挖到M2.1的7个神仙用法,有点上头。。
挖到M2.1的7个神仙用法,有点上头。。上周我还在折腾各种图片、视频生成模型,这周又到了编程周。前天MiniMax丢出了个在编程界绝对有分量的模型:MiniMax-M2.1。然后发现就在刚才已经开源了:
来自主题: AI资讯
11314 点击 2025-12-27 10:56
 搜索
搜索
上周我还在折腾各种图片、视频生成模型,这周又到了编程周。前天MiniMax丢出了个在编程界绝对有分量的模型:MiniMax-M2.1。然后发现就在刚才已经开源了:

能自动查数据、写分析、画专业金融图表的AI金融分析师来了!最近,中国人民大学高瓴人工智能学院提出了一个面向真实金融投研场景的多模态研报生成系统——玉兰·融观(Yulan-FinSight)。

视频生成模型总是「记性不好」?生成几秒钟后物体就变形、背景就穿帮?北大、中大等机构联合发布EgoLCD,借鉴人类「长短时记忆」机制,首创稀疏KV缓存+LoRA动态适应架构,彻底解决长视频「内容漂移」难题,在EgoVid-5M基准上刷新SOTA!让AI像人一样拥有连贯的第一人称视角记忆。

抽奖式的生图体验,确实让很多设计师在尝鲜之后又默默打开了 Photoshop。于是乎,阿里千问团队再次出手,开源了一个叫 Qwen-Image-Layered 的模型,试图从底层逻辑上解决这个问题。
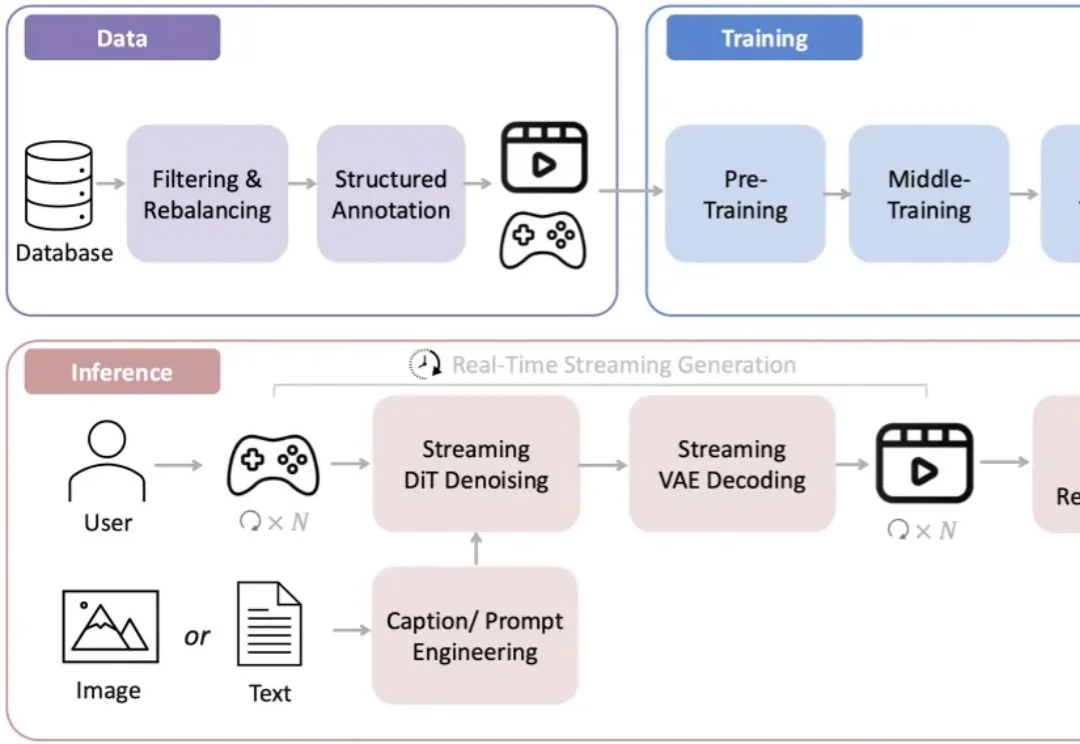
