
具身空间数据技术的路线之争:合成重建VS全端生成
具身空间数据技术的路线之争:合成重建VS全端生成具身智能的突破离不开高质量数据。目前,具身合成数据有两条主要技术路线之争:“视频合成+3D重建”or “端到端3D生成”。英伟达在CES 2025指出“尚无互联网规模的机器人数据”,自动驾驶已具备城市级仿真,但家庭等复杂室内环境缺乏3D合成平台。
来自主题: AI技术研报
9548 点击 2025-04-20 21:42
 搜索
搜索
具身智能的突破离不开高质量数据。目前,具身合成数据有两条主要技术路线之争:“视频合成+3D重建”or “端到端3D生成”。英伟达在CES 2025指出“尚无互联网规模的机器人数据”,自动驾驶已具备城市级仿真,但家庭等复杂室内环境缺乏3D合成平台。

北京大学团队继VARGPT实现视觉理解与生成任务统一之后,再度推出了VARGPT-v1.1版本。该版本进一步提升了视觉自回归模型的能力,不仅在在视觉理解方面有所加强,还在图像生成和编辑任务中达到新的性能高度
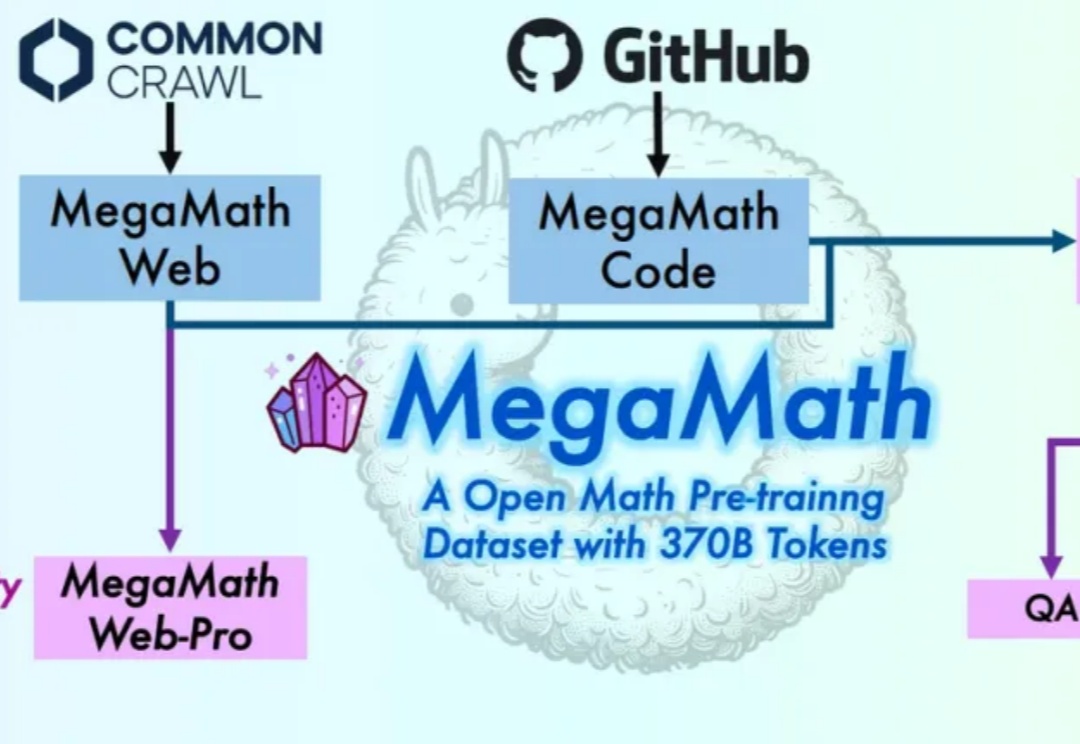
在大模型迈向推理时代的当下,数学推理能力已成为衡量语言模型智能上限的关键指标。

千亿参数内最强推理大模型,刚刚易主了。32B——DeepSeek-R1的1/20参数量;免费商用;且全面开源——模型权重、训练数据集和完整训练代码,都开源了。这就是刚刚亮相的Skywork-OR1 (Open Reasoner 1)系列模型——

让大语言模型更懂特定领域知识,有新招了!

