

AI生图大洗牌!流匹配架构颠覆传统,一个模型同时接受文本和图像输入
AI生图大洗牌!流匹配架构颠覆传统,一个模型同时接受文本和图像输入AI生图新突破!一个模型同时接受文本和图像输入。
来自主题: AI资讯
10927 点击 2025-05-30 19:57
AI生图新突破!一个模型同时接受文本和图像输入。

3月时候GPT迎来了一波更新,在文生图、图生图领域带来了巨大更新,而紧接而至的却是一些创业公司的哀嚎:
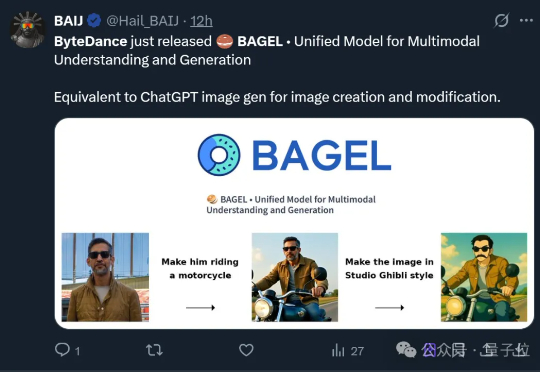
字节最近真的猛猛开源啊……这一次,他们直接开源了GPT-4o级别的图像生成能力。不止于此,其最新融合的多模态模型BAGEL主打一个“大一统”, 将带图推理、图像编辑、3D生成等功能全都集中到了一个模型。

Recraft,利用AI生成和编辑高质量矢量插图和图标,服务于设计和市场团队。完成3000万美元B轮融资,投资方为Accel、Khosla Ventures、Madrona。本轮估值未知,累计融资4200万美元。

何恺明团队又一力作!这次他们带来的是「生成模型界的降维打击」——MeanFlow:无需预训练、无需蒸馏、不搞课程学习,仅一步函数评估(1-NFE),就能碾压以往的扩散与流模型!

