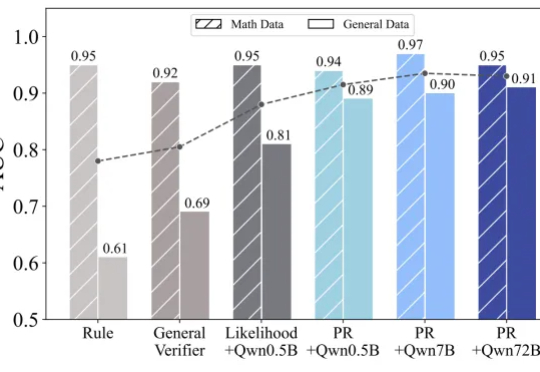
突破通用领域推理的瓶颈!清华NLP实验室强化学习新研究RLPR
突破通用领域推理的瓶颈!清华NLP实验室强化学习新研究RLPRDeepseek 的 R1、OpenAI 的 o1/o3 等推理模型的出色表现充分展现了 RLVR(Reinforcement Learning with Verifiable Reward
来自主题: AI技术研报
10689 点击 2025-06-27 10:03
 搜索
搜索
Deepseek 的 R1、OpenAI 的 o1/o3 等推理模型的出色表现充分展现了 RLVR(Reinforcement Learning with Verifiable Reward
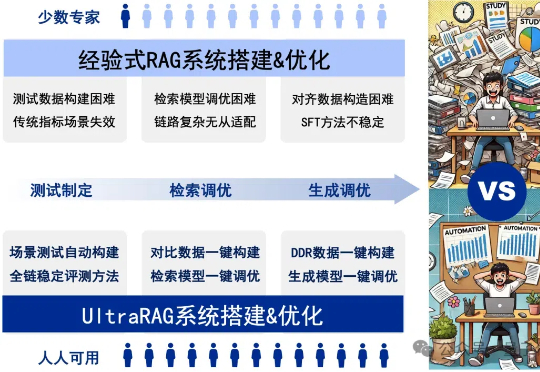
RAG系统的搭建与优化是一项庞大且复杂的系统工程,通常需要兼顾测试制定、检索调优、模型调优等关键环节,繁琐的工作流程往往让人无从下手。

挖掘大模型固有的长文本理解能力,InfLLM在没有引入额外训练的情况下,利用一个外部记忆模块存储超长上下文信息,实现了上下文长度的扩展。
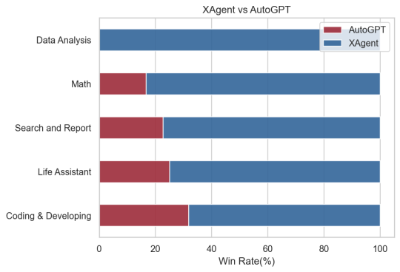
国内领先的人工智能大模型公司面壁智能又放大招,联合清华大学 NLP 实验室共同研发并推出大模型「超级英雄」——XAgent。