
Z Potentials|CVPR 现场对话苏度科技团队:没有遥控器,没有隔离带,只有真实世界随机的考卷
Z Potentials|CVPR 现场对话苏度科技团队:没有遥控器,没有隔离带,只有真实世界随机的考卷2026 年 6 月的科罗拉多州丹佛市,全球计算机视觉与模式识别领域的顶级学术盛会 CVPR 正在召开,最前沿的视觉模型、机器人技术、下一代智能系统全都在同一个舞台上被反复讨论和辩证。
来自主题: AI资讯
9636 点击 2026-06-08 09:48
 搜索
搜索
2026 年 6 月的科罗拉多州丹佛市,全球计算机视觉与模式识别领域的顶级学术盛会 CVPR 正在召开,最前沿的视觉模型、机器人技术、下一代智能系统全都在同一个舞台上被反复讨论和辩证。

近日,来自清华大学智能产业研究院(AIR)的团队联合北京智源研究院(BAAI)、北京大学、南京大学等机构构建了一个基准:GeoCodeBench。这是一个面向 3D 几何计算机视觉的 PhD 级 coding benchmark,

连续创业的 York 开启了又一段新征程。过去十几年里,他几乎一直在做软硬一体系统:从计算机视觉、嵌入式,到后来的机器人。他的上一个创业项目——智能购物车 Caper AI,在 2021 年被 Instacart 以 3.5 亿美元收购。
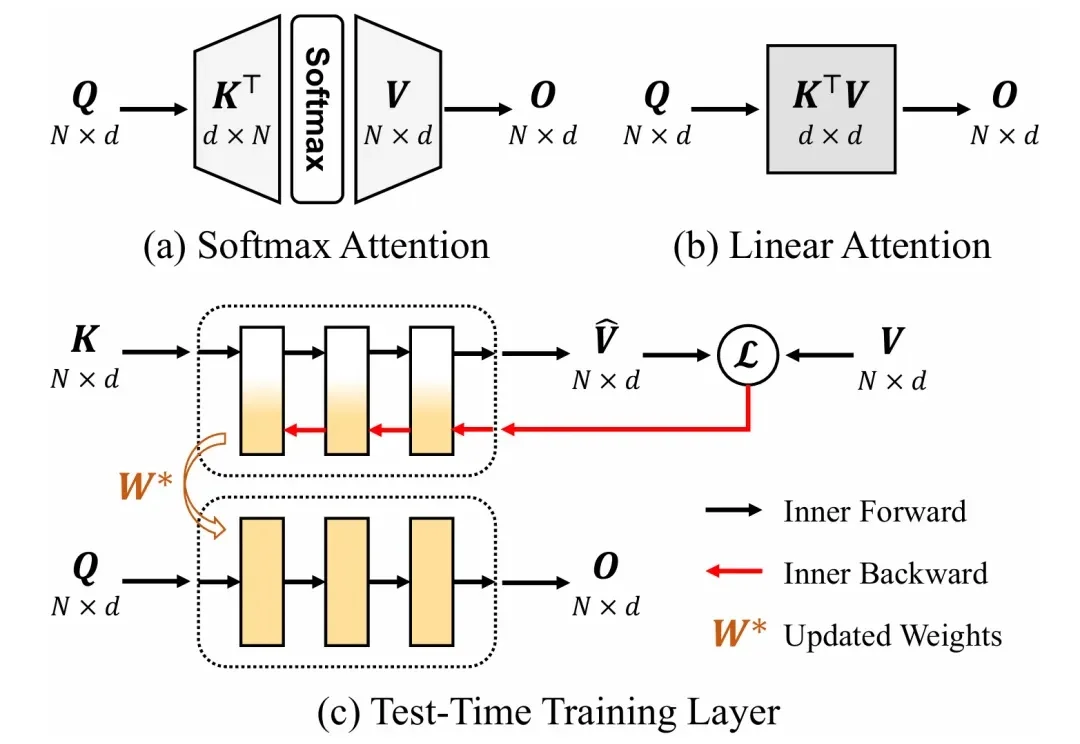
序列建模是大语言模型、计算机视觉等领域的基础共性问题。当前通用的 Transformer 模型计算复杂度随序列长度平方增长,在长序列任务中面临显著的计算挑战。因此,研究者们一直在探索具有线性计算复杂度的高效序列建模方法。

