
林俊旸创业,新公司估值约20亿美金丨智能涌现独家
林俊旸创业,新公司估值约20亿美金丨智能涌现独家独家获悉,前阿里千问大模型技术负责人林俊旸近期已经开启创业,考虑方向包括世界模型和具身大脑。目前,林俊旸已经招募数名字节、腾讯和海外背景的成员,并以约20亿美金的估值开启融资,接触基金包括红杉中国、高榕创投等。
来自主题: AI资讯
8675 点击 2026-05-13 16:47
 搜索
搜索
独家获悉,前阿里千问大模型技术负责人林俊旸近期已经开启创业,考虑方向包括世界模型和具身大脑。目前,林俊旸已经招募数名字节、腾讯和海外背景的成员,并以约20亿美金的估值开启融资,接触基金包括红杉中国、高榕创投等。

视频创作正在从操作工具,变成一场人与Agent之间的对话。
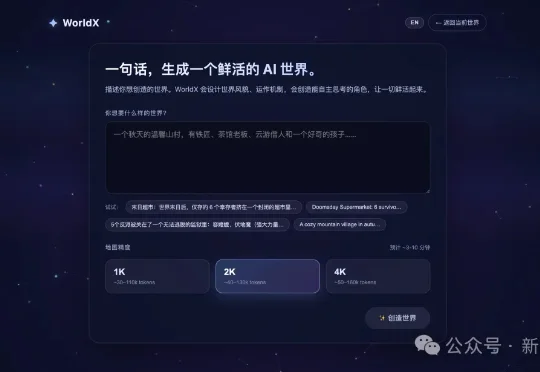
2023年斯坦福「AI小镇」火了,后续也诞生了大量类似的热门项目,但所有这类项目都有一个共同瓶颈——世界是人工搭建的,固定的。最近,一位独立开发者用10天婚假爆肝了一个项目WorldX:输入一句话、5分钟,一个完整的AI世界就诞生了——地图、角色、动画、人设全部自动生成,AI角色们自主在其中生活、对话、形成记忆、产生戏剧性的涌现行为。

近期,一个叫“同事.skill”的GitHub项目5天收获超过6600颗星,冲上热搜。紧接着,“前任.skill”“老板.skill”“父母.skill”十余个衍生项目接连涌现。网友辣评:“同事,散是Token,聚是Skill。”
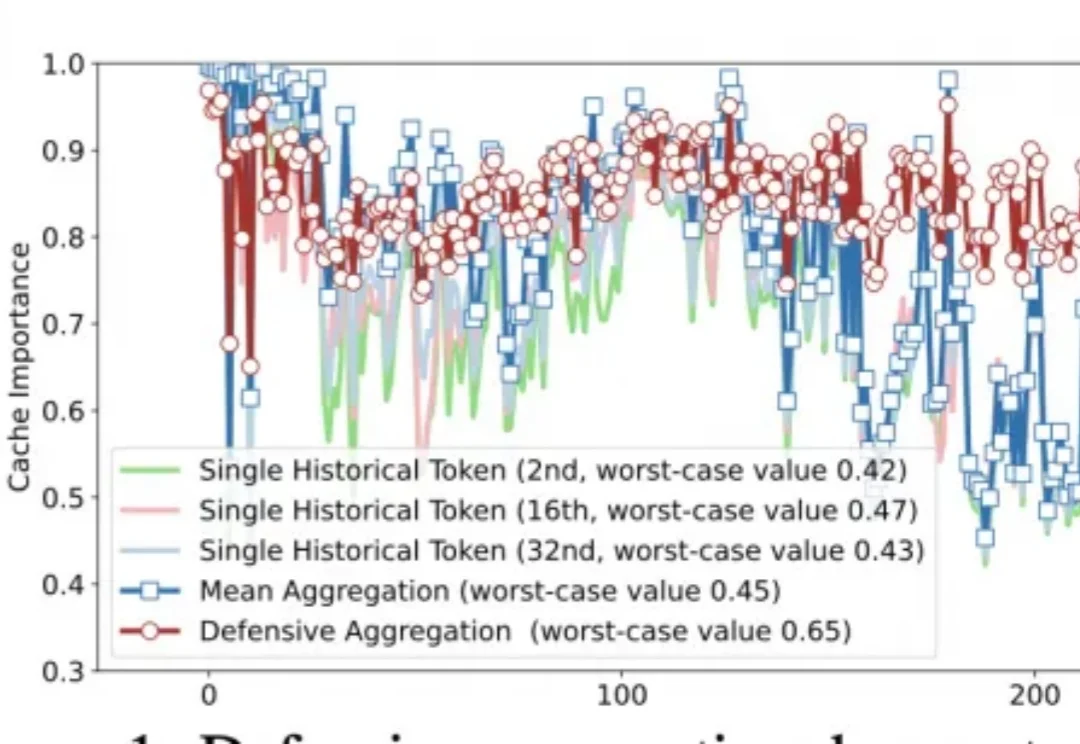
随着大模型长上下文能力快速增长,海量 KV Cache 存储需求急剧增加,各类 KV Cache 压缩方法如雨后春笋般涌现。然而,这些方案在真实场景中的工程落地却常常陷入困境。

