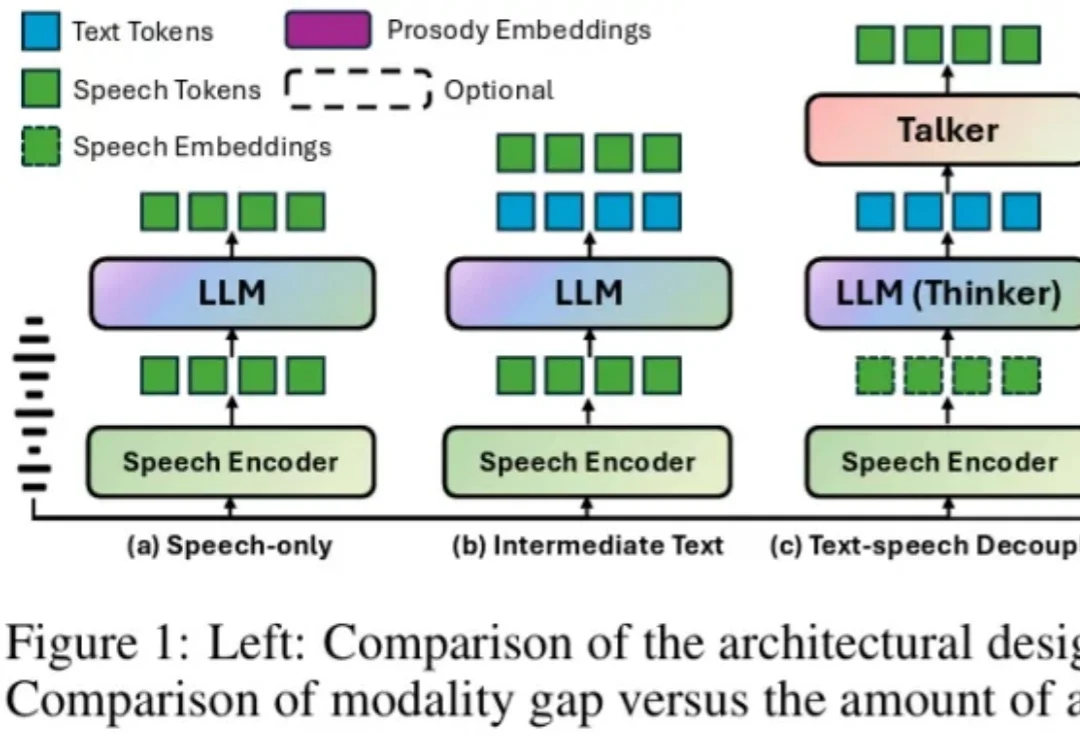
Speech LLM 的下一个突破口:你的语音大模型可以是个「带韵律的文本模型」
Speech LLM 的下一个突破口:你的语音大模型可以是个「带韵律的文本模型」相信大家都有过这样的体验:同一个系列的模型,使用文本交互的时候,模型就像开启了 “最强大脑”,数学代码等各种复杂推理任务样样精通,可是一旦将其改造成语音对话模型之后,性能就猛烈下降,严重 “降智”,经常会犯很多基本的逻辑错误。
来自主题: AI技术研报
6135 点击 2026-05-28 14:51
 搜索
搜索
相信大家都有过这样的体验:同一个系列的模型,使用文本交互的时候,模型就像开启了 “最强大脑”,数学代码等各种复杂推理任务样样精通,可是一旦将其改造成语音对话模型之后,性能就猛烈下降,严重 “降智”,经常会犯很多基本的逻辑错误。

AI交互的「机械感」消失了!今天,豆包甩出原生全双工语音大模型Seeduplex,不仅能边听边说,甚至能听懂你在思考时的「卡壳」,就算环境再吵也不怕,抗干扰能力直接拉满。
VUI Labs(宇生月伴)宣布完成数千万元天使+轮融资。本轮投资由同创伟业领投、老股东靖亚资本、小苗朗程持续加注,心流资本FlowCapital担任长期财务顾问。公司半年累计获得近亿元投资,所募资金
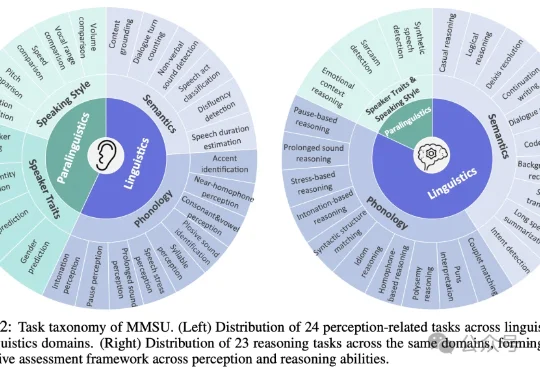
随着多模态大模型能力不断扩展,语音大模型(SpeechLLMs) 已从语音识别走向复杂语音交互。然而,当模型逐渐进入真实口语交互场景,一个更基础的问题浮现出来:我们是否真正定义清楚了「语音理解」的能力边界?
小红书智创音频团队推出业内首个支持私有化部署的全双工大模型语音交互系统 FireRedChat,自研流式 pVAD 与 EoT 让语音交互更加自然,首发级联与半级联两套实现,端到端时延逼近工业级应用。
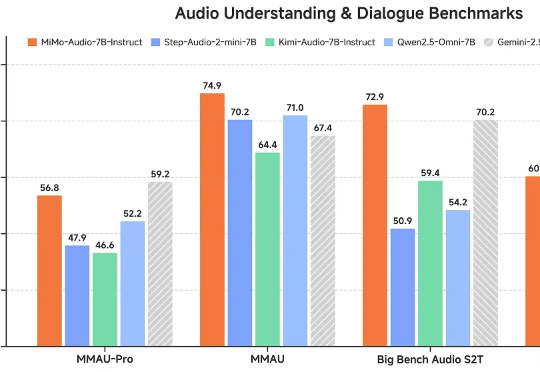
这一瓶颈如今被打破。小米正式开源首个原生端到端语音模型——Xiaomi-MiMo-Audio,它基于创新预训练架构和上亿小时训练数据,首次在语音领域实现基于 ICL 的少样本泛化,并在预训练观察到明显的“涌现”行为。