最近,计算机视觉领域的顶级会议 CVPR 2026 的 NTIRE 鲁棒性 AIGC 图像检测挑战赛( Robust AI-Generated Image Detection in the Wild Challenge )结果出炉。蚂蚁集团 AI 安全实验室的队伍 MICV 凭借在鲁棒性测试样本上 ROC AUC 达到了惊人的 0.9723,成功摘得「复杂真实场景鲁棒性样本测试」挑战赛的冠军。

一位复旦教授,造出14万AI工人,最近冲刺IPO。2000年,思谋科技创始人贾佳亚从复旦毕业时,计算机视觉还是个冷门方向。他没想到,二十多年后,自己会给中国工厂造出14万个“AI工人”。
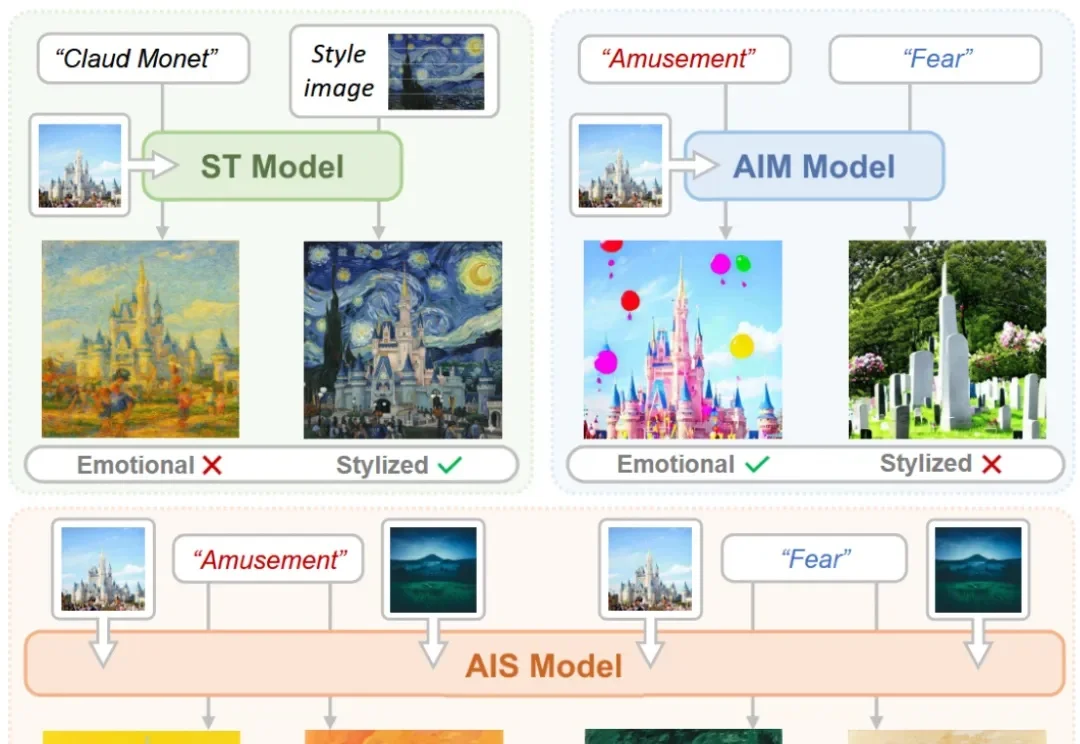
EmoStyle 由深圳大学可视计算研究中心黄惠教授课题组独立完成,第一作者为杨景媛助理教授,第二作者为研二硕士生柏梓桓。深圳大学可视计算研究中心(VCC)以计算机图形学、计算机视觉、人机交互、机器学习、具身智能、可视化和可视分析为学科基础,致力前沿探索与跨学科创新。
