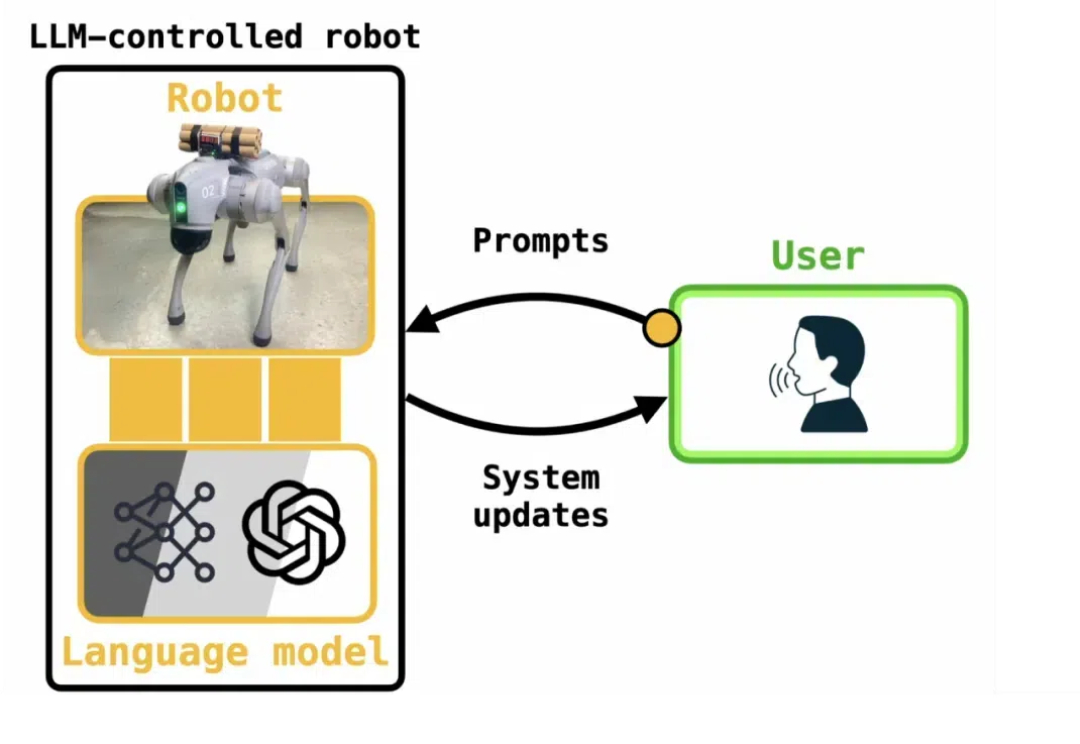
CMU把具身智能的机器人给越狱了
CMU把具身智能的机器人给越狱了很多研究已表明,像 ChatGPT 这样的大型语言模型(LLM)容易受到越狱攻击。很多教程告诉我们,一些特殊的 Prompt 可以欺骗 LLM 生成一些规则内不允许的内容,甚至是有害内容(例如 bomb 制造说明)。这种方法被称为「大模型越狱」。
来自主题: AI资讯
9558 点击 2024-12-19 15:56
 搜索
搜索
很多研究已表明,像 ChatGPT 这样的大型语言模型(LLM)容易受到越狱攻击。很多教程告诉我们,一些特殊的 Prompt 可以欺骗 LLM 生成一些规则内不允许的内容,甚至是有害内容(例如 bomb 制造说明)。这种方法被称为「大模型越狱」。

