

微调Flux席卷全网,外国小哥一人组一队漫威英雄!
微调Flux席卷全网,外国小哥一人组一队漫威英雄!席卷开源界的AI生图王者诞生了!发布半个月,Flux已经成为替代Midjourney的宠儿。各路开发者们开始用自己的照片微调LoRA,一人拿捏多种风格。
来自主题: AI资讯
11219 点击 2024-08-19 14:32
席卷开源界的AI生图王者诞生了!发布半个月,Flux已经成为替代Midjourney的宠儿。各路开发者们开始用自己的照片微调LoRA,一人拿捏多种风格。

昨天马斯克的 Grok-2 发布,加入了 FLUX 模型提供的文生图能力。一夜之间,FLUX 毫无底线的图片血洗 X(推特)。

惊爆!马斯克在某超市做「小偷」,当场被摄像头拍下,是真还是假,没人说得清。Grok被发现没有护栏后,网友们直接冲爆了,霉霉、川普、马里奥、米老鼠……Grok生图简直令人瞠目结舌。
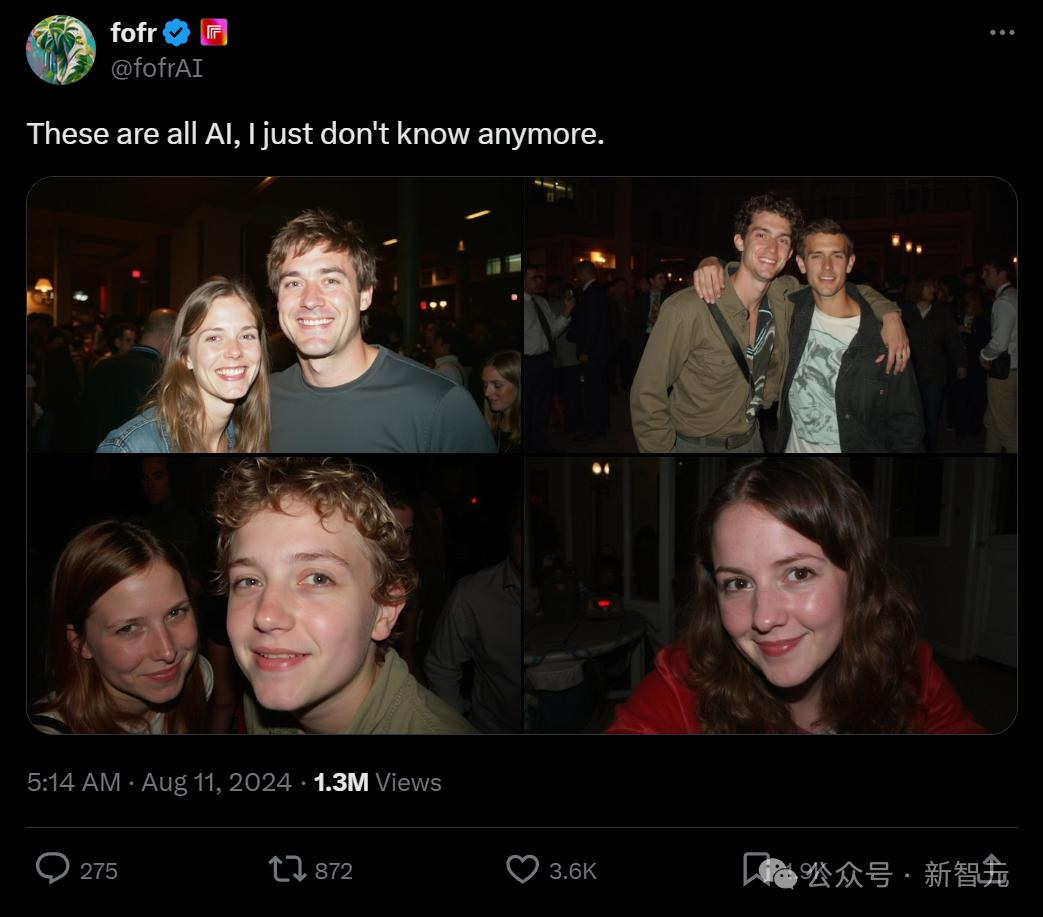
AI生图工具Flux,俨然已经掀起了全网的风暴。这张情侣写真逼真、细腻,打光、纹理、毛发,都是挑不出破绽的程度。视频、声音、口型,AI的进化越来越完美了! 最近Flux的爆火,简直把所有人的三观都撼动了。 不懂就问:现在网上的东西,还有什么是真的?

随着大模型的落地按下加速键,文生图无疑是最火热的应用方向之一。
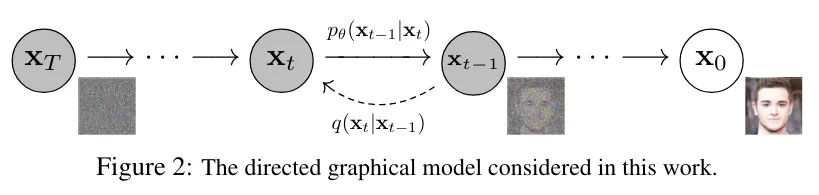
近日,来自加州大学尔湾分校等机构的研究人员,利用延迟掩蔽、MoE、分层扩展等策略,将扩散模型的训练成本降到了1890美元。

赛博照妖镜下,AI美女全变鬼。

榜单头部所属品类是审查重点,4条红线最好别踩。

最强开源文生图模型一夜易主! 智东西8月2日报道,昨日晚间,开源文生图模型霸主Stable Diffusion原班人马,宣布推出全新的图像生成模型FLUX.1。

7 月,大模型公司 Cohere 宣布 D 轮融资 5 亿美元,估值 55 亿,比去年高了一倍多。 跟 OpenAI、Anthropic 甚至法国 AI 公司 Mistral 相比,成立于加拿大的 Cohere 略显低调,没有推出自己的 Chatbot、文生图或者文生视频产品,不涉足个人消费端产品;即使是推出的开源大模型 Command R+,似乎也没有那么引人注意。