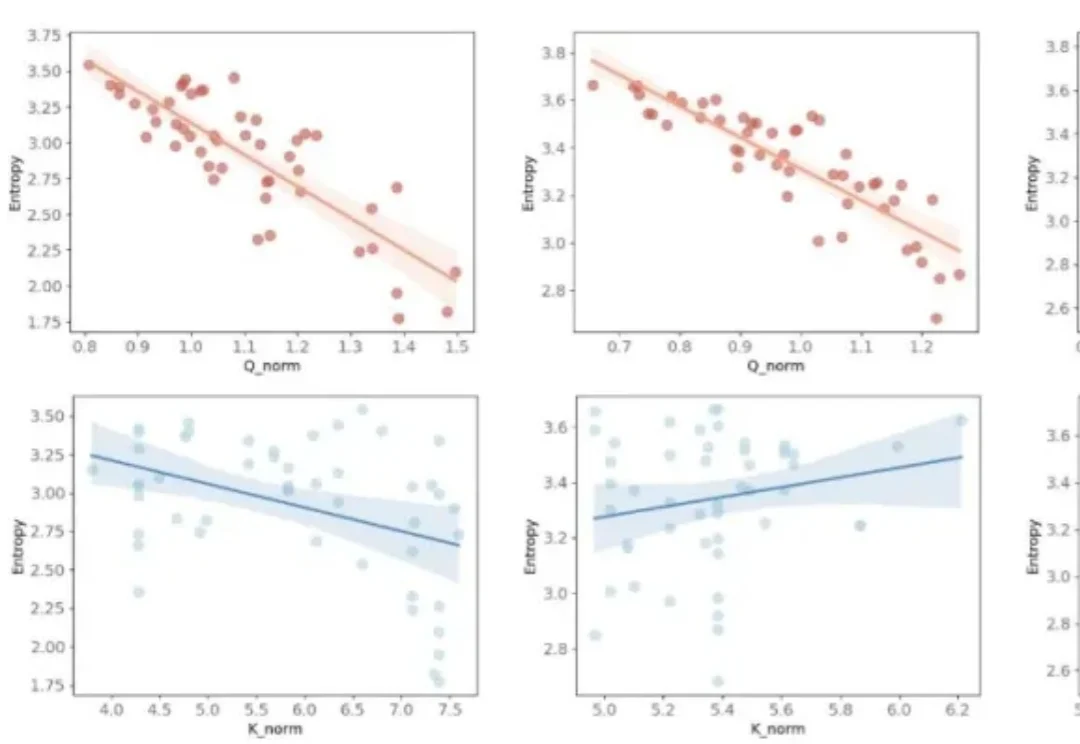
当 Transformer 席卷计算机视觉领域,高分辨率图像、超长序列任务带来的算力与显存瓶颈愈发凸显:标准 Softmax 注意力的二次复杂度,让 70K+token 的超分辨率任务直接显存爆炸,高分辨率图像分割、检测的推理延迟居高不下。

长期以来,计算机视觉领域陷入了一个 “表征(Representation)” 的执念。我们习惯设计各种精巧的 Encoder,试图将动态世界压缩成一组特征向量。然而,视频作为现实的高维投影,其熵值之高、动态之复杂,让这种试图 “定格” 的表征显得力不从心。

图像与视频重光照(Relighting)技术在计算机视觉与图形学中备受关注,尤其在电影、游戏及增强现实等领域应用广泛。当前,基于扩散模型的方法能够生成多样且可控的光照效果,但其优化过程通常依赖于语义空间,而语义上的相似性无法保证视觉空间中的物理合理性,导致生成结果常出现高光过曝、阴影错位、遮挡关系错误等不合理现象。