
两大模型发布!豆包大模型日均使用量突破50万亿Tokens
两大模型发布!豆包大模型日均使用量突破50万亿Tokens今天,在 FORCE 原动力大会上,火山引擎发布豆包大模型1.8、豆包视频生成模型 Seedance 1.5 pro。经过一年多的持续升级,豆包大模型家族在多模态理解和生成能力、Agent 能力上,已位于全球第一梯队。
来自主题: AI资讯
13463 点击 2025-12-18 13:11
 搜索
搜索
今天,在 FORCE 原动力大会上,火山引擎发布豆包大模型1.8、豆包视频生成模型 Seedance 1.5 pro。经过一年多的持续升级,豆包大模型家族在多模态理解和生成能力、Agent 能力上,已位于全球第一梯队。

首个AI视频生成全球挑战赛来袭,袁粒、颜水成、程明明、田永鸿、Philip Torr多位大佬发起,20万大奖虚位以待!创作大神还是技术极客?两大赛道总有一个适合你,速速点击报名吧。

自 Sora 2 发布以来,各大科技厂商迎来新一轮视频生成模型「军备竞赛」,纷纷赶在年底前推出更强的迭代版本。

不仅能“听懂”物体的颜色纹理,还能“理解”深度图、人体姿态、运动轨迹……
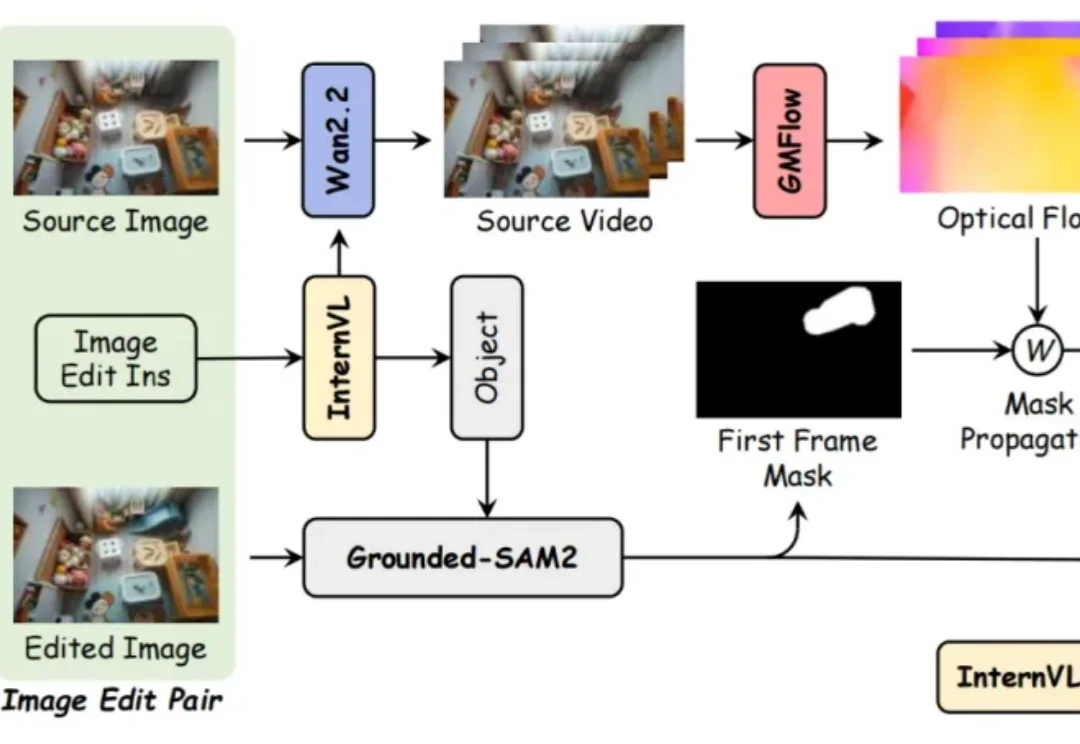
近年来,基于扩散的视频生成模型的最新进展极大地提高了视频编辑的真实感和可控性。然而,文字驱动的视频对象移除添加依然面临巨大挑战:
今日,美团正式发布并开源图像生成模型LongCat-Image,这是一款在图像编辑能力上达到开源SOTA水准的6B参数模型,重点瞄准文生图与单图编辑两大核心场景。在实际体验中,它在连续改图、风格变化和材质细节上表现较好,但在复杂排版场景下,中文文字渲染仍存在不稳定的情况。

