
1080p飞升4k,浙大开源原生超高清视频生成方案,突破AI视频生成清晰度上限
1080p飞升4k,浙大开源原生超高清视频生成方案,突破AI视频生成清晰度上限为什么AI生成的视频总是模糊卡顿?为什么细节纹理经不起放大?为什么动作描述总与画面错位?
来自主题: AI技术研报
9083 点击 2025-07-01 15:08
 搜索
搜索
为什么AI生成的视频总是模糊卡顿?为什么细节纹理经不起放大?为什么动作描述总与画面错位?

扎克伯格又从奥特曼手里挖走4名顶尖AI人才,这次四位都是华人研究员。

具身智能领域,是不是够火爆了?

面对Ai,我们开始感到,无趣了,甚至,失去了原本的那股劲头。

5月15日晚,区瀚楠、陈睿轩走进了上海浦东的一栋民宿。 这里没有食物、没有智能手机、没有浏览器、没有APP,只有一台预装AI工具的联网电脑、一部非智能手机、一瓶饮用水和100元生存资金,他们将在这个封闭房间里依靠AI工具生存72小时。

过去一段时间,“通用 Agent”成了 AI 应用的默认发展方向。无论产品叙事还是技术布局,大家似乎都在追求一个“什么都能做”的智能体。但现实逐渐显露:通用 Agent 在真实世界中并不那么“通用”。
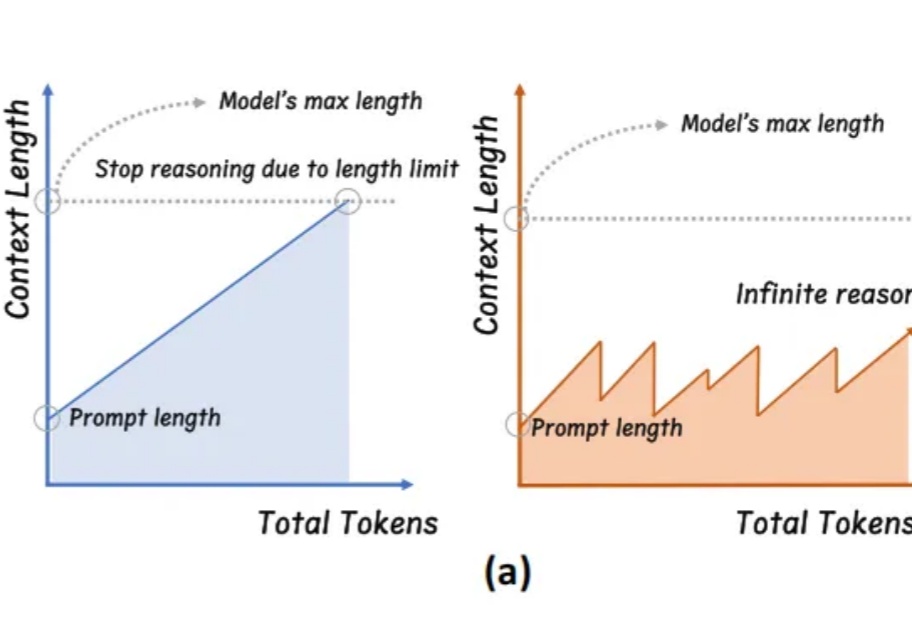
学会“适当暂停与总结”,大模型终于实现无限推理。

如果你面前有两个AI助手:一个能力超强却总爱“离经叛道”,另一个规规矩矩却经常“答非所问”,你会怎么选?

杯子在我的左边还是右边?

复刻DeepSeek-R1的长思维链推理,大模型强化学习新范式RLIF成热门话题。