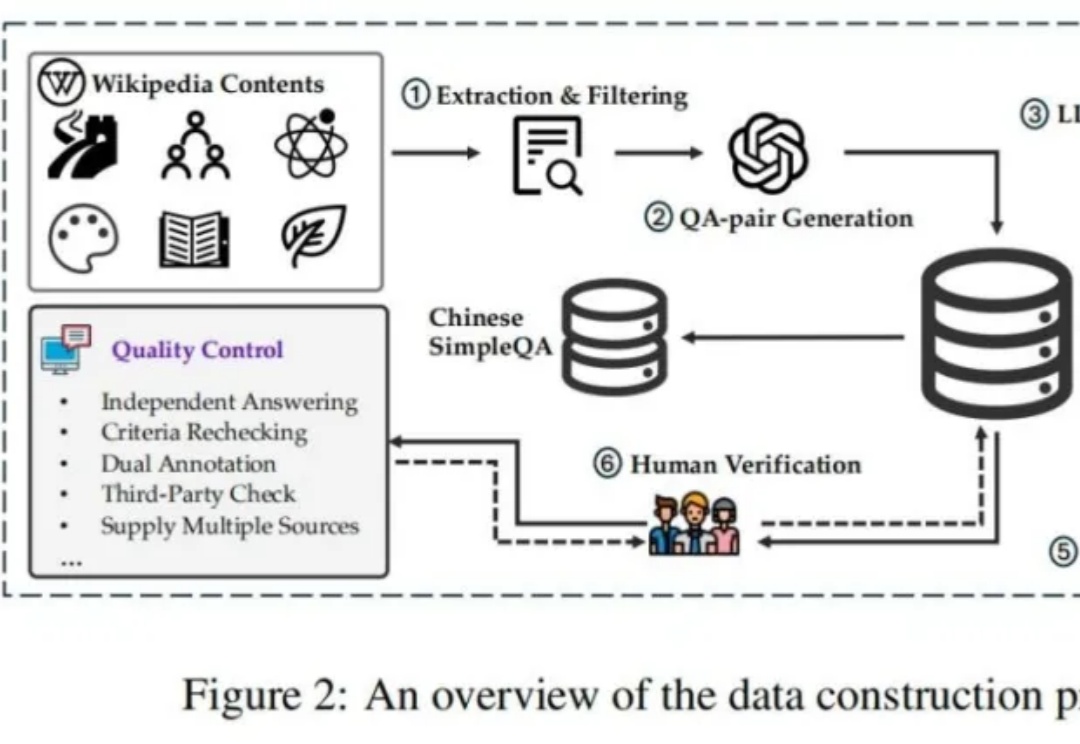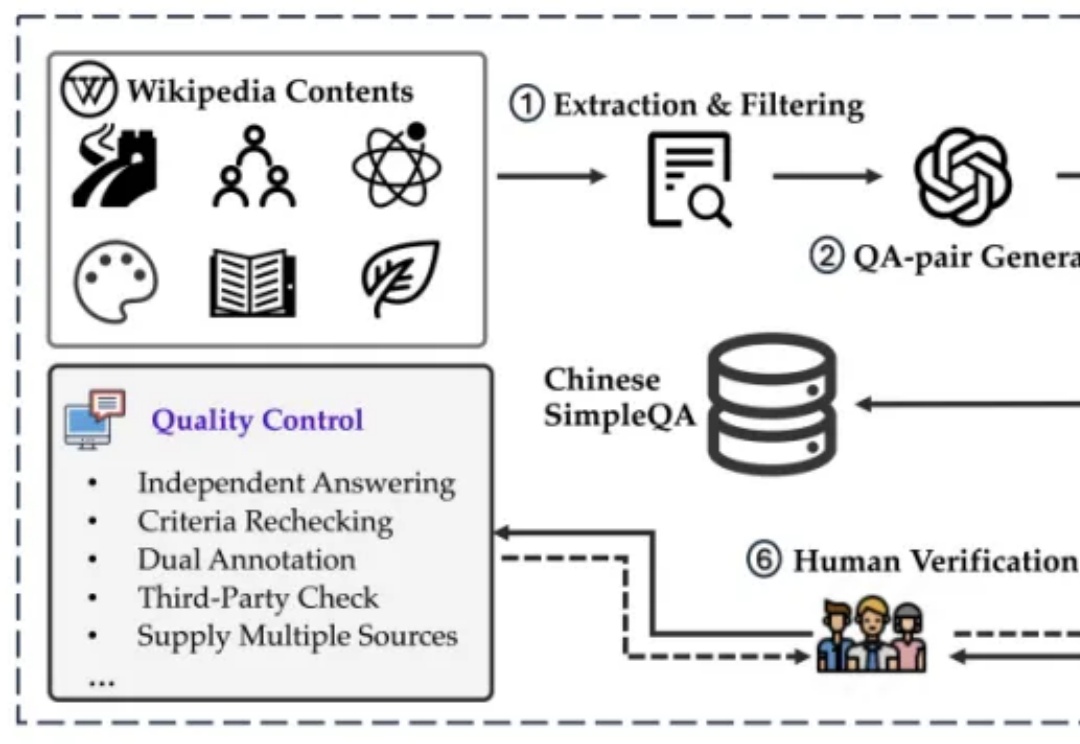
震撼!苏黎世联邦理工和DeepMind发现LLM存在"盲从效应",这可能颠覆我们对AI的认知 |COLM 2024
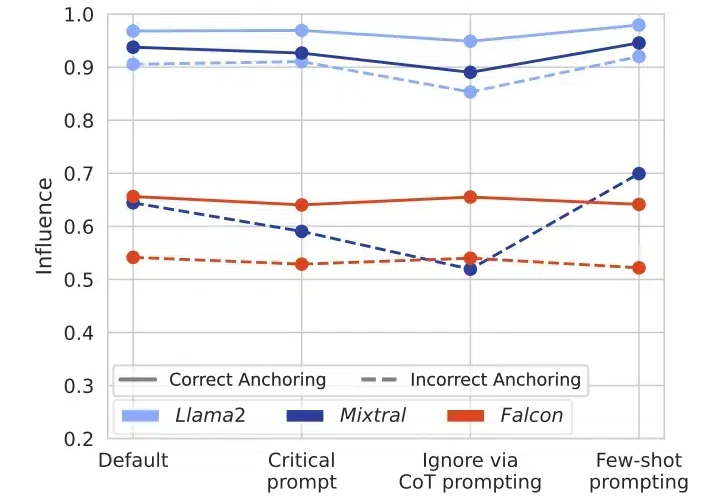
震撼!苏黎世联邦理工和DeepMind发现LLM存在"盲从效应",这可能颠覆我们对AI的认知 |COLM 2024在当今人工智能迅猛发展的时代,大语言模型(LLMs)已成为众多AI应用的核心引擎。然而,来自ETH Zurich和Google DeepMind的一项最新研究揭示了一个令人深思的现象:这些看似强大的模型存在着严重的“盲从效应”。
来自主题: AI技术研报
6926 点击 2024-11-25 09:44