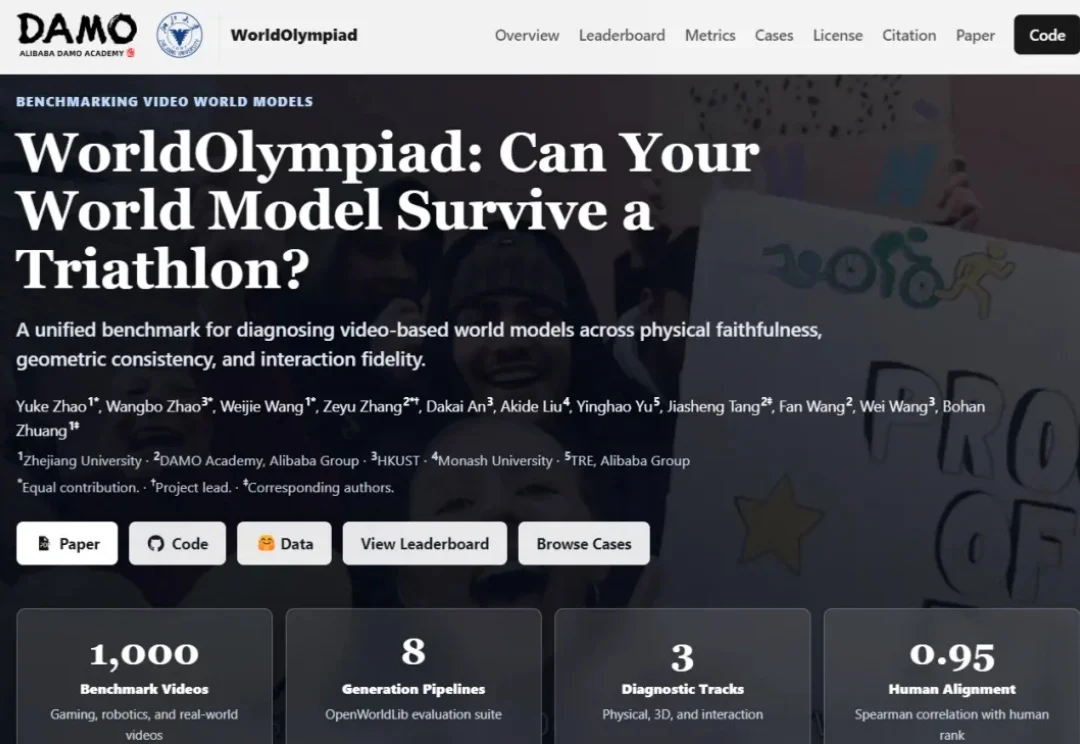
达摩院发布世界模型评测基准,自家模型一个都没上榜......
达摩院发布世界模型评测基准,自家模型一个都没上榜......达摩院联合高校推出WorldOlympiad评测基准,跳出传统视频“唯画质”的评价逻辑,以物理真实性、三维几何一致性、长时序交互保真度三大维度,搭配游戏、机器人、通用实景三大场景,打造一套全方位的视频世界模型评测体系。
来自主题: AI技术研报
9080 点击 2026-06-17 14:28
 搜索
搜索
达摩院联合高校推出WorldOlympiad评测基准,跳出传统视频“唯画质”的评价逻辑,以物理真实性、三维几何一致性、长时序交互保真度三大维度,搭配游戏、机器人、通用实景三大场景,打造一套全方位的视频世界模型评测体系。
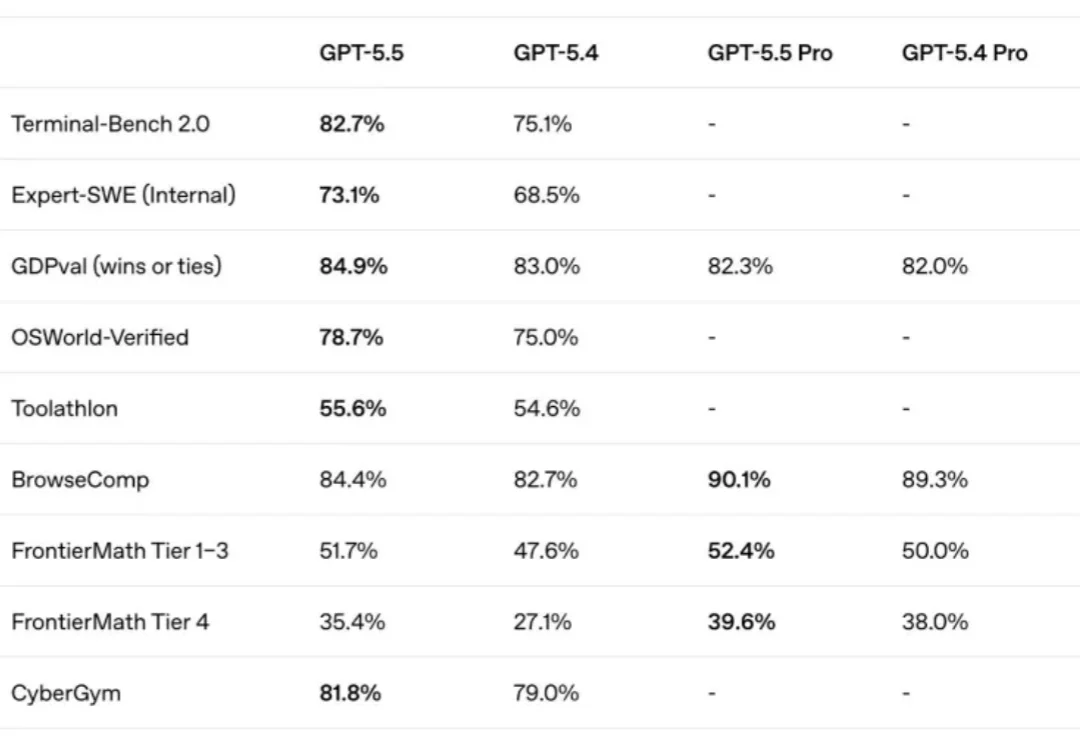
随着大语言模型逐步进入复杂推理、自动化研究和网络安全等高难度任务,传统的模型评测方式正在面临新的挑战。

真实世界需要 200 多个小时的模型评测任务,可以在仿真中不到 0.5 小时内完成。

