零样本&少样本横扫12个工业医疗数据集:西门子×腾讯优图新研究精准定位缺陷,检测精度新SOTA丨AAAI 2026
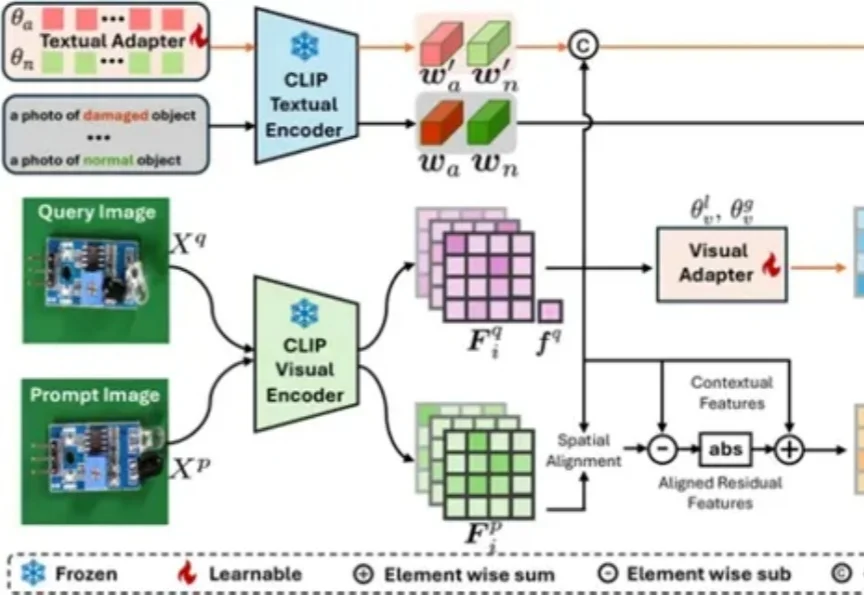
零样本&少样本横扫12个工业医疗数据集:西门子×腾讯优图新研究精准定位缺陷,检测精度新SOTA丨AAAI 2026视觉模型用于工业“缺陷检测”等领域已经相对成熟,但当前普遍使用的传统模型在训练时对数据要求较高,需要大量的经过精细标注的数据才能训练出理想效果。
来自主题: AI技术研报
9065 点击 2026-01-19 15:13
 搜索
搜索
视觉模型用于工业“缺陷检测”等领域已经相对成熟,但当前普遍使用的传统模型在训练时对数据要求较高,需要大量的经过精细标注的数据才能训练出理想效果。

国内真是不好混。
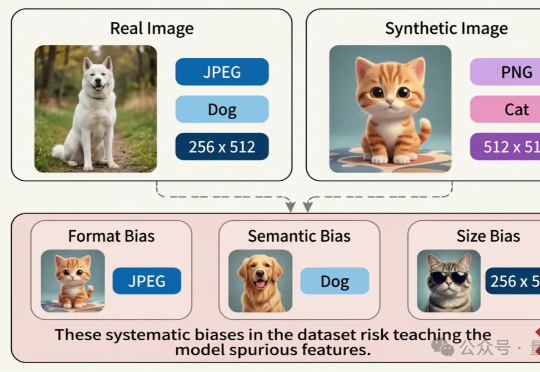
近日,腾讯优图实验室联合华东理工大学、北京大学等研究团队在A生成图像检测(AI-Generated Image Detection)泛化问题上展开研究,提出Dual Data Alignment(双重数据对齐,DDA)方法,从数据层面系统性抑制“偏差特征”,显著提升检测器在跨模型、跨数据域场景下的泛化能力。
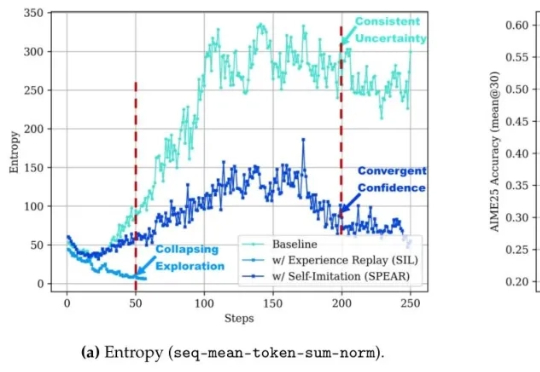
让智能体自己摸索新方法,还模仿自己的成功经验。腾讯优图实验室开源强化学习算法——SPEAR(Self-imitation with Progressive Exploration for Agentic Reinforcement Learning)。

智能体开发平台3.0(ADP3.0)面向全球上线,腾讯优图实验室的关键智能体技术也将持续开源。据说,这次新版本打磨了3个月,完成近600个功能上线,从RAG能力到Workflow,从Multi-Agent协同到应用评测,再到插件生态,看样子是把所有模块都更新了一遍。
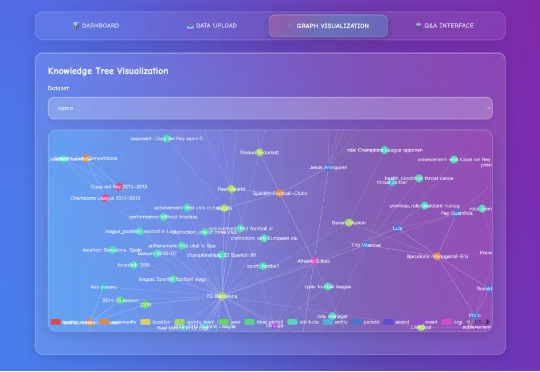
图检索增强生成(GraphRAG)已成为大模型解决复杂领域知识问答的重要解决方案之一。然而,当前学界和开源界的方案都面临着三大关键痛点: 开销巨大:通过 LLM 构建图谱及社区,Token 消耗大,耗
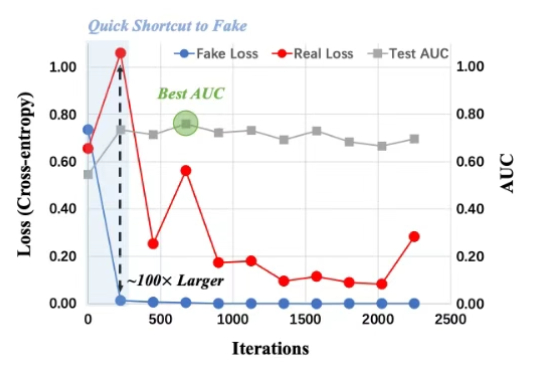
随着 OpenAI 推出 GPT-4o 的图像生成功能,AI 生图能力被拉上了一个新的高度,但你有没有想过,这光鲜亮丽的背后也隐藏着严峻的安全挑战:如何区分生成图像和真实图像?

现有的语言大模型(LLMs)在复杂指令下的理解和执行能力仍需提升。

AI模型用于工业异常检测,再次取得新SOTA!
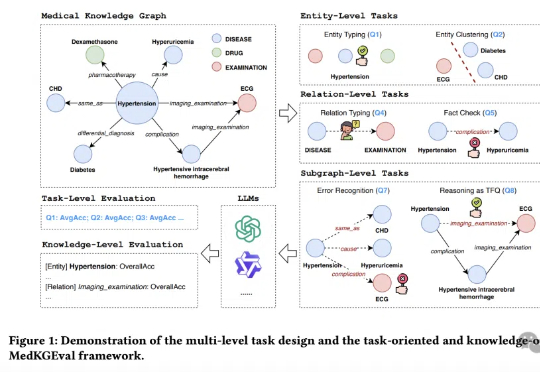
医疗大模型知识覆盖度首次被精准量化!