那个曾经一码难求的 Manus 已经可以全面注册了。从此以后,到处求购邀请码的时代一去不复回。

刚刚,鹅厂把文生图卷出了新高度——发布混元图像2.0模型(Hunyuan Image 2.0),首次实现毫秒级响应,边说边画,实时生成!用户一边描述,它紧跟着绘制,整个过程那叫一个丝滑。不用等待,专治各种没有耐心。
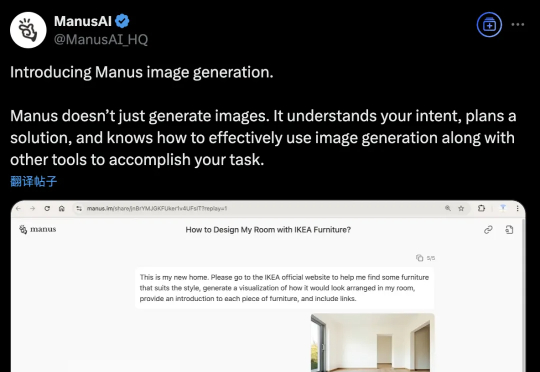
Manus深夜官宣,现在支持生成图像了!和一般AI绘图工具的“抽卡”模式不同,Manus能够理解你画图的目的,规划出生成方案后再“动手”。
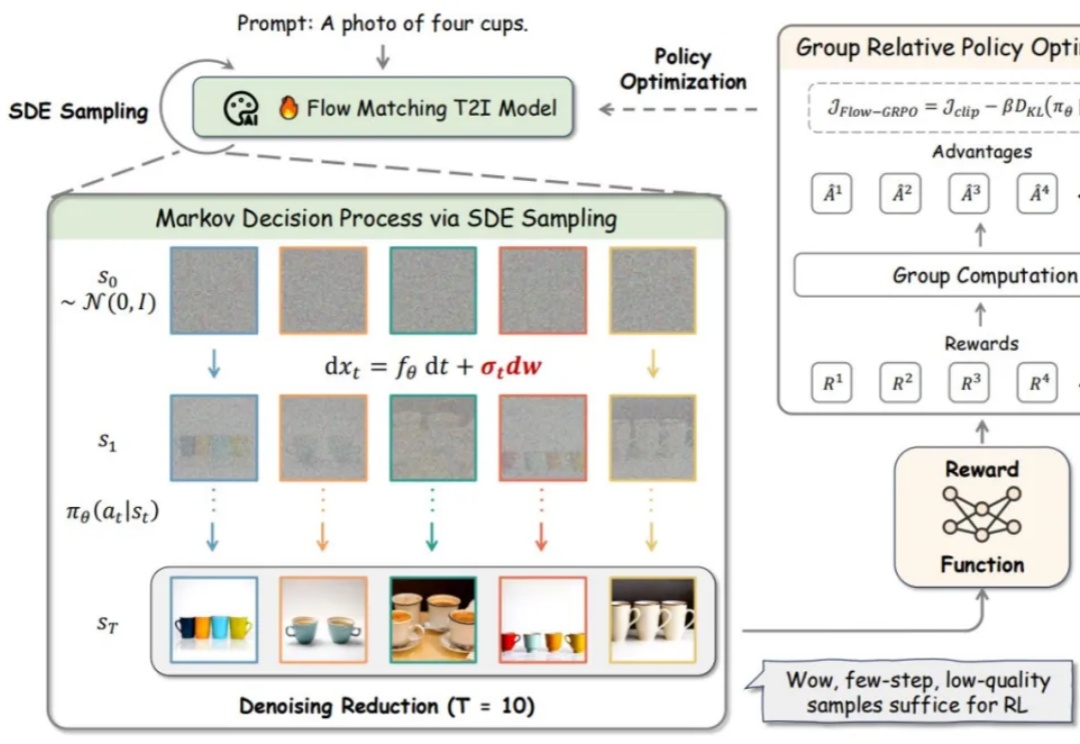
流匹配模型因其坚实的理论基础和在生成高质量图像方面的优异性能,已成为图像生成(Stable Diffusion, Flux)和视频生成(可灵,WanX,Hunyuan)领域最先进模型的训练方法。然而,这些最先进的模型在处理包含多个物体、属性与关系的复杂场景,以及文本渲染任务时仍存在较大困难。
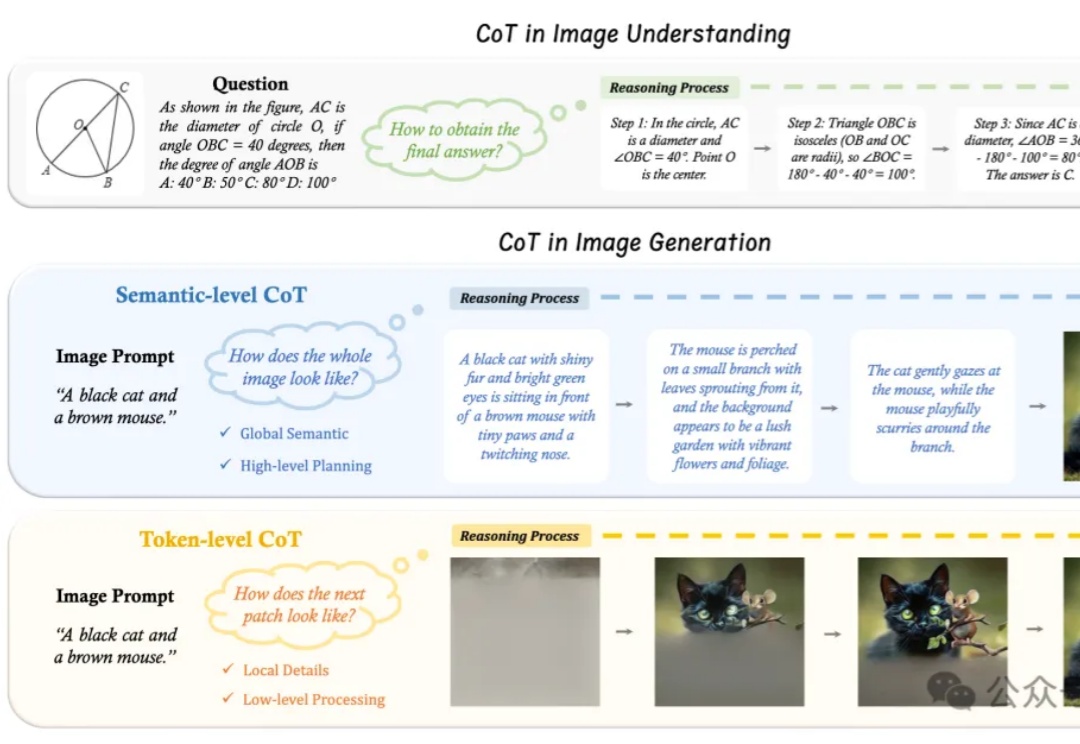
“先推理、再作答”,语言大模型的Thinking模式,现在已经被拓展到了图片领域。