最强大模型训练芯片H200发布!141G大内存,AI推理最高提升90%,还兼容H100
最强大模型训练芯片H200发布!141G大内存,AI推理最高提升90%,还兼容H100英伟达老黄,带着新一代GPU芯片H200再次炸场。官网毫不客气就直说了,“世界最强GPU,专为AI和超算打造”。
来自主题: AI资讯
5353 点击 2023-11-14 10:09
 搜索
搜索
英伟达老黄,带着新一代GPU芯片H200再次炸场。官网毫不客气就直说了,“世界最强GPU,专为AI和超算打造”。

有一家公司,OpenAI、Anthropic、Cohere、Aleph Alpha(欧洲顶尖大模型公司)和Hugging Face的模型训练和微调都离不开它,NVIDIA和谷歌云(GCP)都是它的深度合作伙伴,它是支持生成式AI明星公司们训练模型的幕后英雄。

即便大语言模型的参数规模日渐增长,其模型中的参数到底是如何发挥作用的还是让人难以琢磨,直接对大模型进行分析又费钱费力。针对这种情况,微软的两位研究员想到了一个绝佳的切入点

相比于一味规避“有毒”数据,以毒攻毒,干脆给大模型喂点错误文本,再让模型剖析、反思出错的原因,反而能够让模型真正理解“错在哪儿了”,进而避免胡说八道。

大型语言模型能力惊人,但在部署过程中往往由于规模而消耗巨大的成本。华盛顿大学联合谷歌云计算人工智能研究院、谷歌研究院针对该问题进行了进一步解决,提出了逐步微调(Distilling Step-by-Step)的方法帮助模型训练。

而在AI大模型的相关市场竞争中,除了底层的算法、架构外,“语料”则是一个被反复提及的关键要素。
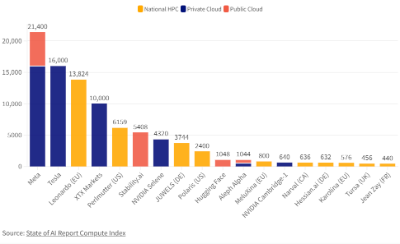
在高性能计算(HPC)、人工智能(AI)、和数据分析等领域,图形处理器(GPUs)正在发挥越来越重要的作用。其中,NVIDIA的 A100尤为引人注目。这是英伟达最强大的显卡处理器,也是当前使用最广泛大模型训练用的显卡。