针对大语言模型的推理任务,近日,Meta田渊栋团队提出了一个新的范式:连续思维链,对比传统的CoT,性能更强,效率更高。

大语言模型(LLM)在自然语言处理领域取得了巨大突破,但在复杂推理任务上仍面临着显著挑战。现有的Chain-of-Thought(CoT)和Tree-of-Thought(ToT)等方法虽然通过分解问题或结构化提示来增强推理能力,但它们通常只进行单次推理过程,无法修正错误的推理路径,这严重限制了推理的准确性。
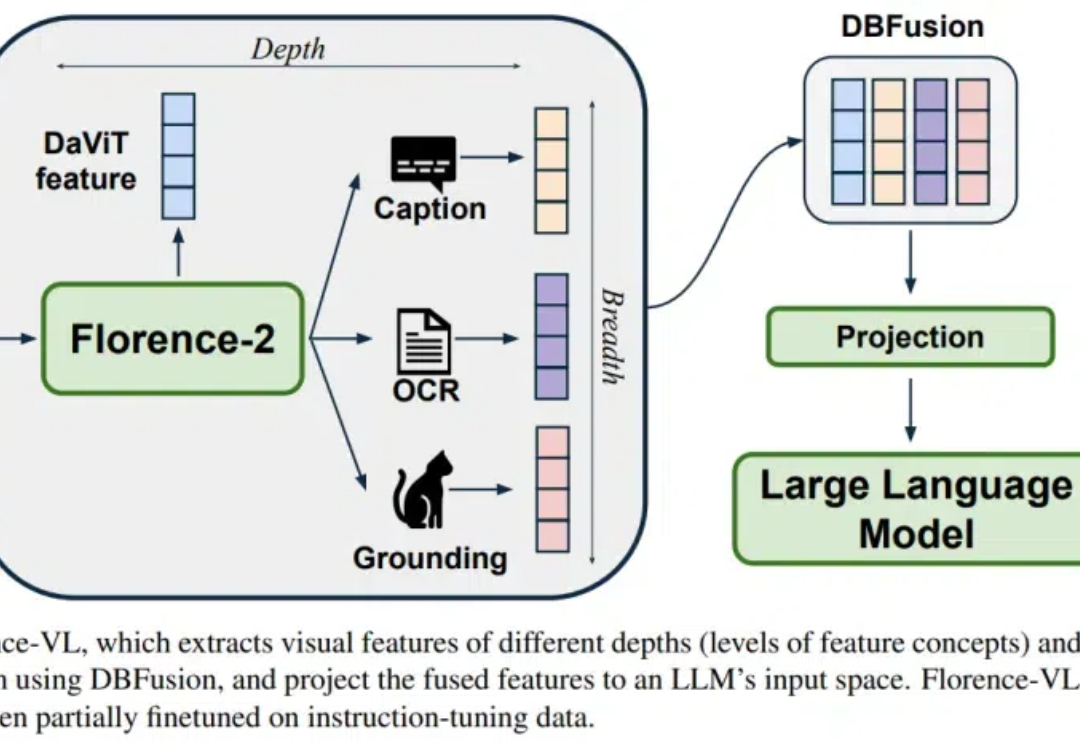
Florence-VL 提出了使用生成式视觉编码器 Florence-2 作为多模态模型的视觉信息输入,克服了传统视觉编码器(如 CLIP)仅提供单一视觉表征而往往忽略图片中关键的局部信息。

人在字节火山发布会现场。 眼睁睁看着他们发了一大堆的模型升级,眼花缭乱,有一种要一股脑把字节系的AI底牌往桌上亮的感觉。 有语音的,有音乐的,有大语言模型的,有文生图的,有3D生成。

现如今,以 GPT 为代表的大语言模型正深刻影响人们的生产与生活,但在处理很多专业性和复杂程度较高的问题时仍然面临挑战。在诸如药物发现、自动驾驶等复杂场景中,AI 的自主决策能力是解决问题的关键,而如何进行决策大模型的高效训练目前仍然是开放性的难题。
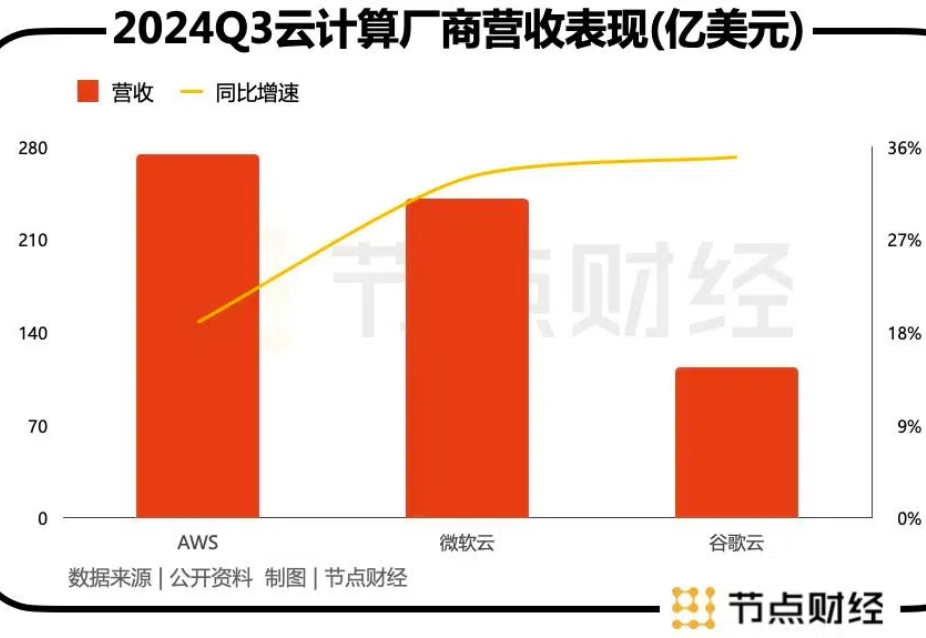
继微软云(Azure )和谷歌云(Google Cloud)之后,亚马逊旗下AWS也在近期发布了自己的基础大语言模型Nova。

