
AI 会替代产品经理吗?答案藏在这份白皮书里
AI 会替代产品经理吗?答案藏在这份白皮书里清华互联网产品研究协会(五道口产品观察)联合特工宇宙,从现状痛点到落地实践,再到职业进化路径,万字白皮书拆解 AI 与产品工作的适配方式,助力突破 AI 使用困局。
来自主题: AI技术研报
10939 点击 2025-09-26 11:22
 搜索
搜索
清华互联网产品研究协会(五道口产品观察)联合特工宇宙,从现状痛点到落地实践,再到职业进化路径,万字白皮书拆解 AI 与产品工作的适配方式,助力突破 AI 使用困局。
扎克伯格又从 OpenAI 挖走了一位华人科学家,而且这位称得上是「超级大脑」。本周四午间传来消息,原 OpenAI 战略探索团队负责人宋飏(Yang Song)加入 Meta,他成为了新成立的 Meta 超级智能实验室(MSL)研究负责人。

医学研究迎来“零人工”时代了?!清华大学自动化系索津莉课题组,发布首个专为医疗信息学设计的全自主AI研究框架——OpenLens AI。首次实现从文献挖掘→实验设计→数据分析→代码生成→可投稿论文的全链条自动化闭环。
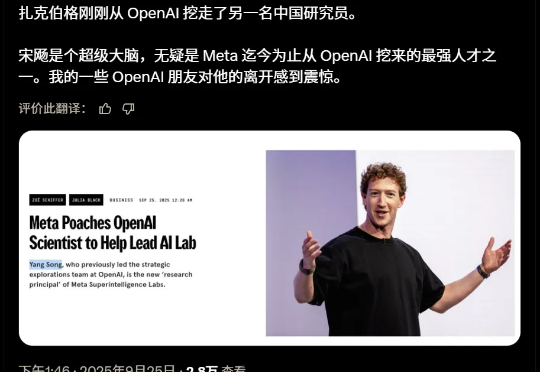
刚刚,Meta又从OpenAI挖来一员猛将——宋飏,扩散模型领域的核心人物,DALL·E 2技术路径的早期奠基者。他已正式加入Meta Superintelligence Labs,担任研究负责人,直接向他的师兄赵晟佳汇报。

阿里巴巴集团安全部联合清华大学、复旦大学、东南大学、新加坡南洋理工等高校,联合发布技术报告;其理念与最近OpenAI发布的GPT-5 System Card放在首位的“From Hard Refusals to Safe-Completions”理念不谋而合。
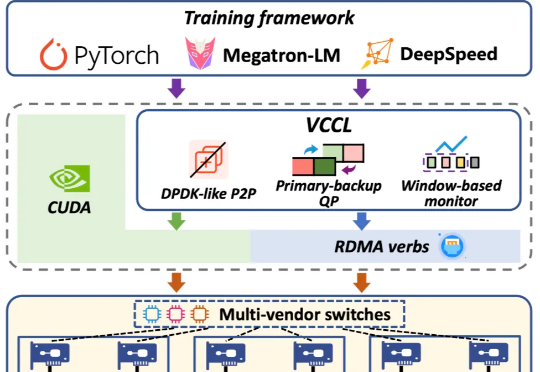
创智、基流、智谱、联通、北航、清华、东南联合打造了高效率、高可靠、高可视的 GPU 集合通信库 VCCL(Venus Collective Communication Library),VCCL 已部署于多个生产环境集群中。
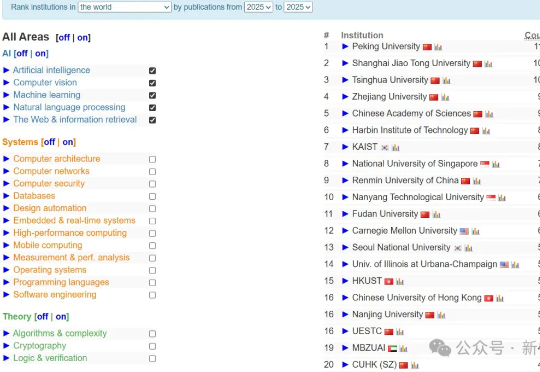
2025 CSRankings刚刚更新,清华登顶世界第一!此次更新最大看点是中国高校集体爆发:清华大学、上海交通大学、浙江大学、北京大学分列第1、3、4、5位,直接占据了TOP 5中的4个名额。

近年来,大语言模型(LLMs)在复杂推理任务上的能力突飞猛进,这在很大程度上得益于深度思考的策略,即通过增加测试时(test-time)的计算量,让模型生成更长的思维链(Chain-of-Thought)。

我们是由清华大学、北京大学、东京大学、南洋理工大学等海内外名校毕业生,融合计算机、金融等学科背景成员组成的互联网初创团队。目前正在做的是一款Ai+东方命理学的软件,名为 信风Flow 。
AGI真正降临那天,人类意识上传终获「数字永生」!它将模拟大脑每一次脉冲,预测世界每一种变迁,甚至重构灵魂本质。新智元十周年峰会上,清华刘嘉教授带来了一场思想盛宴。他从脑科学角度,深入解析AGI如何突破生物桎梏,开启无限的可能。