
西湖大学吴泰霖:从“AI物理学家”到创业,原力引擎想回答AI for Engineering的根问题
西湖大学吴泰霖:从“AI物理学家”到创业,原力引擎想回答AI for Engineering的根问题2026 年 1 月,他作为首席科学家创立了原力引擎(UniForce AI)公司,试图用生成式仿真、智能控制和多智能体系统解决多物理场仿真与强耦合控制问题,并率先从可控核聚变这一工程领域最困难的问题切入。
来自主题: AI资讯
8940 点击 2026-07-10 10:46
 搜索
搜索
2026 年 1 月,他作为首席科学家创立了原力引擎(UniForce AI)公司,试图用生成式仿真、智能控制和多智能体系统解决多物理场仿真与强耦合控制问题,并率先从可控核聚变这一工程领域最困难的问题切入。
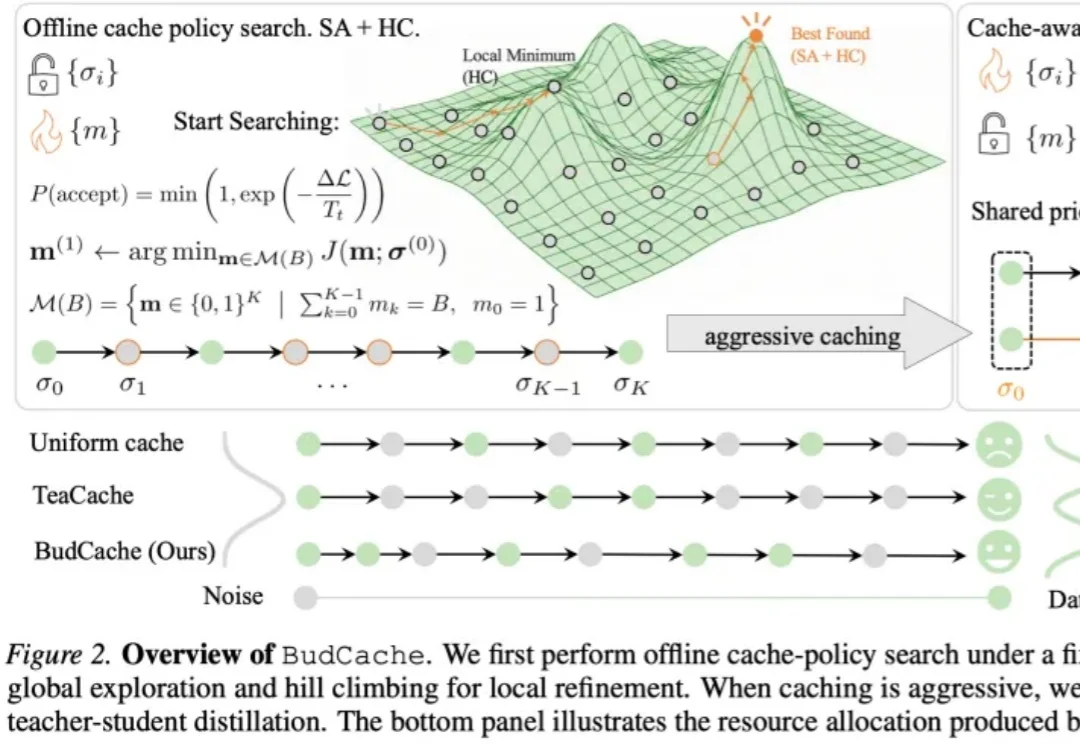
扩散模型生成得越来越好,但也越来越慢。

来自西湖大学和香港中文大学(深圳)的团队沿着这一思路提出 Drifting Preference Optimization(DrPO),把漂移场用于单步文生图模型的偏好后训练。在 DrPO 中,奖励只负责对候选图像排序,不参与反向传播。具体而言,针对同一个文本提示词,当前模型生成一组候选图像。高分样本在特征空间中产生吸引,低分样本产生排斥,并结合参考模型约束给出模型的更新方向。

多模态大模型越来越会读图中文字,但最新研究显示,「读得出来」并不等于「防得住」。西湖大学 AGI Lab 的研究团队发现,当有害文本被渲染成低清、模糊或带噪图片后,模型在一个特定清晰度区间内反而更容易被越狱。
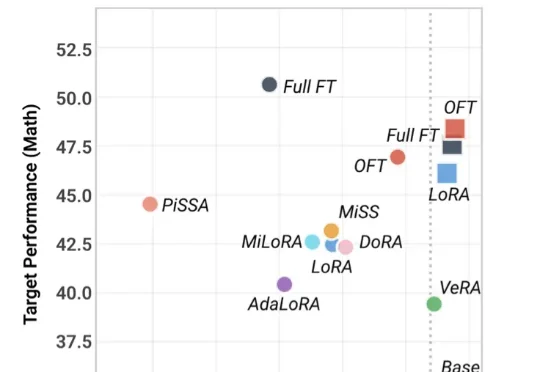
近期,来自香港中文大学、西湖大学、德国马普所等机构的研究者提出了 PEFT-Arena —— 一个从稳定性‑可塑性权衡(stability–plasticity trade-off)视角重新审视 PEFT 方法的评测基准与分析框架。该工作已在 ICLR 2026 相关 workshop 上进行了展示,并开源了完整代码。
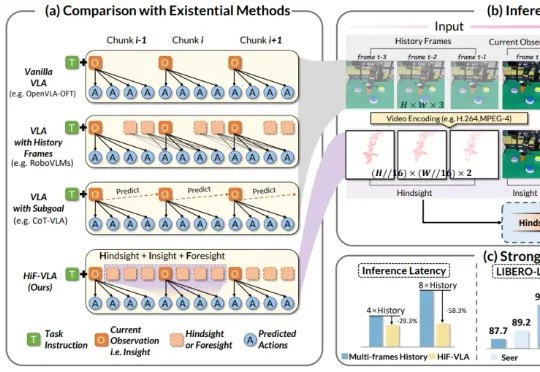
来自西湖大学、浙江大学、西湖机器人等机构的研究团队提出了一种以运动(Motion)为中心的全新双向时空推理框架 HiF-VLA。抛弃冗余的像素级输入,HiF-VLA 巧妙提取低维紧凑的 Motion 向量作为动态先验,在一个创新的「联合专家」模块中,同步完成未来视觉运动的预测与高精度动作序列的生成。

现有Rectified Flow(RF)模型在反演阶段面临的核心挑战,是逆向ODE对微小误差高度敏感,容易沿着数值不稳定方向偏离前向流形,导致轨迹发散、重建不一致、编辑不可控。为解决这一问题,团队提出PMI(Prox-Mean-Inversion),一种针对RF反演稳定性的轻量化修正机制。

针对端到端全模态大模型(OmniLLMs)在跨模态对齐和细粒度理解上的痛点,浙江大学、西湖大学、蚂蚁集团联合提出 OmniAgent。这是一种基于「音频引导」的主动感知 Agent,通过「思考 - 行动 - 观察 - 反思」闭环,实现了从被动响应到主动探询的范式转变。
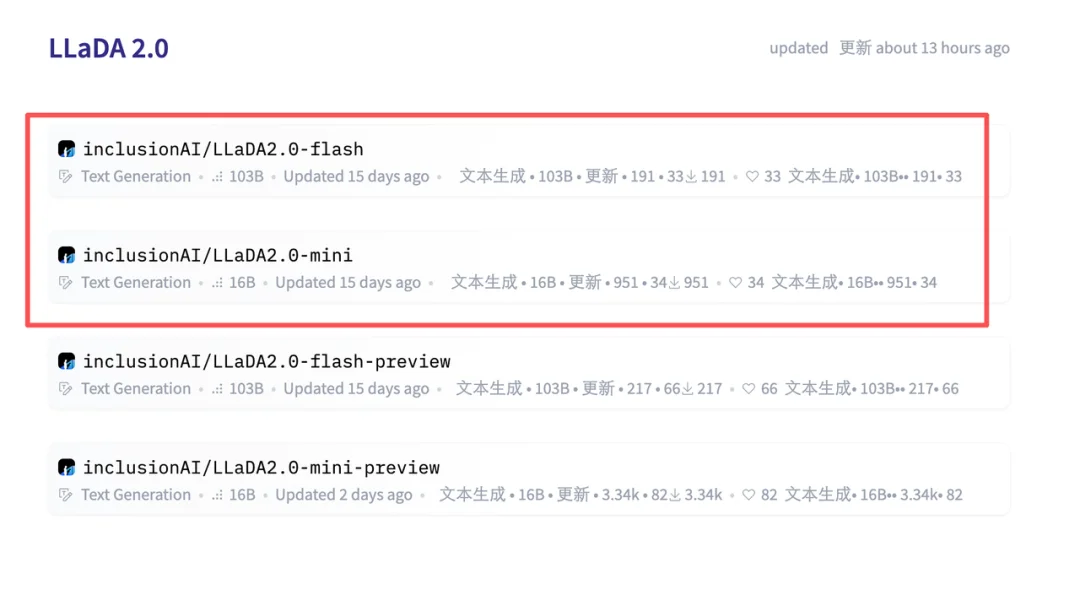
前段时间,我们在 HuggingFace 页面发现了两个新模型:LLaDA2.0-mini 和 LLaDA2.0-flash。它们来自蚂蚁集团与人大、浙大、西湖大学组成的联合团队,都采用了 MoE 架构。前者总参数量为 16B,后者总参数量则高达 100B—— 在「扩散语言模型」这个领域,这是从未见过的规模。

在AIGC的浪潮中,3D生成模型(如TRELLIS)正以惊人的速度进化,生成的模型越来越精细。然而,“慢”与计算量大依然是制约其大规模应用的最大痛点。复杂的去噪过程、庞大的计算量,让生成一个高质量3D资产往往需要漫长的等待。