
超越KL!大连理工发布Wasserstein距离知识蒸馏新方法|NeurIPS 2024
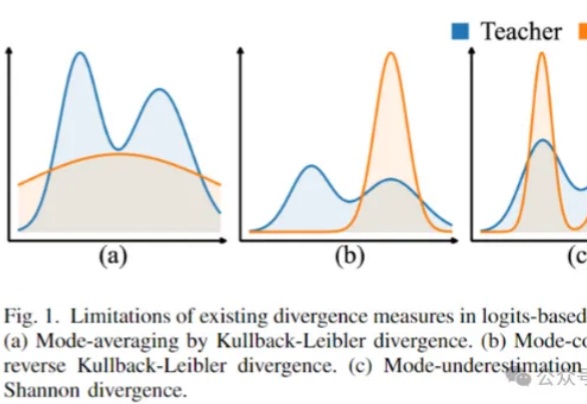
超越KL!大连理工发布Wasserstein距离知识蒸馏新方法|NeurIPS 2024大连理工大学的研究人员提出了一种基于Wasserstein距离的知识蒸馏方法,克服了传统KL散度在Logit和Feature知识迁移中的局限性,在图像分类和目标检测任务上表现更好。
来自主题: AI技术研报
7219 点击 2025-01-10 16:00
 搜索
搜索
大连理工大学的研究人员提出了一种基于Wasserstein距离的知识蒸馏方法,克服了传统KL散度在Logit和Feature知识迁移中的局限性,在图像分类和目标检测任务上表现更好。

最新综述论文探讨了知识蒸馏在持续学习中的应用,重点研究如何通过模仿旧模型的输出来减缓灾难性遗忘问题。通过在多个数据集上的实验,验证了知识蒸馏在巩固记忆方面的有效性,并指出结合数据回放和使用separated softmax损失函数可进一步提升其效果。
用大模型“蒸馏”小模型,有新招了!
自从 OpenAI 发布展现出前所未有复杂推理能力的 o1 系列模型以来,全球掀起了一场 AI 能力 “复现” 竞赛。近日,上海交通大学 GAIR 研究团队在 o1 模型复现过程中取得新的突破,通过简单的知识蒸馏方法,团队成功使基础模型在数学推理能力上超越 o1-preview。

早在 2020 年,陶大程团队就发布了《Knowledge Distillation: A Survey》,详细介绍了知识蒸馏在深度学习中的应用,主要用于模型压缩和加速。随着大语言模型的出现,知识蒸馏的作用范围不断扩大,逐渐扩展到了用于提升小模型的性能以及模型的自我提升。

在微调大型模型的过程中,一个常用的策略是“知识蒸馏”,这意味着借助高性能模型,如GPT-4,来优化性能较低的开源模型。这种方法背后隐含的哲学理念与logos中心论相似,把GPT-4等模型视为更接近唯一的逻辑或真理的存在。