
2026年AAAI Fellow名单出炉!清华校友田奇等4位华人学者入选
2026年AAAI Fellow名单出炉!清华校友田奇等4位华人学者入选一年一度的AAAI Fellow计划又成为了人工智能领域大家关注的焦点。本次发布的2026年名单中,共有12位知名学者当选,其中包含了四位著名华人学者。
来自主题: AI资讯
8463 点击 2026-01-06 16:17
 搜索
搜索
一年一度的AAAI Fellow计划又成为了人工智能领域大家关注的焦点。本次发布的2026年名单中,共有12位知名学者当选,其中包含了四位著名华人学者。
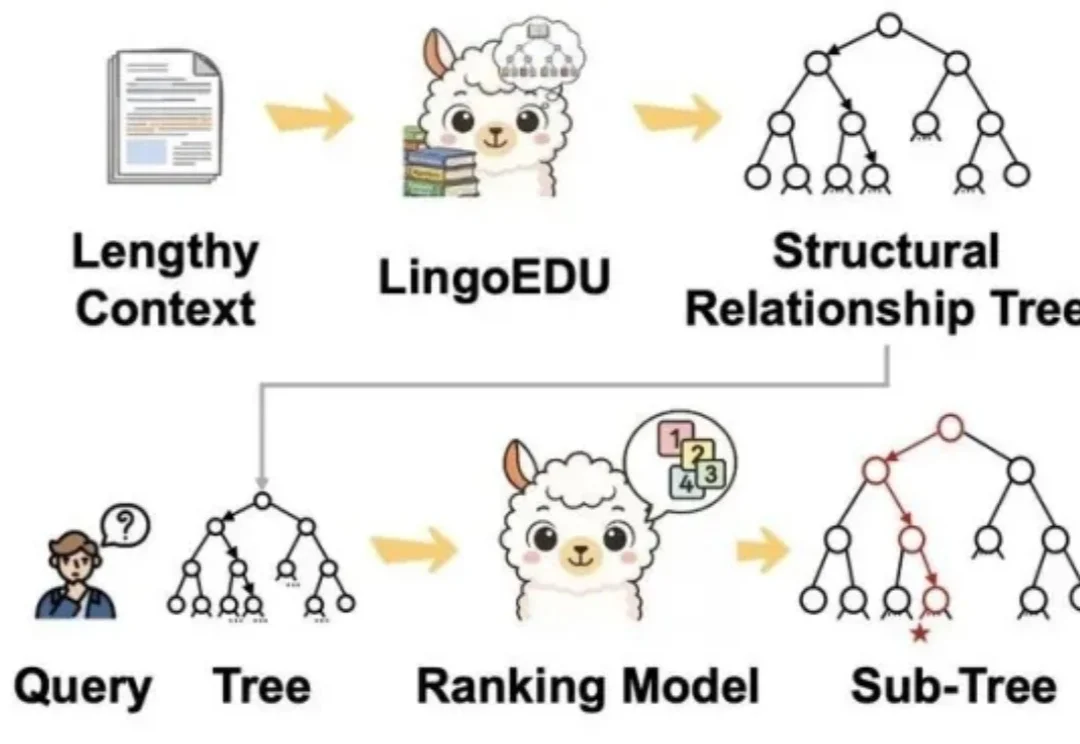
零成本降低大模型幻觉新方法,让DeepSeek准确率提升51%!

作为一名 AI 领域的博士生,徐玉庄的经历比较特殊。本科毕业于国防科技大学,随后在部队工作了 5 年,接着在清华大学获得硕士学位,目前在哈尔滨工业大学读博。
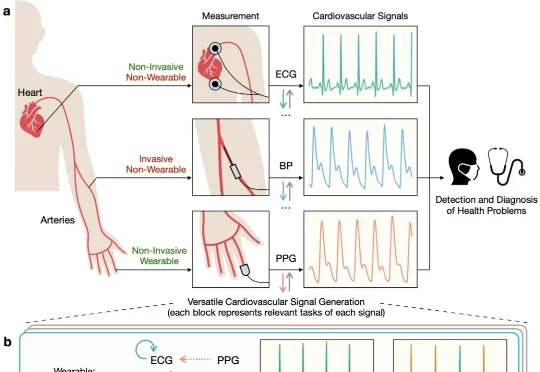
近日,清华朱军等团队提出了一种统一的多模态生成框架 UniCardio,在单扩散模型中同时实现了心血管信号的去噪、插补与跨模态生成,为真实场景下的人工智能辅助医疗提供了一种新的解决思路。

清华大学等多所高校联合发布SR-LLM,这是一种融合大语言模型与深度强化学习的符号回归框架。它通过检索增强和语义推理,从数据中生成简洁、可解释的数学模型,显著优于现有方法。在跟车行为建模等任务中,SR-LLM不仅复现经典模型,还发现更优新模型,为机器自主科学发现开辟新路径。
。过去的行业共识是:端侧只能跑小模型,性能与体验必须妥协;真正的能力仍得依赖云端最强模型。万格智元要打破的,正是这条旧认知。公司正在打造的cPilot端侧算力引擎,选择了一条更难、却更接近未来的路径:通过自研的非GPU推理引擎,让300亿、500亿等超大模型在性能有限制的消费硬件上高效推理

最近,清华大学教授、智谱AI首席科学家唐杰发了一条长微博,总结了自己2025年对大模型进展的感悟。从预训练到中后训练、长尾场景的对齐能力,再到Agent、多模态和具身智能的发展,其中有不少亮点。
现在生成一个视频,比你刷视频还要快。

CyboPal ONE 尝试告诉用户,未来硬件不应只是被动、静止的容器,而应是具有‘代理权(Agency)’的主动生命体。”

视频生成领域的「DeepSeek时刻」来了!清华开源TurboDiffusion,将AI视频生成从「分钟级」硬生生拉进「秒级」实时时代,单卡200倍加速让普通显卡也能跑出大片!