北京深度逻辑智能科技有限公司推出了 LLaSO—— 首个完全开放、端到端的语音语言模型研究框架。LLaSO 旨在为整个社区提供一个统一、透明且可复现的基础设施,其贡献是 “全家桶” 式的,包含了一整套开源的数据、基准和模型,希望以此加速 LSLM 领域的社区驱动式创新。

情感语音交互模型初创公司宇生月伴近日完成新一轮融资,由靖亚资本和小苗朗程领投,菡源资产(上海交大母基金)跟投,心流资本FlowCapital担任长期财务顾问。本轮融资将用于语音模型的持续优化、产品矩阵拓展及国际化商业落地。作为国内首家聚焦“情感语音交互”的模型公司,宇生月伴正重新定义AI时代的语音交互范式。
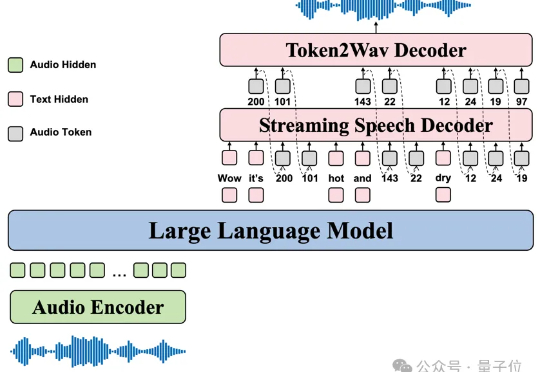
GPT-4o、Gemini这些顶级语音模型虽然展现了惊人的共情对话能力,但它们的技术体系完全闭源。
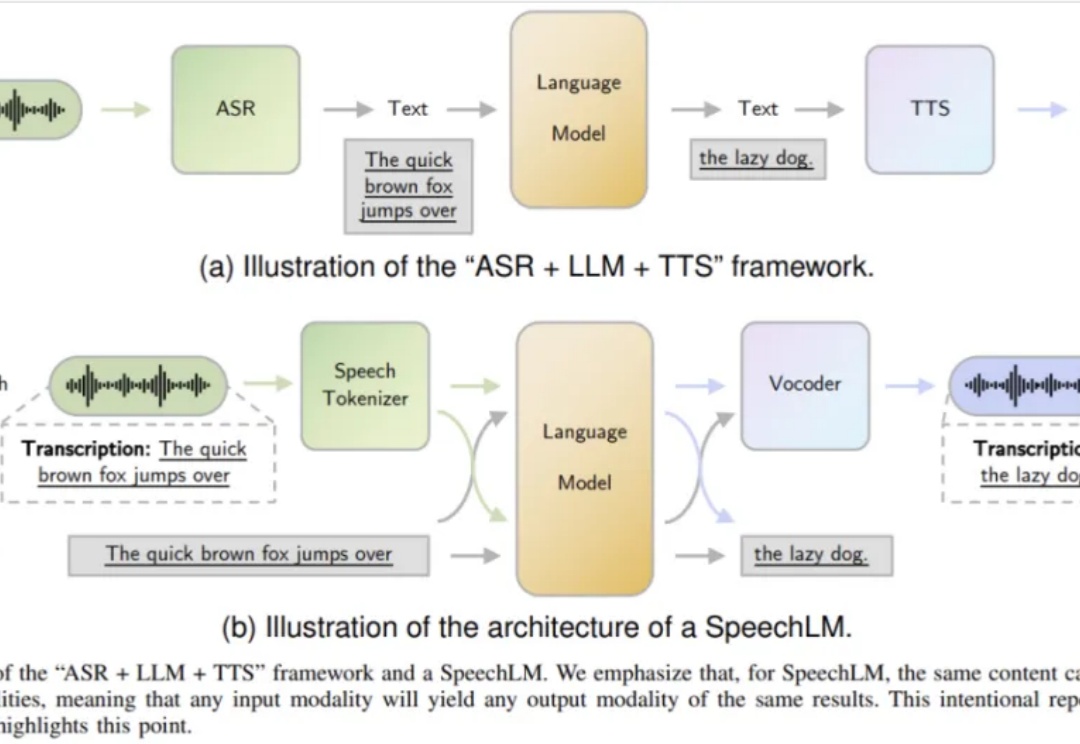
由香港中文大学团队撰写的语音语言模型综述论文《Recent Advances in Speech Language Models: A Survey》已成功被 ACL 2025 主会议接收!这是该领域首个全面系统的综述,为语音 AI 的未来发展指明了方向。