在人工智能飞速发展的今天,LLM 的能力令人叹为观止,但其局限性也日益凸显 —— 它们往往被困于训练数据的「孤岛」,无法直接触及实时信息或外部工具。

当我们遇到新问题时,往往会通过类比过去的经验来寻找解决方案,大语言模型能否如同人类一样类比?在对大模型的众多批判中,人们常说大模型只是记住了训练数据集中的模式,并没有进行真正的推理。
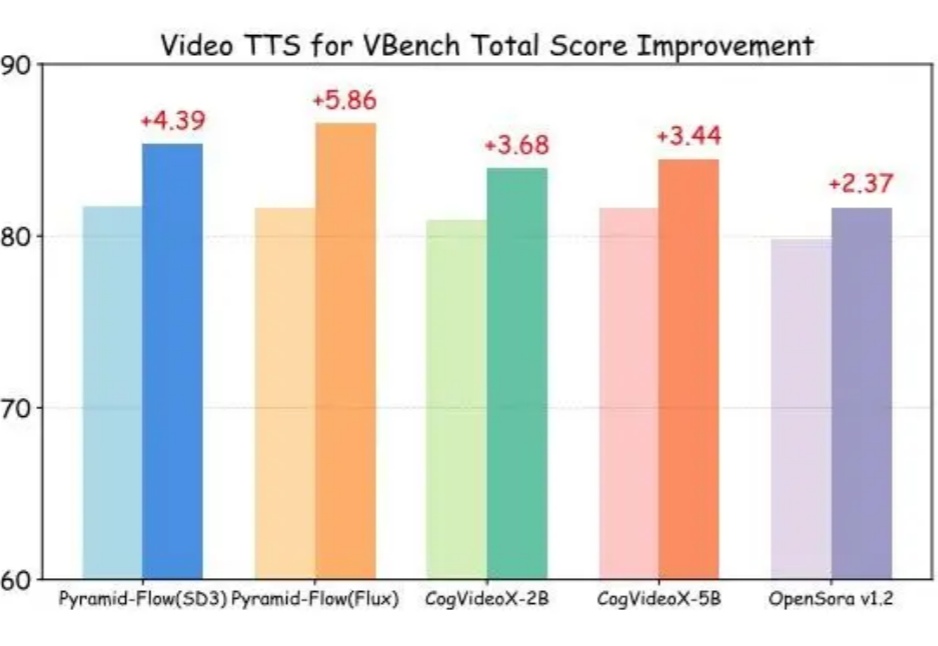
视频作为包含大量时空信息和语义的媒介,对于 AI 理解、模拟现实世界至关重要。视频生成作为生成式 AI 的一个重要方向,其性能目前主要通过增大基础模型的参数量和预训练数据实现提升,更大的模型是更好表现的基础,但同时也意味着更苛刻的计算资源需求。
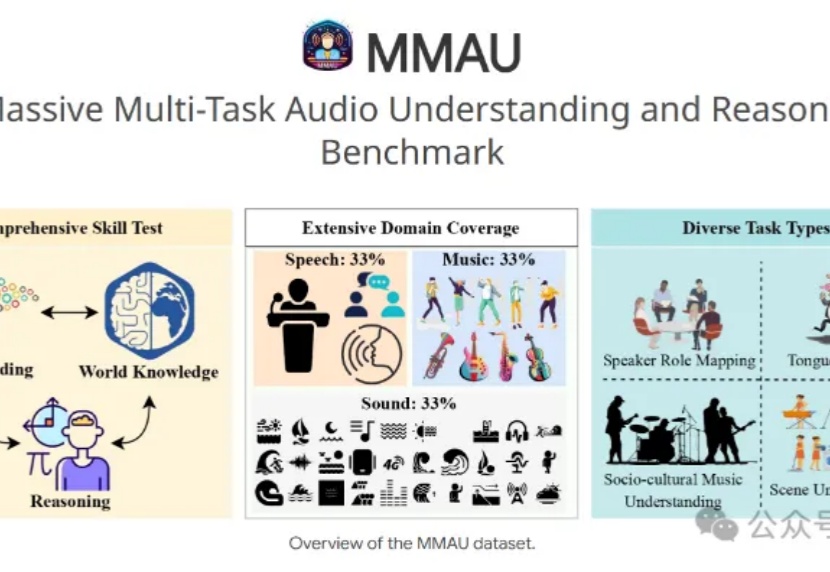
7B小模型+3.8万条训练数据,就能让音频理解和推断评测基准MMAU榜单王座易主?
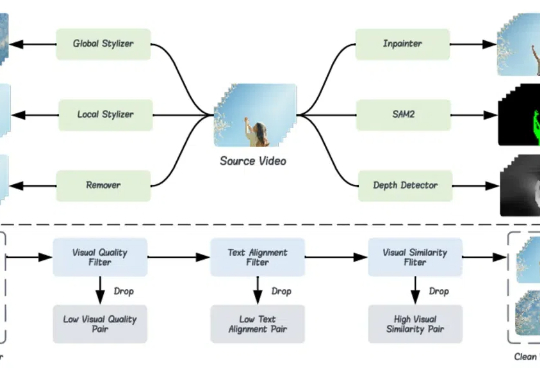
为了解决视频编辑模型缺乏训练数据的问题,本文作者(来自香港中文大学、香港理工大学、清华大学等高校和云天励飞)提出了一个名为 Señorita-2M 的数据集。该数据集包含 200 万高质量的视频编辑对,囊括了 18 种视频编辑任务。