在 Text-to-Video / Image-to-Video 技术突飞猛进的今天,我们已经习惯了这样一个常识: 视频生成的第一帧(First Frame)只是时间轴的起点,是后续动画的起始画面。

DeepWisdom研究团队提出:视频生成模型不仅能画画,更能推理。 为了验证这一观点,团队推出了VR-Bench——这是首个通过迷宫任务评估视频模型空间推理(spatial reasoning)能力的基准测试

在AIGC的浪潮中,3D生成模型(如TRELLIS)正以惊人的速度进化,生成的模型越来越精细。然而,“慢”与计算量大依然是制约其大规模应用的最大痛点。复杂的去噪过程、庞大的计算量,让生成一个高质量3D资产往往需要漫长的等待。
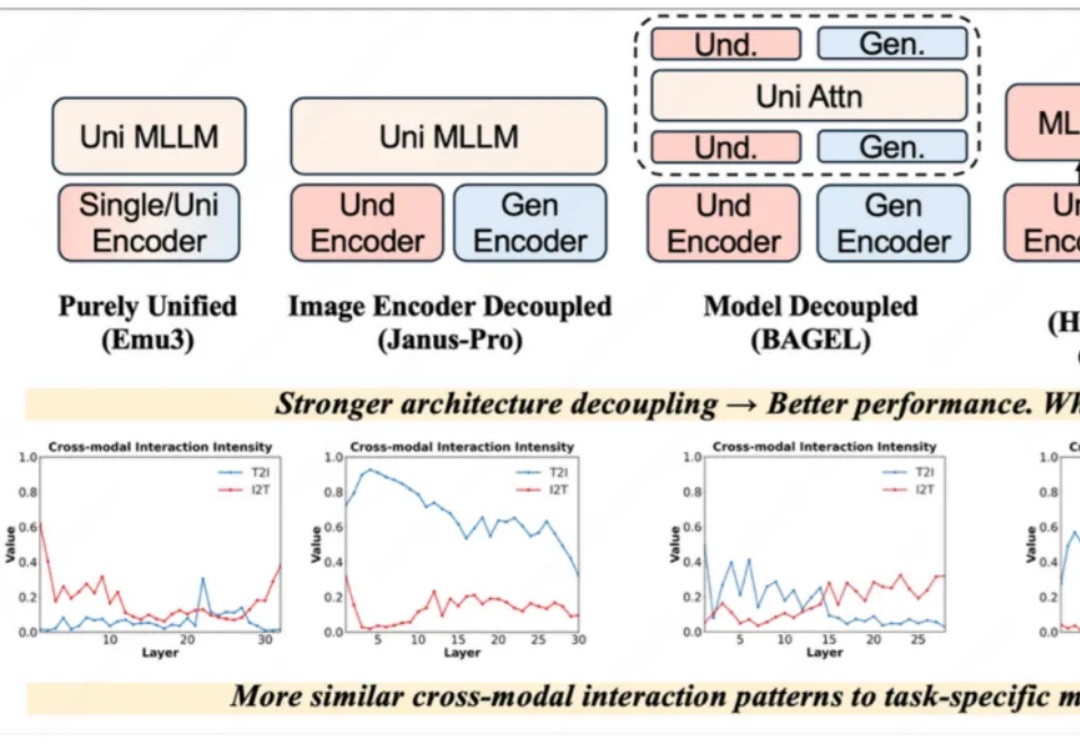
近一年以来,统一理解与生成模型发展十分迅速,该任务的主要挑战在于视觉理解和生成任务本身在网络层间会产生冲突。早期的完全统一模型(如 Emu3)与单任务的方法差距巨大,Janus-Pro、BAGEL 通过一步一步解耦模型架构,极大地减小了与单任务模型的性能差距,后续方法甚至通过直接拼接现有理解和生成模型以达到极致的性能。