
美团 LongCat-2.0:第一个在纯国产芯片训练的万亿参数大模型
美团 LongCat-2.0:第一个在纯国产芯片训练的万亿参数大模型如果只看标题,它很容易被归到“又一个万亿参数大模型”的队伍里:1.6 万亿总参数、MoE 架构、100 万 token 上下文、面向代码和 Agent 场景。但这次真正值得看的,不只是模型有多大,而是它背后的三个问题:国产算力能不能支撑前沿级大模型训练?
来自主题: AI资讯
9585 点击 2026-06-30 21:04
 搜索
搜索
如果只看标题,它很容易被归到“又一个万亿参数大模型”的队伍里:1.6 万亿总参数、MoE 架构、100 万 token 上下文、面向代码和 Agent 场景。但这次真正值得看的,不只是模型有多大,而是它背后的三个问题:国产算力能不能支撑前沿级大模型训练?
一边是 DeepSeek。2026 年 4 月 24 日,正式发布新一代模型DeepSeek-V4 系列预览版,并同步开源。另一边,美团闷声干了件大事——用全国产算力集群,训练出了万亿参数大模型 LongCat-2.0 系列预览版( LongCat-2.0-Preview )。
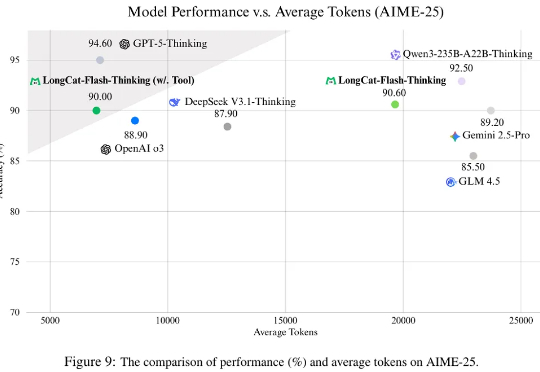
最近,美团在AI开源赛道上在猛踩加速。今天,在开源其首款大语言模型仅仅24天后,美团又开源了其首款自研推理模型LongCat-Flash-Thinking。与其基础模型LongCat-Flash类似,效率也是LongCat-Flash-Thinking的最大特点。美团在技术报告中透露,LongCat-Flash-Thinking在自研的DORA强化学习基础设施完成训练

用过才知道,「快」不是万能药。

国内外开发者:亲测,美团新开源的模型速度超快!