
字节前技术负责人创业,联手清华姚班校友,编程智能体世界登顶
字节前技术负责人创业,联手清华姚班校友,编程智能体世界登顶来自中国的初创团队词元无限给出了自己的答案。由清华姚班校友带队设计开发的编码智能体 InfCode,在 SWE-Bench Verified 和 Multi-SWE-bench-CPP 两项非常权威的 AI Coding 基准中双双登顶,力压一众编程智能体。
来自主题: AI资讯
10933 点击 2025-12-05 14:51
 搜索
搜索
来自中国的初创团队词元无限给出了自己的答案。由清华姚班校友带队设计开发的编码智能体 InfCode,在 SWE-Bench Verified 和 Multi-SWE-bench-CPP 两项非常权威的 AI Coding 基准中双双登顶,力压一众编程智能体。
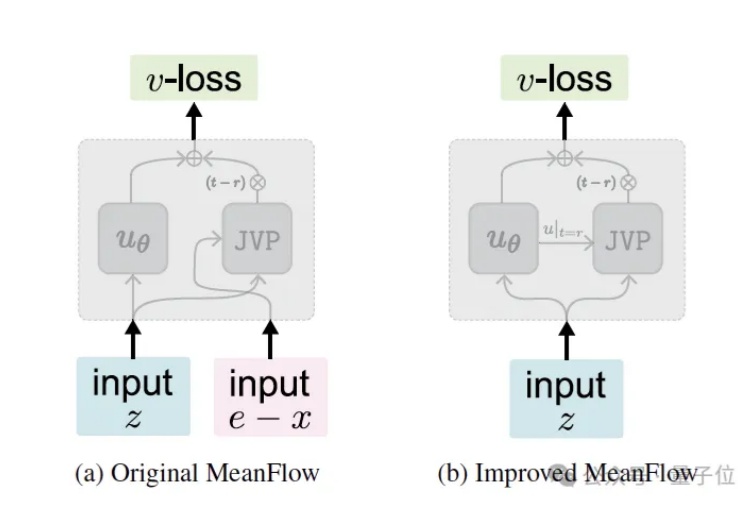
继今年5月提出MeanFlow (MF) 之后,何恺明团队于近日推出了最新的改进版本—— Improved MeanFlow (iMF),iMF成功解决了原始MF在训练稳定性、指导灵活性和架构效率上的三大核心问题。

叶问蹲、跳舞、跑步,一个策略全搞定!

近日,清华大学深圳国际研究生院的机器人博士团队创办的「知有无界」获得卓源亚洲领投、力合科创跟投的种子轮融资。「知有无界」诞生在清华大学王学谦教授的智能机器人实验室,实现了全球首个船舶具身通用大模型,本轮融资后,「知有无界」将会进一步加快在船坞的商业化落地,并持续进行多代产品的研发。

arXiv最新政策禁止直接接收未经同行评审的综述和立场论文,以应对AI生成论文的泛滥,但堵不如疏。多伦多大学、清华、北大等18所国内外顶尖高校联合发布新平台aiXiv,支持AI和人类共同撰写、评审和迭代科研成果,采用多阶段AI同行评审机制,提升效率和质量。

具身智能,火得有些过分, 就在昨天,清华大学宣布成立具身智能与机器人研究院。

硬氪获悉,北京他山科技有限公司(以下简称“他山科技”)在一个季度内密集完成A3轮与A4轮融资,两轮融资总额约数亿元。我们总结了最新两轮融资信息和该公司几大亮点:

成立两年半,再添近5亿元A+轮融资—— 截至目前,无问芯穹已累计吸金近15亿,成为AI基础设施领域最受资本追捧的“黑马”企业之一。

当元宇宙数字人急需「群舞技能」,音乐驱动生成技术却遭遇瓶颈——舞者碰撞、动作僵硬、长序列崩坏。为解决这些难题,南理工、清华、南大联合研发端到端模型TCDiff++,突破多人生成技术壁垒,实现高质量、长时序的群体舞蹈自动生成。

前些天,一项「AI 传心术」的研究在技术圈炸开了锅:机器不用说话,直接抛过去一堆 Cache 就能交流。让人们直观感受到了「去语言化」的高效,也让机器之心那条相关推文狂揽 85 万浏览量。参阅报道《用「传心术」替代「对话」,清华大学联合无问芯穹、港中文等机构提出 Cache-to-Cache 模型通信新范式》。