OpenAI超级对齐团队遗作:两个大模型博弈一番,输出更好懂了
OpenAI超级对齐团队遗作:两个大模型博弈一番,输出更好懂了OpenAI超级对齐团队遗作:两个大模型博弈一番,输出更好懂了
来自主题: AI资讯
6921 点击 2024-07-18 16:51
 搜索
搜索
OpenAI超级对齐团队遗作:两个大模型博弈一番,输出更好懂了
离开快手创业后,「李岩」悄悄拿到了快手联合创始人宿华、红点创投以及经纬创投的3200万美金种子轮融资。

只需激活60%的参数,就能实现与全激活稠密模型相当的性能。

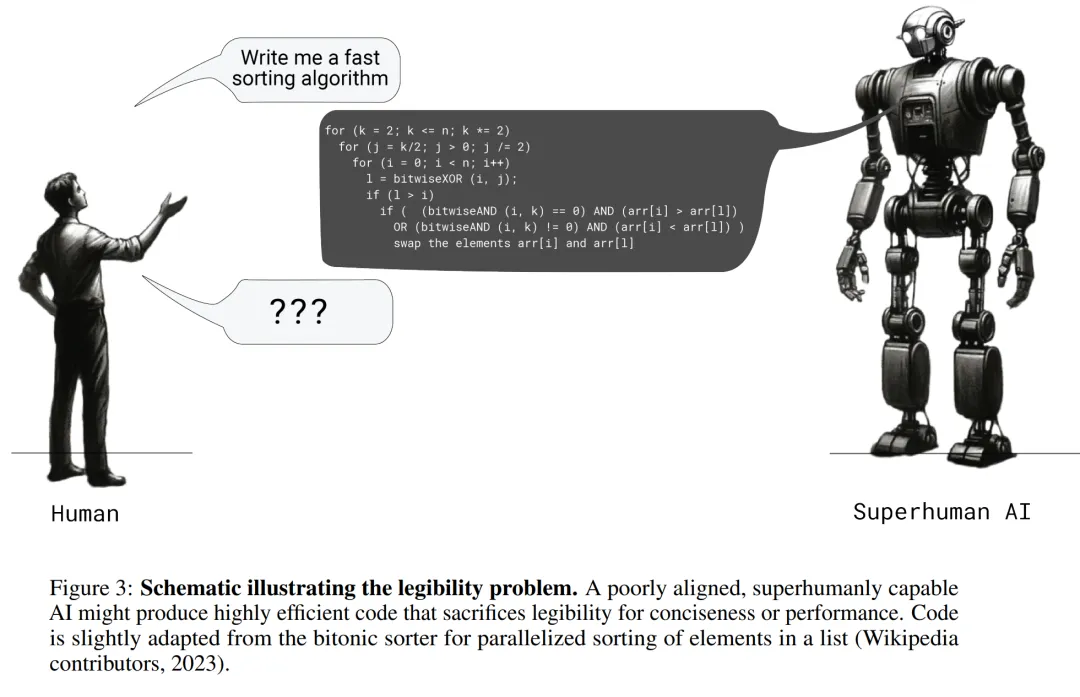
让大小模型相互博弈,就能实现生成内容可读性的提升!

当我们不停在CoT等领域大下苦功、试图提升LLM推理准确性的同时,OpenAI的对齐团队从另一个角度发现了华点——除了准确性,生成答案的清晰度、可读性和可验证性也同样重要。

自回归解码已经成为了大语言模型(LLMs)的事实标准,大语言模型每次前向计算需要访问它全部的参数,但只能得到一个token,导致其生成昂贵且缓慢。

视频生成也能参考“上下文”?!
AI侵权又来了……
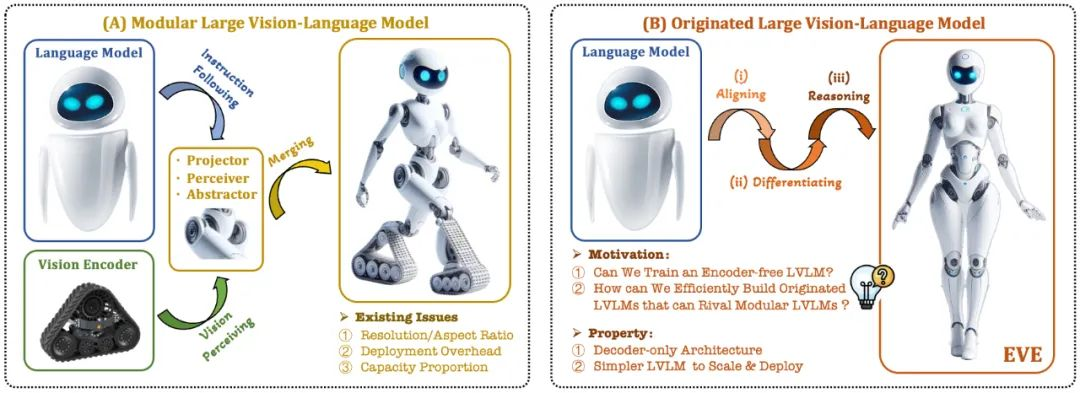
近期,关于多模态大模型的研究如火如荼,工业界对此的投入也越来越多。

假如你有闲置的设备,或许可以试一试。