
正在升温的 Voice AI 赛道,出现了一家初创团队 Hojo
正在升温的 Voice AI 赛道,出现了一家初创团队 Hojo当所有人都在盯着通用大模型时,Voice AI 这条相对安静的赛道里,也开始出现一些值得注意的新模型。最近,一家名为 Hojo 的创业团队公开披露了一组语音识别测试结果,似乎有成为「黑马」的趋势。
来自主题: AI资讯
10398 点击 2026-06-10 20:07
 搜索
搜索
当所有人都在盯着通用大模型时,Voice AI 这条相对安静的赛道里,也开始出现一些值得注意的新模型。最近,一家名为 Hojo 的创业团队公开披露了一组语音识别测试结果,似乎有成为「黑马」的趋势。

Mindverse 完成由美团领投的 A 轮融资,元禾璞华、韶音、变量资本和老股东追加跟投。Mindverse (心洲科技) 是少数把赌注押在模型「内部」的一家创企,它在通用大模型的基础上,用强化学习让它从复杂、多步骤的真实任务中学会如何把事做成,让模型从「知道很多」变为「能办好事」。
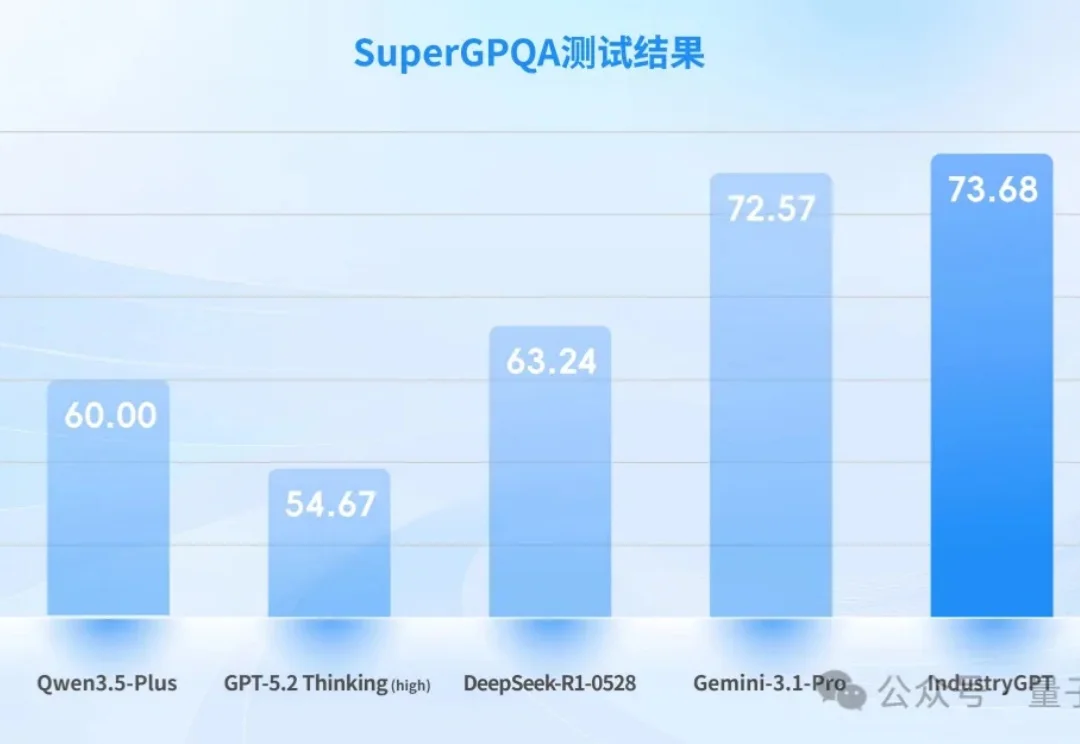
最近,一批顶级通用大模型参加了三场特殊的“工业执业考试”。
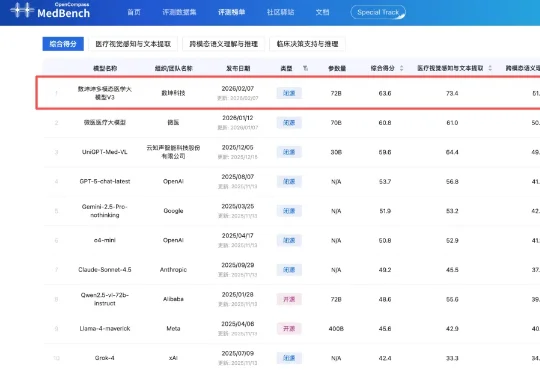
2月7日,中文医疗大模型评测平台MedBench公布最新多模态大模型评测榜单,数坤科技的数坤坤多模态医学大模型V3以63.6分拿下第一。在榜单中,V3的表现超过微医、云知声旗下医疗行业大模型,以及OpenAI、谷歌、阿里千问旗下通用大模型。

外网都在好奇: 全球模型服务平台 OpenRouter 上这个搜索第一的神秘模型是哪家的? 这个匿名模型叫做「Pony Alpha」。根据 OpenRouter 官方的说法,它是新一代的通用大模型,在编程、逻辑推理和角色扮演方面表现突出,并针对 Agent 工作流进行了优化,具有极高的工具调用准确率。

岁末年初,全球AI竞争聚焦到了最新趋势—— 太空算力。

1月10日,很久没有公开露面的月之暗面创始人杨植麟,在一场定向邀请的行业论坛中,详细地分享了2025年Kimi的技术路线重点,以及对未来的思考。这次分享,有一个核心关键词,Agentic智能时代。这是通用大模型竞争的一个未来高地

本文为《2025 年度盘点与趋势洞察》系列内容之一,由 InfoQ 技术编辑组策划。本系列覆盖大模型、Agent、具身智能、AI Native 开发范式、AI 工具链与开发、AI+ 传统行业等方向,通过长期跟踪、与业内专家深度访谈等方式,对重点领域进行关键技术进展、核心事件和产业趋势的洞察盘点。

2025 年,随着李飞飞等学者将 “空间智能”(Spatial Intelligence)推向聚光灯下,这一领域迅速成为了大模型竞逐的新高地。通用大模型和各类专家模型纷纷在诸多室内空间推理基准上刷新 SOTA,似乎 AI 在训练中已经更好地读懂了三维空间。

通用大模型(LLM)的狂飙突进,终于在医疗垂直领域的「最后一公里」撞上了硬墙。虽然 ChatGPT 在 USMLE(美国执业医师资格考试)中表现优异,但在面对需要「火眼金睛」和「毫厘必争」的心脏手术台上,通用大模型的表现究竟如何?