始末|通义、千问、Qwen、Qwen Chat 的来龙去脉
始末|通义、千问、Qwen、Qwen Chat 的来龙去脉今天,通义改名千问
来自主题: AI资讯
12832 点击 2025-11-20 14:51
 搜索
搜索
今天,通义改名千问
智能体自进化,阿里开源了新成果。
昨天,阿里的千问APP,在应用商店里。终于悄悄上线了。从之前的通义APP的双色渐变,变成了现在的属于千问的单色。功能增加了很多,模型也支持了Qwen全系列最新模型。
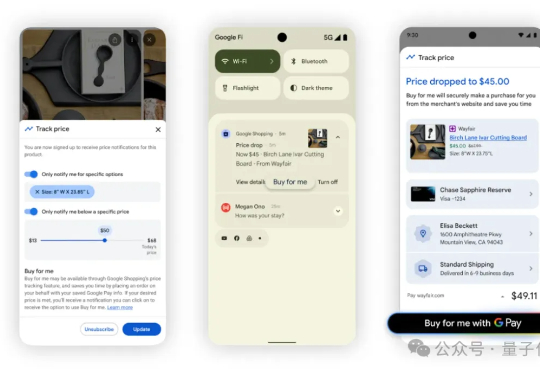
先是彭博社等多家媒体爆料,对标ChatGPT、Gemini,阿里即将对通义APP进行全面改革,而且计划第一步就是将“通义”更名为“Qwen”。谷歌也在今日出手,直接把战火烧到了阿里的电商主场。谷歌宣布推出全新AI购物功能,允许用户直接使用AI浏览商品、拨打电话咨询店铺,甚至完成一键结账。
智东西10月15日报道,今日,阿里通义千问团队推出其最强视觉语言模型系列Qwen3-VL的4B与8B版本,两个尺寸均提供Instruct与Thinking版本,在几十项权威基准测评中超越Gemini 2.5 Flash Lite、GPT-5 Nano等同级别顶尖模型。
近期,我们独家观察到,国内两家科技巨头——阿里巴巴和字节跳动——旗下的AI助手通义千问(Qwen)和豆包(Doubao),同时开始内测“记忆功能”。此举被广泛视为对标行业领头羊OpenAI的ChatGPT,标志着国产AI助手正从“即时问答工具”向“长期私人助理”的角色加速演进。

昨天,阿里通义千问大语言模型负责人林俊旸在社交媒体上官宣,他们在 Qwen 内部组建了一个小型机器人、具身智能团队,同时表示「多模态基础模型正转变为基础智能体,这些智能体可以利用工具和记忆通过强化学习进行长程推理,它们绝对应该从虚拟世界走向物理世界」。

据“互联网八卦小喇叭”等媒体爆料,全球顶尖AI科学家、IEEE Fellow许主洪(Steven Hoi)已加盟阿里通义,转向通义大模型的相关研发工作。许主洪拥有超20年AI产业和学术经验,是新加坡管理大学终身教授、曾任新加坡南洋理工大学终身副教授,在AI领域发表了300多篇顶级学术论文,

这年头出门逛展,中国厂商真的是把排面拉爆了。比如火热进行中的东京电玩展(TGS),现场是这样的:一眼AI含量爆棚的,当属阿里展台——通义千问和通义万相两个开源界当红炸子鸡,妥妥C位出展。
Veo 3真正对手,竟不是Sora 2!通义万相2.5全网首发,直接甩出王炸:一句话,直出10秒1080P电影级视频,首次实现音画精准同步。一键生成BGM、人声,全网实测玩疯。