
500行极简开源框架,硬刚GPT/Gemini视觉极限!
500行极简开源框架,硬刚GPT/Gemini视觉极限!多模态模型代码写得像老司机,却在数手指、量柱子时频频翻车?UniPat AI用五百行代码打造的SWE-Vision,让模型「掏出Python尺子」自我验证,一举拿下五大视觉相关基准SOTA。
来自主题: AI资讯
8305 点击 2026-03-16 15:08
 搜索
搜索
多模态模型代码写得像老司机,却在数手指、量柱子时频频翻车?UniPat AI用五百行代码打造的SWE-Vision,让模型「掏出Python尺子」自我验证,一举拿下五大视觉相关基准SOTA。
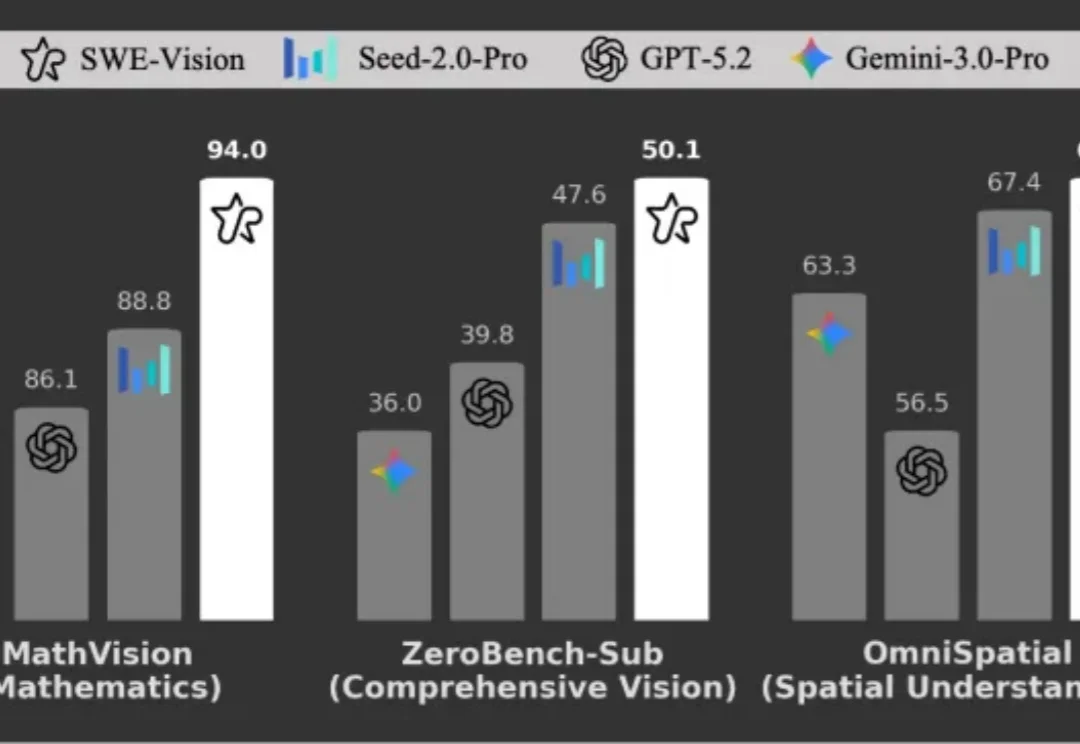
多模态大模型在代码能力上进步惊人,但在基础视觉任务上却频繁失误。UniPat AI 构建了一个极简的视觉智能体框架 ——SWE-Vision,让模型可以编写并执行 Python 代码来处理和验证自己的视觉判断。在五个主流视觉基准测试中,SWE-Vision 均达到了当前最优水平。

当今的 AI 智能体(Agent)越来越强大,尤其是像 VLM(视觉-语言模型)这样能「看懂」世界的智能体。但研究者发现一个大问题:相比于只处理文本的 LLM 智能体,VLM 智能体在面对复杂的视觉任务时,常常表现得像一个「莽撞的执行者」,而不是一个「深思熟虑的思考者」。
库克和马斯克都盯上的CV公司!打开Prompt AI官网,上面介绍了这家公司的定位:一家专注于消费应用视觉智能的AI公司。这家总部位于旧金山的初创公司,其核心团队非常UC伯克利范儿:

今年苹果在 AI 上宣布的诸多所谓新功能,例如实时翻译、快捷指令等,并无太多革命性;至于视觉智能 (visual intelligence),不仅功能落后 Google Lens 六七年,交互体验上也远未达到一众 Android 友商的内置 AI/Agent 产品在 2025 上半年水平。

通用语言模型率先起跑,但通用视觉模型似乎迟到了一步。究其原因,语言中蕴含大量序列信息,能做更深入的推理;而视觉模型的输入内容更加多元、复杂,输出的任务要求多种多样,需要对物体在时间、空间上的连续性有完善的感知,传统的学习方法数据量大、经济属性上也不理性...... 还没有一套统一的算法来解决计算机对空间信息的理解。

李飞飞最新采访来了,继续延伸她在NeurIPS有关视觉智能的话题。

为提高生产力、优化流程和创造更加安全的空间,埃森哲、戴尔科技和联想等公司正在使用全新 NVIDIA AI Blueprint 开发视觉 AI 智能体。

在 AI 领域,近年来各个子领域都逐渐向 transformer 架构靠拢,只有文生图和文生视频一直以 diffusion + u-net 结构作为主流方向。diffusion 有更公开可用的开源模型,消耗的计算资源也更少。