从去年开始做这个账号以来,我其实写过不少测模型的文章。我相信也有很多朋友是因为看了我测评的文章关注我的。但从过年之后,真的就很少写模型评测的文章了。主要是我写文章的速度甚至一度跟不上模型发布的速度了。
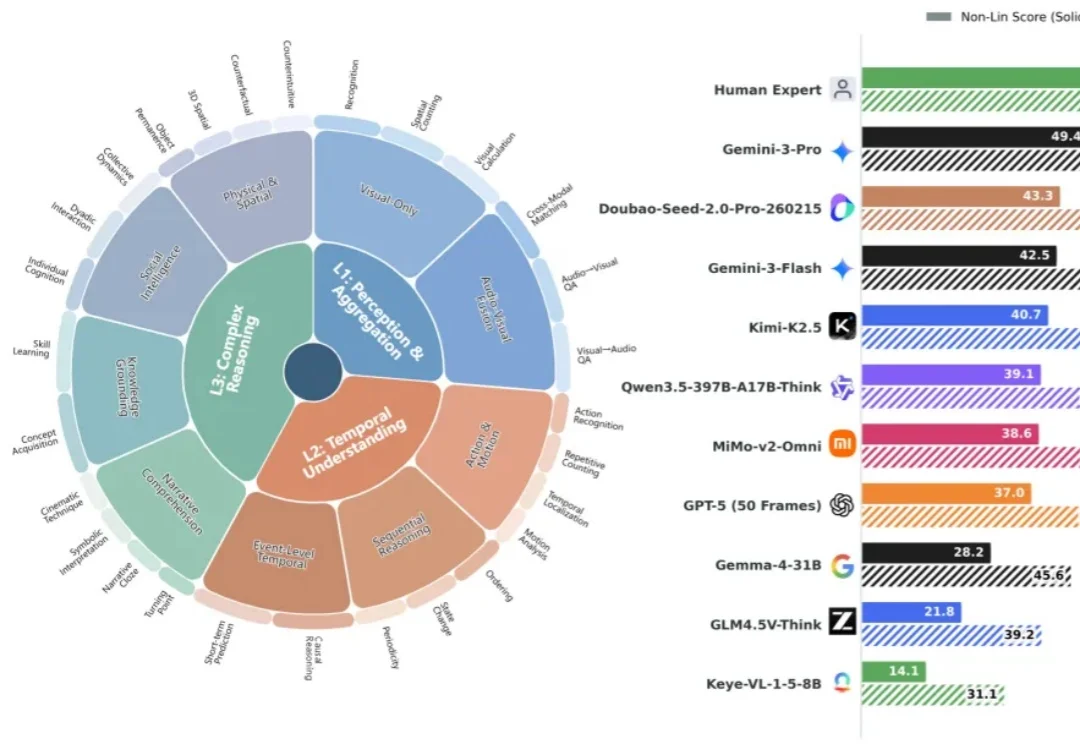
现有大模型评测分数日趋饱和,但与真实体验差距显著。南京大学傅朝友团队牵头,在 Google Gemini 评测团队邀约下推出视频理解新基准 Video-MME-v2。凭借创新的分层能力体系与组级非线性评分,以及 3300 + 人工时高质量标注,揭示模型与人类的巨大鸿沟(49 vs 90)、传统 Acc 指标虚高、以及 “Thinking” 并非总是增益等现象。

现有大模型评测分数日趋饱和,但与真实体验差距显著。南京大学傅朝友团队牵头,在Google Gemini评测团队邀约下推出视频理解新基准Video-MME-v2。凭借创新的分层能力体系与组级非线性评分,以及3300+人工时高质量标注,揭示模型与人类的巨大鸿沟(49vs90)、传统Acc指标虚高、以及「Thinking」并非总是增益等现象。