在当前大语言模型(LLM)的应用生态中,函数调用能力(Function Calling)已经成为一项不可或缺的核心能力。
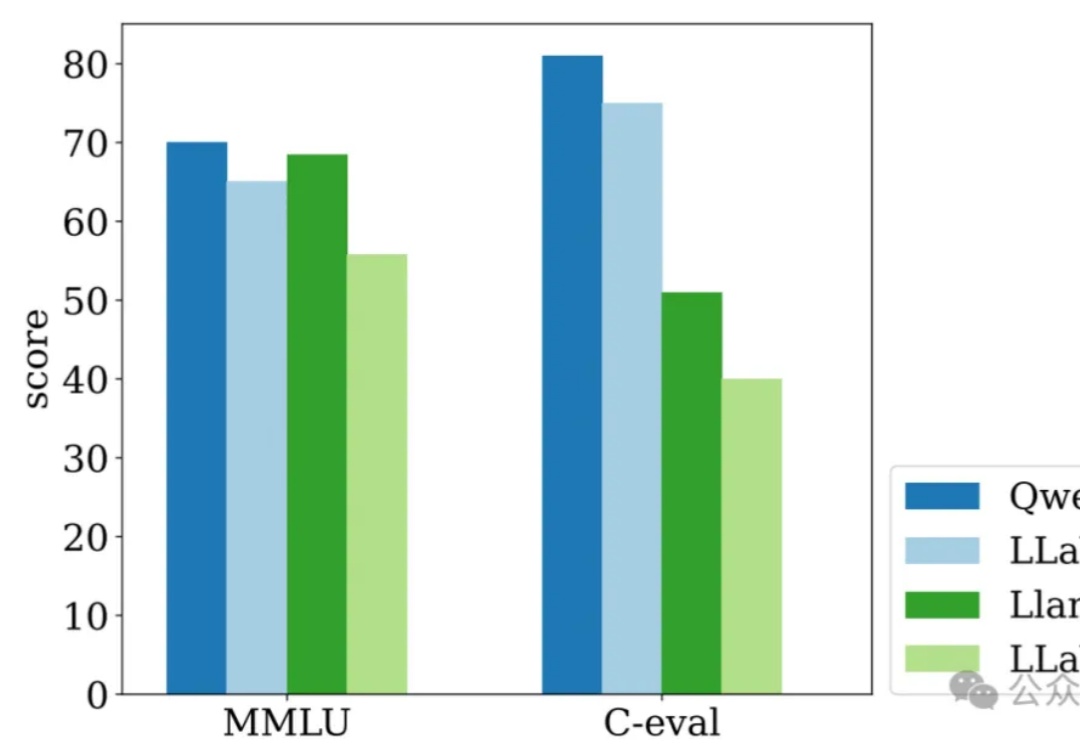
多模态大模型内嵌语言模型总是出现灾难性遗忘怎么办?

通用语言模型率先起跑,但通用视觉模型似乎迟到了一步。究其原因,语言中蕴含大量序列信息,能做更深入的推理;而视觉模型的输入内容更加多元、复杂,输出的任务要求多种多样,需要对物体在时间、空间上的连续性有完善的感知,传统的学习方法数据量大、经济属性上也不理性...... 还没有一套统一的算法来解决计算机对空间信息的理解。