GPT 5/o3欠拟合与过拟合详细分析与深度思考(三万字超长洞察,慎入)
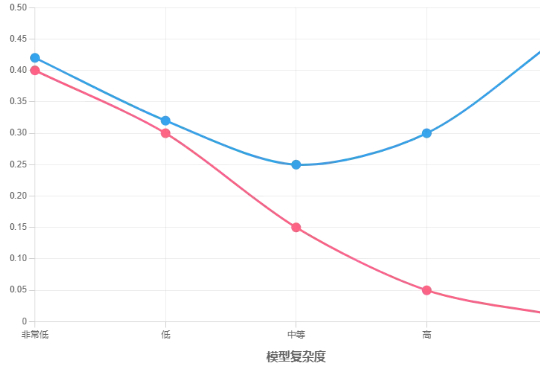
GPT 5/o3欠拟合与过拟合详细分析与深度思考(三万字超长洞察,慎入)当模型复杂度增加到一定程度后,模型开始对训练数据中的噪声和异常值进行拟合,而不是仅仅学习数据中的真实模式。这导致模型在训练数据上表现得非常好,但在新的数据上表现不佳,因为新的数据中噪声和异常值的分布与训练数据不同。
来自主题: AI技术研报
12669 点击 2025-03-06 23:31
 搜索
搜索
当模型复杂度增加到一定程度后,模型开始对训练数据中的噪声和异常值进行拟合,而不是仅仅学习数据中的真实模式。这导致模型在训练数据上表现得非常好,但在新的数据上表现不佳,因为新的数据中噪声和异常值的分布与训练数据不同。
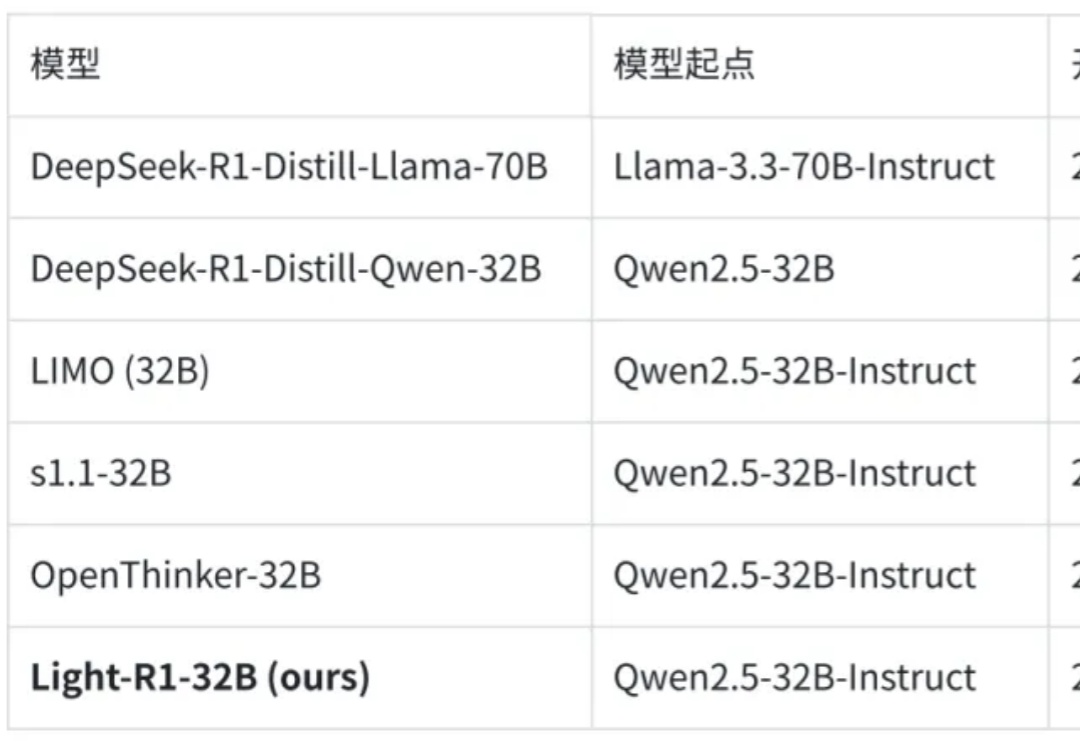
2025 年 3 月 4 日,360 智脑开源了 Light-R1-32B 模型,以及全部训练数据、代码。仅需 12 台 H800 上 6 小时即可训练完成,从没有长思维链的 Qwen2.5-32B-Instruct 出发,仅使用 7 万条数学数据训练,得到 Light-R1-32B

基于内置思维链的思考方法为解决多轮会话中存在的问题提供了研究方向。按照思考方法收集训练数据集,通过有监督学习微调大语言模型;训练一个一致性奖励模型,并将该模型用作奖励函数,以使用强化学习来微调大语言模型。结果大语言模型的推理能力和计划能力,以及执行计划的能力得到了增强。