通用世界模型评测榜单 WorldScore 登顶、建立具身世界模型评测榜单 WorldArena 、发布通用世界模型 WorldScape 、发布世界-动作模型 WorldScape Policy,这家低调的世界模型创业公司 Manifold AI(流形空间)近期走出隐身模式频频出手,开始领跑世界-动作模型具身新路线。
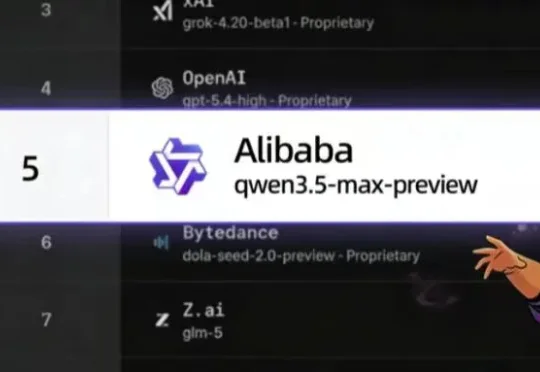
今日,阿里千问最新旗舰模型预览版Qwen3.5-Max-Preview正式亮相,并登上全球大模型评测平台LMArena。在最新榜单中,该模型拿下1464分,进入第一梯队,同时带动阿里千问跻身全球大模型实验室前五、国内第一。
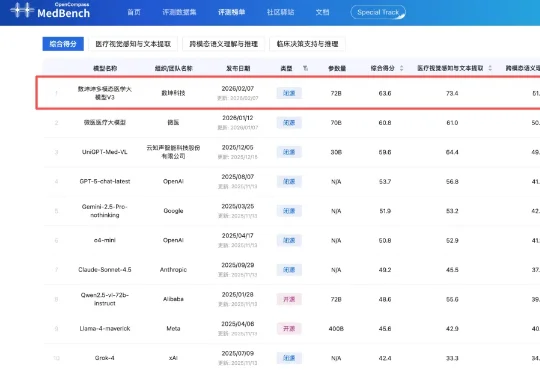
2月7日,中文医疗大模型评测平台MedBench公布最新多模态大模型评测榜单,数坤科技的数坤坤多模态医学大模型V3以63.6分拿下第一。在榜单中,V3的表现超过微医、云知声旗下医疗行业大模型,以及OpenAI、谷歌、阿里千问旗下通用大模型。

Anthropic的新模型要来了!代号Fennec的Claude Sonnet 5马上要发布,性能吊打市面上所有编程大模型,价格还砍掉50%,还能比肩一整个人类开发团队,可以说达到编程领域的巅峰。