
LoRA综述来了! 浙大《大语言模型的LoRA研究》综述
LoRA综述来了! 浙大《大语言模型的LoRA研究》综述低秩适应(Low-Rank Adaptation,LoRA)通过可插拔的低秩矩阵更新密集神经网络层,是当前参数高效微调范式中表现最佳的方法之一。此外,它在跨任务泛化和隐私保护方面具有显著优势。
来自主题: AI技术研报
12533 点击 2024-07-21 14:02
 搜索
搜索
低秩适应(Low-Rank Adaptation,LoRA)通过可插拔的低秩矩阵更新密集神经网络层,是当前参数高效微调范式中表现最佳的方法之一。此外,它在跨任务泛化和隐私保护方面具有显著优势。

Scaling Laws当道,但随着大模型应用的发展,基础模型不断扩大的参数也成了令开发者们头疼的问题。

AI经过多轮“自我提升”,能力不增反降?
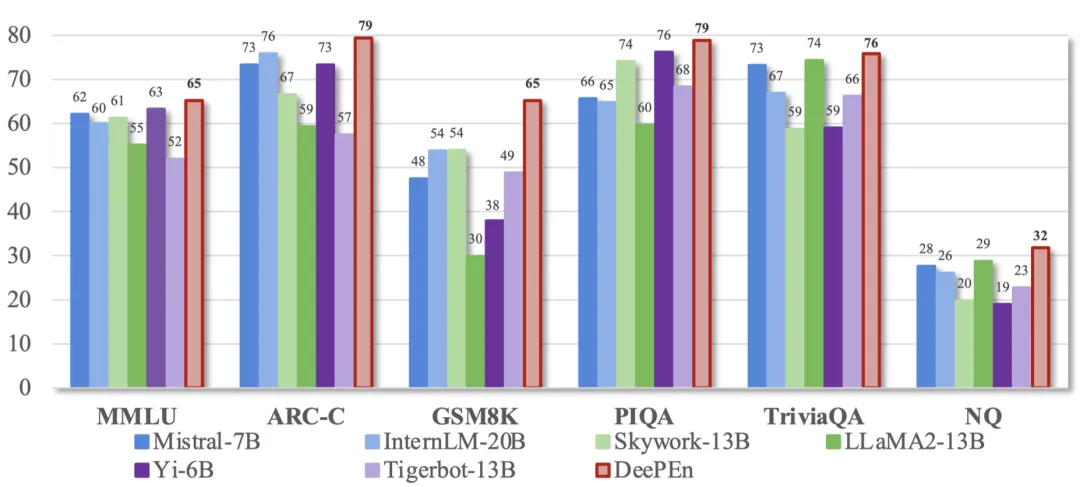
随着大语言模型展现出惊人的语言智能,各大 AI 公司纷纷推出自己的大模型。这些大模型通常在不同领域和任务上各有所长,如何将它们集成起来以挖掘其互补潜力,成为了 AI 研究的前沿课题。

MoE 因其在训推流程中低销高效的特点,近两年在大语言模型领域大放异彩。作为 MoE 的灵魂,专家如何能够发挥出最大的学习潜能,相关的研究与讨论层出不穷。此前,华为 GTS AI 计算 Lab 的研究团队提出了 LocMoE ,包括新颖的路由网络结构、辅助降低通信开销的本地性 loss 等,引发了广泛关注。
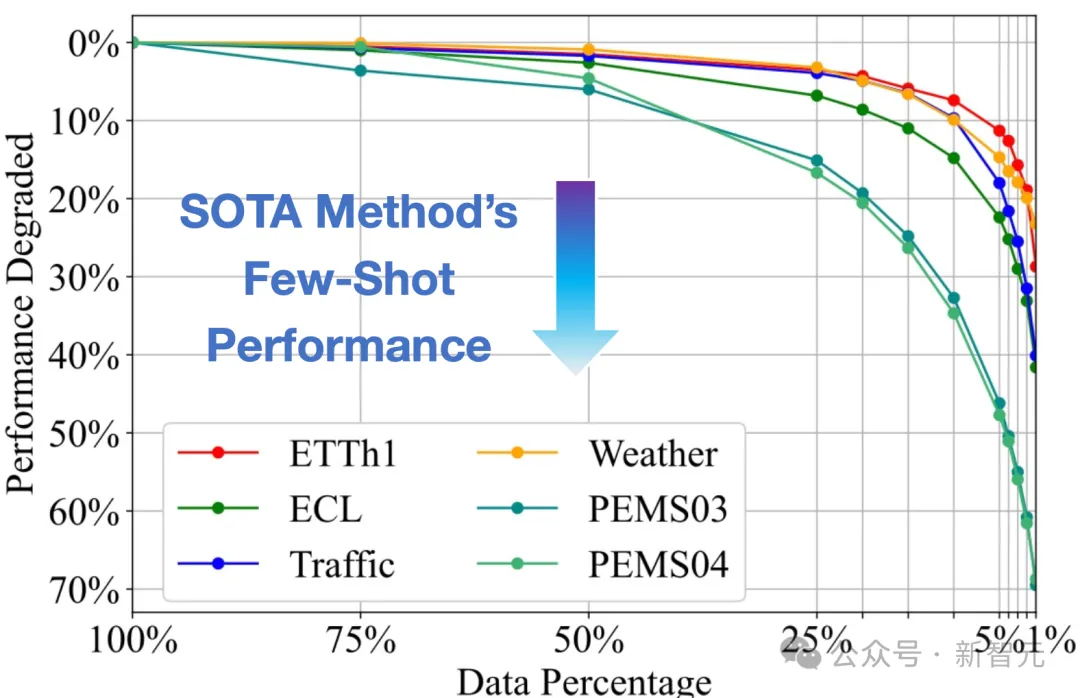
大模型在语言、图像领域取得了巨大成功,时间序列作为多个行业的重要数据类型,时序领域的大模型构建尚处于起步阶段。近期,清华大学的研究团队基于Transformer在大规模时间序列上进行生成式预训练,获得了任务通用的时序分析模型,展现出大模型特有的泛化性与可扩展性