在 DeepSeek 生成的文本中,有 74.2% 的文本在风格上与 OpenAI 模型具有惊人的相似性?这是一项新研究得出的结论。这项研究来自 Copyleaks—— 一个专注于检测文本中的抄袭和 AI 生成内容的平台。
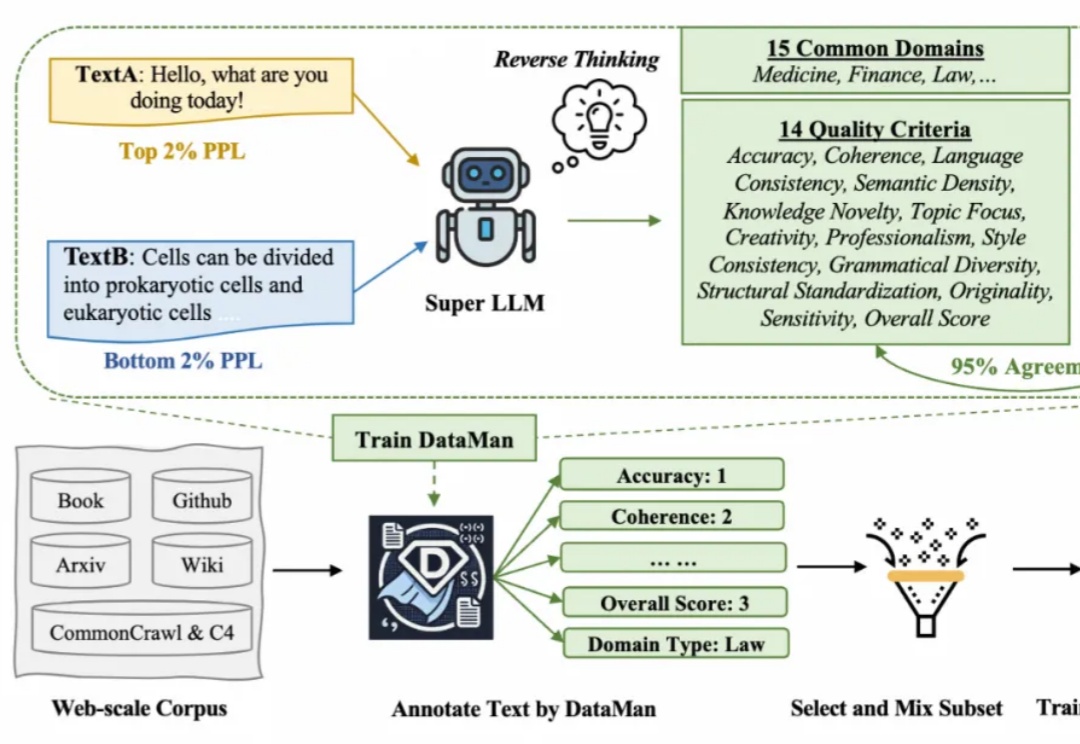
在 Scaling Law 背景下,预训练的数据选择变得越来越重要。然而现有的方法依赖于有限的启发式和人类的直觉,缺乏全面和明确的指导方针。在此背景下,该研究提出了一个数据管理器 DataMan,其可以从 14 个质量评估维度对 15 个常见应用领域的预训练数据进行全面质量评分和领域识别。
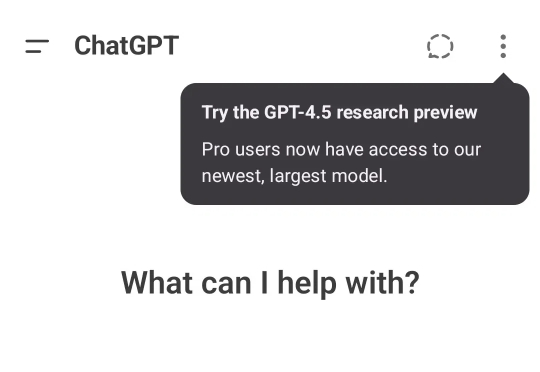
嚯,万众期待的GPT-4.5,本周就要空降发布?!部分用户的ChatGPT安卓版本(1.2025.056 测试版)上,已经出现了“GPT-4.5研究预览(GPT-4.5 research preview)”的字样。

强化学习训练数据越多,模型推理能力就越强?新研究提出LIM方法,揭示提升推理能力的关键在于优化数据质量,而不是数据规模。该方法在小模型上优势尽显。从此,强化学习Scaling Law可能要被改写了!
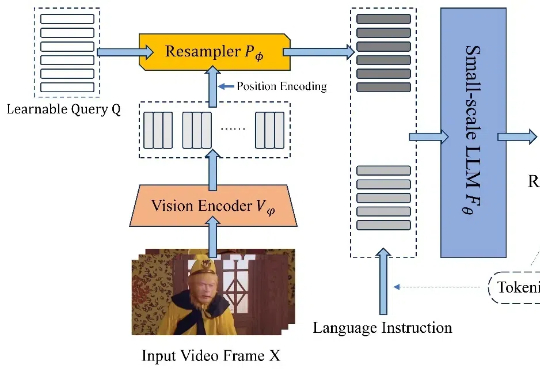
近日,北京航空航天大学的研究团队基于 TinyLLaVA_Factory 的原项目,推出小尺寸简易视频理解框架 TinyLLaVA-Video,其模型,代码以及训练数据全部开源。在计算资源需求显著降低的前提下,训练出的整体参数量不超过 4B 的模型在多个视频理解 benchmark 上优于现有的 7B + 模型。

2024年11月,艾伦人工智能研究所(Ai2)推出了Tülu 3 8B和70B,在性能上超越了同等参数的Llama 3.1 Instruct版本,并在长达82页的论文中公布其训练细节,训练数据、代码、测试基准一应俱全。

非营利研究机构AI2近日推出的完全开放模型OLMo 2,在同等大小模型中取得了最优性能,且该模型不止开放权重,还十分大方地公开了训练数据和方法。