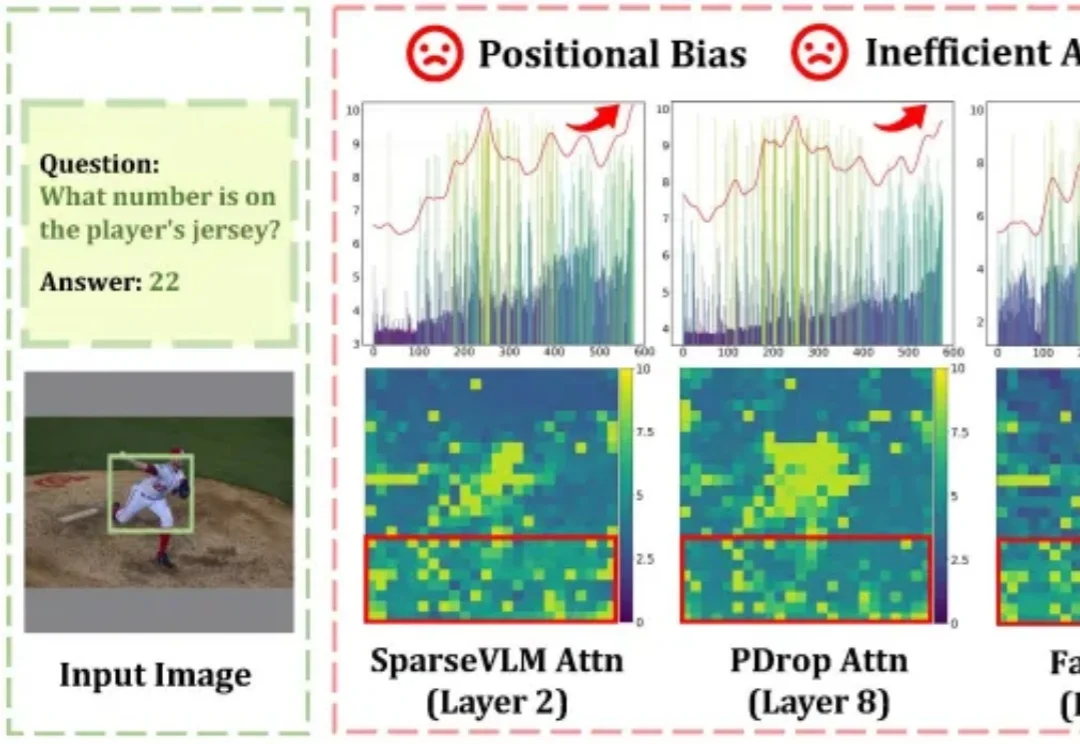
随着高分辨率图像理解与长视频处理需求的爆发式增长,大型视觉语言模型(LVLMs)所需处理的视觉 Token 数量急剧膨胀,推理效率成为落地部署的核心瓶颈。Token 压缩是缩短序列、提升吞吐的直接手段,但现有方法普遍依赖注意力权重来判断 Token 重要性,这一路线暗藏两个致命缺陷:
近年来多模态大模型在视觉感知,长视频问答等方面涌现出了强劲的性能,但是这种跨模态融合也带来了巨大的计算成本。高分辨率图像和长视频会产生成千上万个视觉 token ,带来极高的显存占用和延迟,限制了模型的可扩展性和本地部署。