还记得前段时间在 AI 圈刷屏的李飞飞「3D 世界生成模型」吗?现在,国产版终于来了。
MiniMax海螺视频团队不藏了!首次开源就揭晓了一个困扰行业已久的问题的答案——为什么往第一阶段的视觉分词器里砸再多算力,也无法提升第二阶段的生成效果?翻译成大白话就是,虽然图像/视频生成模型的参数越做越大、算力越堆越猛,但用户实际体验下来总有一种微妙的感受——这些庞大的投入与产出似乎不成正比,模型离完全真正可用总是差一段距离。
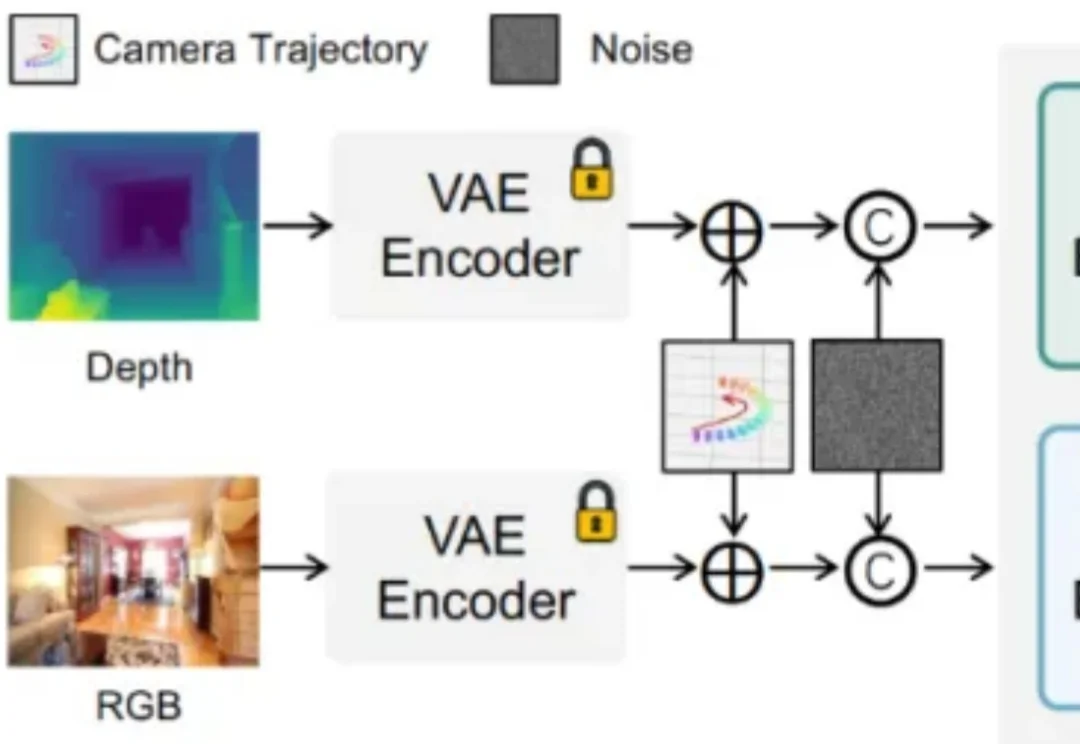
你的生成模型真的「懂几何」吗?还是只是在假装对齐相机轨迹?

近日,来自 Meta、香港科技大学、索邦大学、纽约大学的一个联合团队基于 JEPA 打造了一个视觉-语言模型:VL-JEPA。据作者 Pascale Fung 介绍,VL-JEPA 是第一个基于联合嵌入预测架构,能够实时执行通用领域视觉-语言任务的非生成模型。

现有视频生成模型往往难以兼顾「运镜」与「摄影美学」的精确控制。为此,华中科技大学、南洋理工大学、商汤科技和上海人工智能实验室团队推出了 CineCtrl。作为首个统一的视频摄影控制 V2V 框架,CineCtrl 通过解耦交叉注意力机制,摆脱了多控制信号共同控制的效果耦合问题,实现了对视频相机外参轨迹与摄影效果的独立、精细、协调控制。

坏了,阿里这波是冲着Sora 2去的!