
机器人WAIC现场抢活讲PPT?商汤悟能具身智能平台让机器人「觉醒」
机器人WAIC现场抢活讲PPT?商汤悟能具身智能平台让机器人「觉醒」如今的具身智能,早已爆红AI圈。数据瓶颈、难以多场景泛化等难题,一直困扰着业界的玩家们。就在WAIC上,全新具身智能平台「悟能」登场了。它以世界模型为引擎,能为机器人提供强大感知、导航、多模态交互能力。
来自主题: AI资讯
6583 点击 2025-07-28 17:36
 搜索
搜索
如今的具身智能,早已爆红AI圈。数据瓶颈、难以多场景泛化等难题,一直困扰着业界的玩家们。就在WAIC上,全新具身智能平台「悟能」登场了。它以世界模型为引擎,能为机器人提供强大感知、导航、多模态交互能力。

机器人能通过普通视频来学会实际物理操作了! 来看效果,对于所有没见过的物品,它能精准识别并按照指令完成动作。
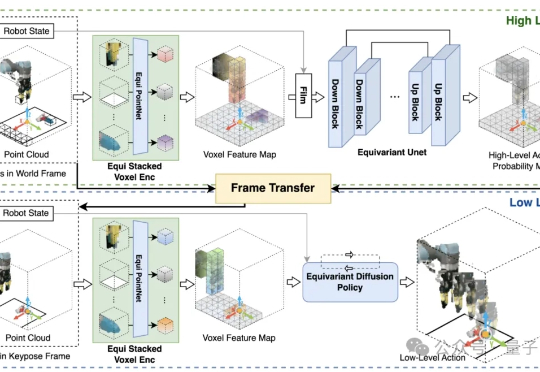
如何让AI像人一样,仅凭少量演示,就能稳健适应复杂多变的真实场景? 美国东北大学和波士顿动力RAI提出了HEP(Hierarchical Equivariant Policy via Frame Transfer)框架,首创“坐标系转移接口”,让机器人学习更高效、泛化更灵活。

现有视频异常检测(Video Anomaly Detection, VAD)方法中,有监督方法依赖大量领域内训练数据,对未见过的异常场景泛化能力薄弱;而无需训练的方法虽借助大语言模型(LLMs)的世界知识实现检测,但存在细粒度视觉时序定位不足、事件理解不连贯、模型参数冗余等问题。

还在担心机器人只能机械执行、不会灵活应变?
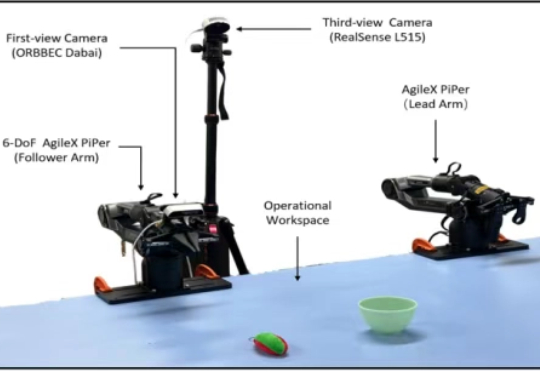
近年来,视觉 - 语言 - 动作(Vision-Language-Action, VLA)模型因其出色的多模态理解与泛化能力,已成为机器人领域的重要研究方向。尽管相关技术取得了显著进展,但在实际部署中,尤其是在高频率和精细操作等任务中,VLA 模型仍受到推理速度瓶颈的严重制约。
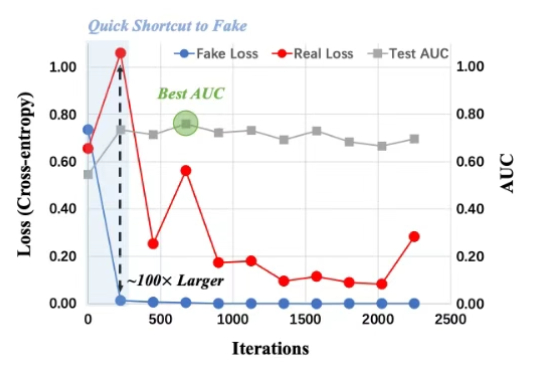
随着 OpenAI 推出 GPT-4o 的图像生成功能,AI 生图能力被拉上了一个新的高度,但你有没有想过,这光鲜亮丽的背后也隐藏着严峻的安全挑战:如何区分生成图像和真实图像?

中国人民大学高瓴人工智能学院的研究团队提出通过创新模型架构来提升性能,其SPACE模型引入新架构,提升了DNA基础模型的性能与泛化能力,在多项测试中表现优异。

MoCa框架把单向视觉语言模型转化为双向多模态嵌入模型,通过持续预训练和异构对比微调,提升模型性能和泛化能力,在多模态基准测试中表现优异,尤其小规模模型性能突出。
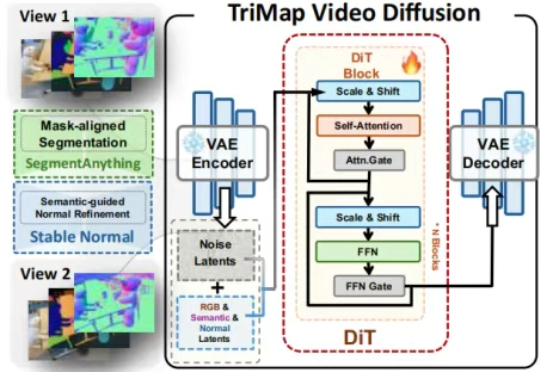
最少只用2张图,AI就能像人类一样理解3D空间了。ICCV 2025最新中稿的LangScene-X:以全新的生成式框架,仅用稀疏视图(最少只用2张图像)就能构建可泛化的3D语言嵌入场景,对比传统方法如NeRF,通常需要20个视角。