最近AI自媒体开始踊跃讨论各种英文技术名词的中文新译法。Token的新译法纷纷涌现:灵符、模元、信符、道元、智筹、智元、智根、偷啃……

据接近腾讯混元团队的知情人士透露,原字节Seed视觉AI平台团队负责人肖学锋,Infra团队张弛于近期低调入职腾讯,负责大模型Infra相关工作,向腾讯首席AI科学家姚顺雨汇报。
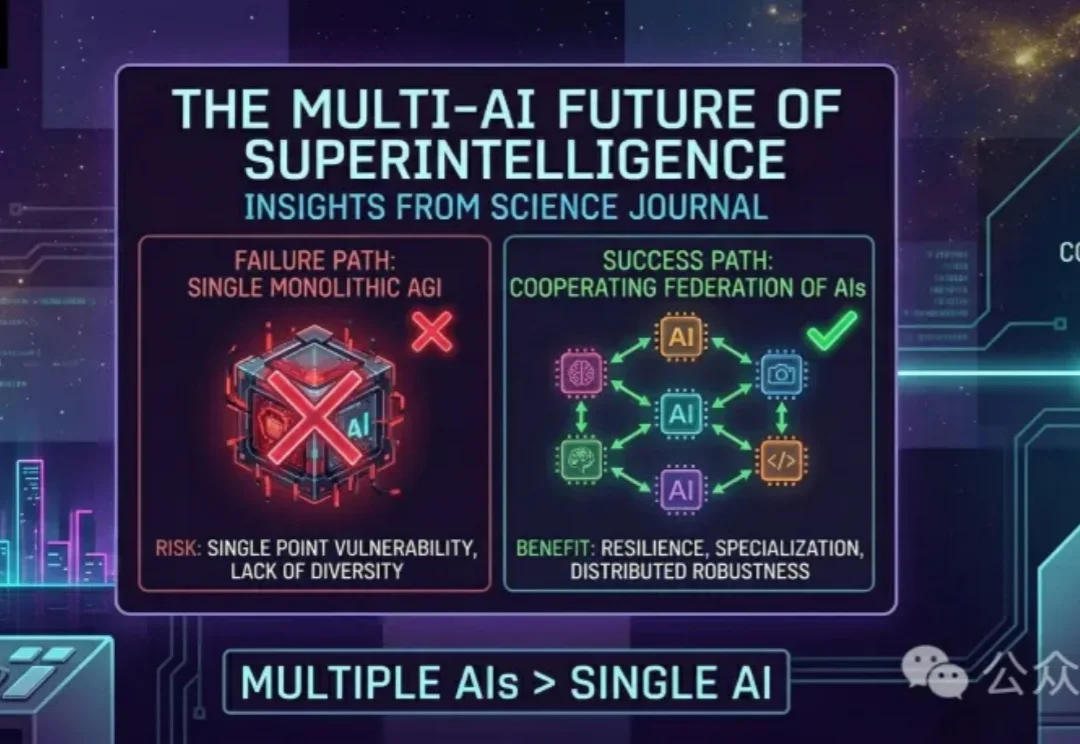
Science 最新论文颠覆「技术奇点」叙事:真正的智能爆炸已在发生,但它不是孤独超级大脑的降临,而是人与 AI 深度缠绕的社会性跃迁。推理模型内部自发涌现出「思想社会」,人机混合的「半人马时代」已然开启。问题从不是奇点会不会到来,而是我们能否建起与之匹配的社会基础设施。

随着龙虾OpenClaw热潮持续,复杂的云端部署已经无法满足用户的需求,尤其是最近两周,涌现出了大量在原OpenClaw基础上定制的新产品,其中很多已经实现了应用化,用户只需要点击下载注册应用就能够体验OpenClaw的部分功能。

导读:近日,位于中关村的深度机智全球首次使用全新范式——人类学习,在多个国际 Benchmark 上取得 SOTA,史无前例地使用全新架构(仅使用人类第一视角数据、零真机数据)击败 Physical Intelligence 和英伟达等头部巨头二十多个百分点,并在两会开幕首日被央视报道。