近日,《连线》杂志联合ProofNews联合发表一篇调查文章,指责苹果、Anthropic等科技巨头未经许可使用YouTube视频训练AI模型。但训练数据的使用边界究竟在哪里?创作者、大公司和开发者正在陷入知识产权的罗生门……
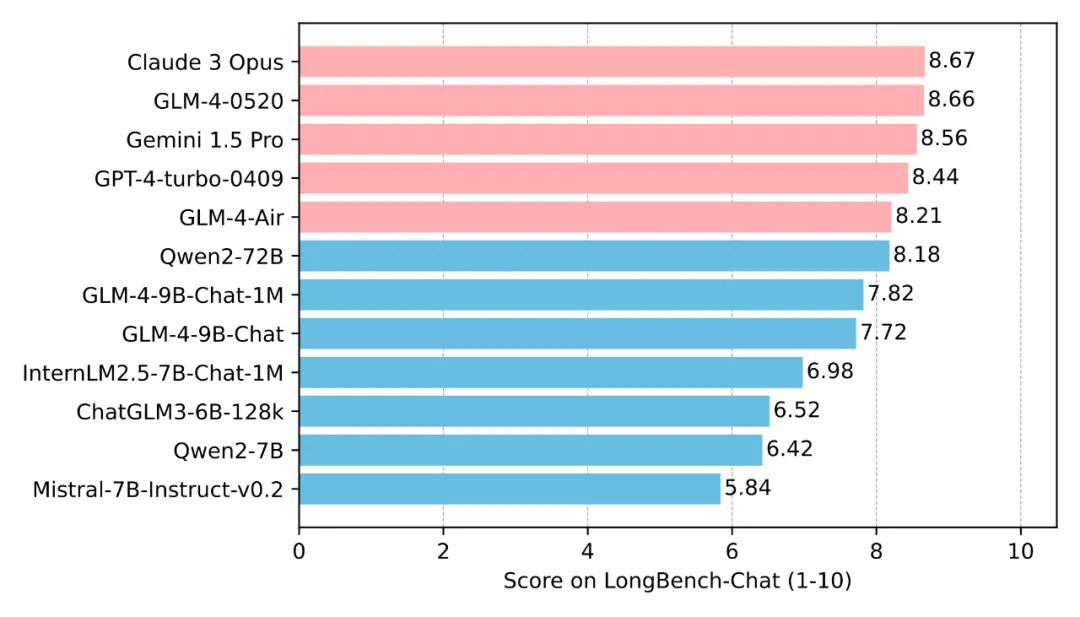
在2023年初,即便是当时最先进的GPT-3.5,其上下文长度也仅限于2k。然而,时至今日,1M的上下文长度已经成为衡量模型技术先进性的重要标志之一。
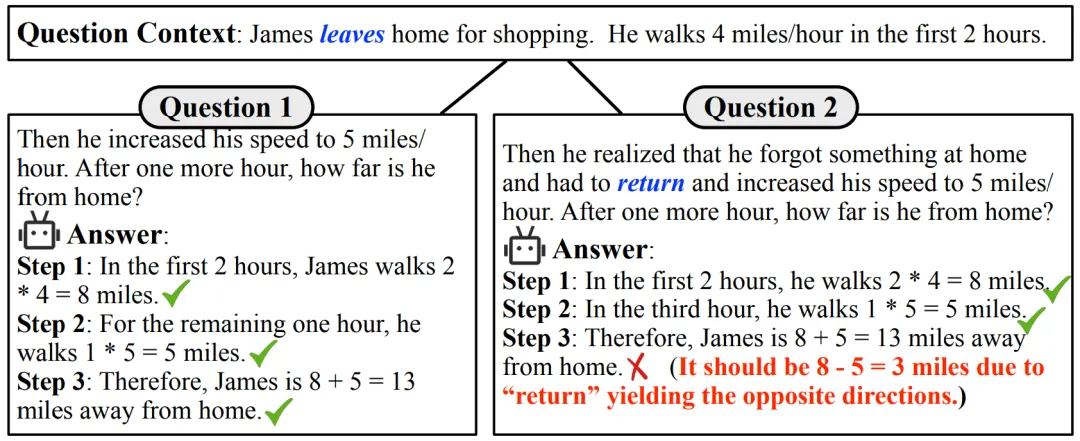
大型语言模型(LLMs)在解决问题方面的非凡能力日益显现。最近,一个值得关注的现象是,这些模型在多项数学推理的基准测试中获得了惊人的成绩。以 GPT-4 为例,在高难度小学应用题测试集 GSM8K [1] 中表现优异,准确率高达 90% 以上。同时,许多开源模型也展现出了不俗的实力,准确率超过 80%。
OpenAI超级对齐团队遗作:两个大模型博弈一番,输出更好懂了