LeCun、谢赛宁转发的世界模型与VLA共融方案:中关村学院ECCV2026—VLA-JEPA
LeCun、谢赛宁转发的世界模型与VLA共融方案:中关村学院ECCV2026—VLA-JEPA依赖于有限机器人数据和大量人类数据,也能让 VLA 模型更稳健吗?
来自主题: AI技术研报
5724 点击 2026-06-24 10:30
 搜索
搜索
依赖于有限机器人数据和大量人类数据,也能让 VLA 模型更稳健吗?

即将结束博士生涯的童晟邦,正站在另一个起点上。
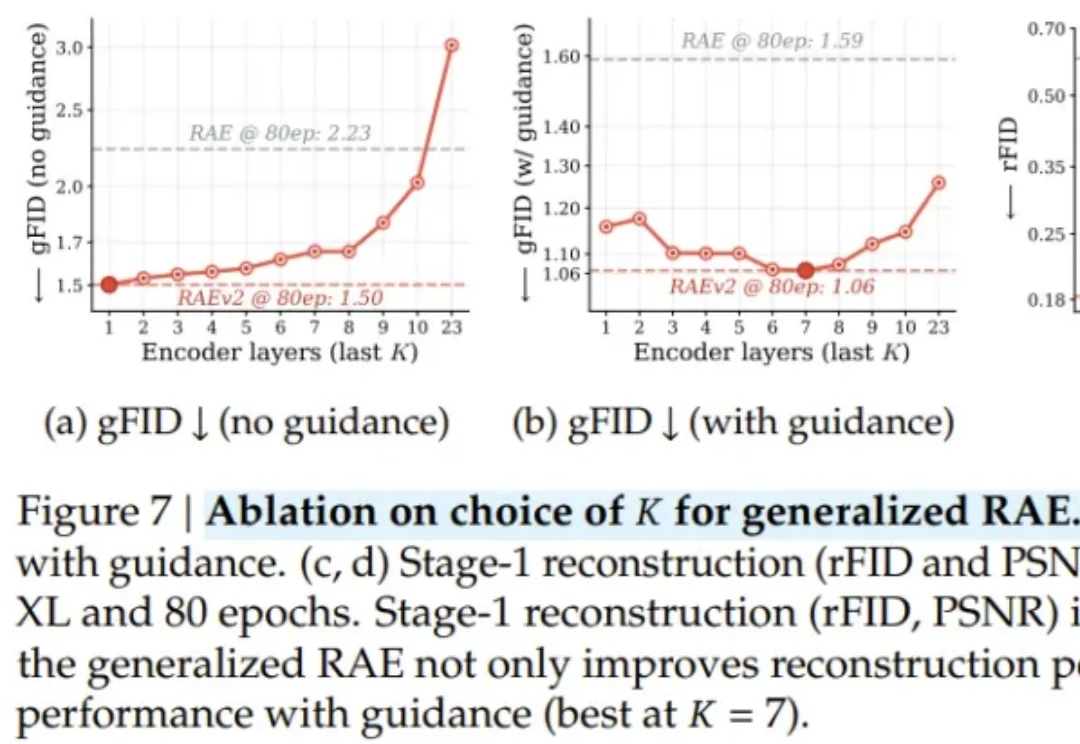
AI 图像生成通常遵循「能力越强、代价越高」的铁律;与此同时,学界却在悄悄质疑另一个更根本的浪费:传统 VAE 对图像语义几乎一无所知,而 DINOv2、SigLIP 等视觉编码器早已从数亿张图片中习得了丰富的视觉常识。图像生成模型,真的需要从零开始「发明」对图像的理解吗?

最近,谷歌联合ResNet作者何恺明、谢赛宁、NeRF先驱Jonathan T. Barron、 3D图形学名家Thomas Funkhouser,正式发布了Vision Banana。它向世界宣告:视觉AI终于不再需要那些臃肿的任务头了,理解,本质上只是生成过程中的一次「对齐」。

在当前的 LLM 开发中,后训练阶段通常被视为赋予模型特定能力的关键环节。传统的观点认为,模型必须通过强化学习(如 PPO、GRPO 或 RLHF)和进化策略(ES)等算法,在反复的迭代和梯度优化过程中调整权重,才能在特定任务上达到理想的性能。

近年来,大规模视频扩散模型在视频生成领域取得了显著进展。然而,采样效率低下仍然是这类模型的核心瓶颈。

3 月 10 日,APPSO 中文独家获悉,世界模型研究所/创业公司 AMI 已完成 10.3 亿美元融资,投前估值 35 亿美元。该公司由图灵奖得主、前 Meta 首席 AI 科学家杨立昆 (Yann LeCun) 创办。

基础模型时代,大模型能力的爆发,很大程度上源于在海量文本上的预训练。然而问题在于,文本本质上只是人类对现实世界的一种抽象表达,是对真实世界信息的有损压缩。
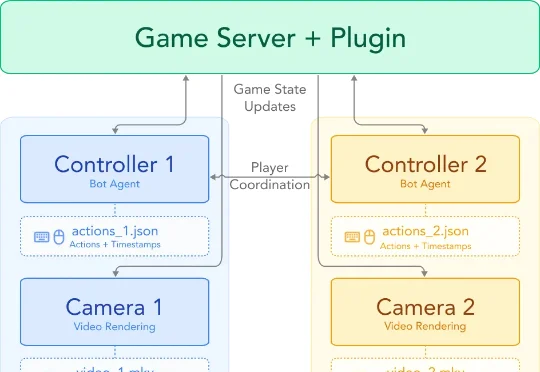
谢赛宁团队的最新视频世界模型 Solaris,首个多人视频世界模型,能够同时生成多个玩家之间保持一致的第一视角。研究团队发现,目前的视频世界模型仅能处理单人视角,这并不能反映现实世界的真实运作方式,希望能够能够实现多人同步观察一个统一世界。于是,研究团队把视角投向了电子游戏。
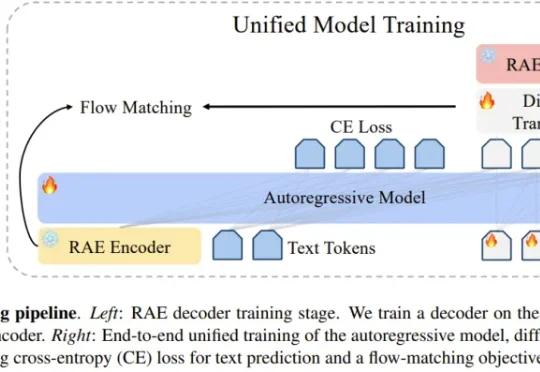
编辑|Panda 在文生图模型的技术版图中,VAE 几乎已经成为共识。从 Stable Diffusion 到 FLUX,再到一系列扩散 Transformer,主流路线高度一致:先用 VAE 压缩视