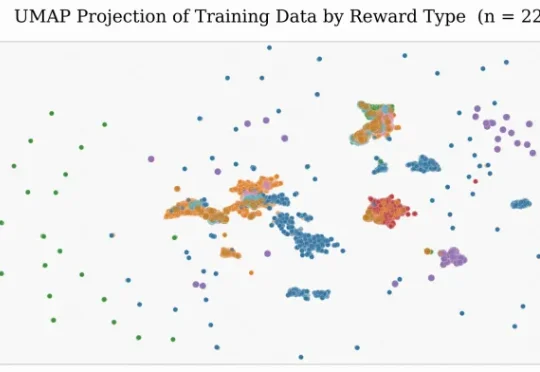
快手开源GoLongRL:23K样本、9大任务类型,长上下文RL荒的时代结束了
快手开源GoLongRL:23K样本、9大任务类型,长上下文RL荒的时代结束了本研究由快手科技语言大模型团队完成,核心作者吕民轩、梅铁桦、杜坦隆等。快手科技与中国科学院大学联合提出 GoLongRL,一套完全开源的长上下文强化学习后训练方案,包含 23K 样本 RLVR 数据集
来自主题: AI技术研报
7600 点击 2026-06-20 10:21
 搜索
搜索
本研究由快手科技语言大模型团队完成,核心作者吕民轩、梅铁桦、杜坦隆等。快手科技与中国科学院大学联合提出 GoLongRL,一套完全开源的长上下文强化学习后训练方案,包含 23K 样本 RLVR 数据集

全模态算力狂欢开启:全球前十AI巨头无限期免费API,周调用爆破3.12万亿Token!本周Agnes的王炸升级了:1M超长上下文+4K超清画质「零成本」白嫖,开源社区已玩疯,独立开发者和小团队速来薅秃!

我们在上周五开源了 MiniMax M3 模型权重,同步发布了 MSA(MiniMax Sparse Attention)技术论文。MSA 的架构设计让 M3 在长上下文下的计算成本大幅降低,论文中完整披露了架构与工程实现细节。
今天,月之暗面发布并开源Kimi K2.7 Code编程模型,参数量达1.1万亿,提供256K上下文窗口。这一模型重点提升了长上下文编程场景的指令遵循能力、长程编程任务的性能表现,并且大幅改善了在长程任务中的过度思考倾向,平均token消耗减少30%。

多模态长记忆在“看得准、找得到、想得清”三大环节的底层逻辑与工程避坑指南。

长上下文模型越来越能“记”,但真正让它们跑到线上时,最先顶不住的往往不是算力,而是KV Cache。

2026 年初,各大 AI 厂商在上下文窗口长度上展开激烈角逐。Google 的 Gemini 3 Pro 已支持 100 万级 token 上下文,Meta 的 Llama 4 Scout 更宣称可处理 1000 万 token。GPT-5 系列也在快速推进长上下文能力。

MiniMax M3 今日正式发布。MiniMax M3 在编程和智能体等专业任务上达到了前沿的能力。它使用了我们提出的全新注意力架构 MSA (MiniMax Sparse Attention),最高支持 1M 超长上下文。如外界所期待的那样,它也是一个原生多模态模型,支持图片和视频的输入,并能操作电脑桌面。

Claude深陷「角色混淆」Bug,分不清自己的话与用户指令,长上下文成了降智「重灾区」。

今天,我们全新系列模型 DeepSeek-V4 的预览版本正式上线并同步开源。DeepSeek-V4 拥有百万字超长上下文,在 Agent 能力、世界知识和推理性能上均实现国内与开源领域的领先。模型按大小分为两个版本: