具身智能能力狂飙,安全却严重滞后?首个安全可信EAI框架与路线图出炉!
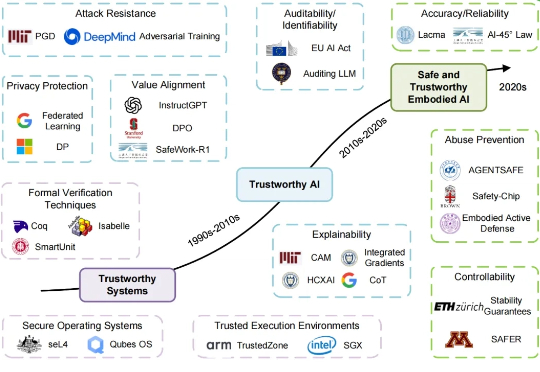
具身智能能力狂飙,安全却严重滞后?首个安全可信EAI框架与路线图出炉!近年来,以人形机器人、自动驾驶为代表的具身人工智能(Embodied Artificial Intelligence, EAI)正以前所未有的速度发展,从数字世界大步迈向物理现实。然而,当一次错误的风险不再是屏幕上的一行乱码,而是可能导致真实世界中的物理伤害时,一个紧迫的问题摆在了我们面前: 如何确保这些日益强大的具身智能体是安全且值得信赖的?
来自主题: AI技术研报
8146 点击 2025-09-17 14:33