30行代码,500万长文本推理提速8倍!「树注意力」让GPU越多省的越多
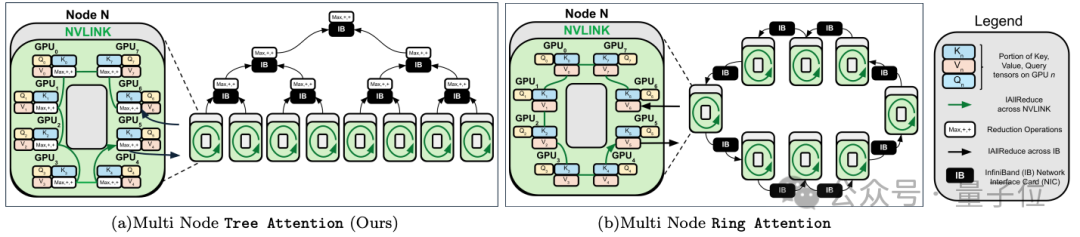
30行代码,500万长文本推理提速8倍!「树注意力」让GPU越多省的越多跨GPU的注意力并行,最高提速8倍,支持512万序列长度推理。
来自主题: AI技术研报
9515 点击 2024-08-12 13:50
 搜索
搜索
跨GPU的注意力并行,最高提速8倍,支持512万序列长度推理。

2017 年,谷歌在论文《Attention is all you need》中提出了 Transformer,成为了深度学习领域的重大突破。该论文的引用数已经将近 13 万,后来的 GPT 家族所有模型也都是基于 Transformer 架构,可见其影响之广。 作为一种神经网络架构,Transformer 在从文本到视觉的多样任务中广受欢迎,尤其是在当前火热的 AI 聊天机器人领域。
只需30秒,AI就能像3D建模师一样,在各种指示下生成高质量人造Mesh。
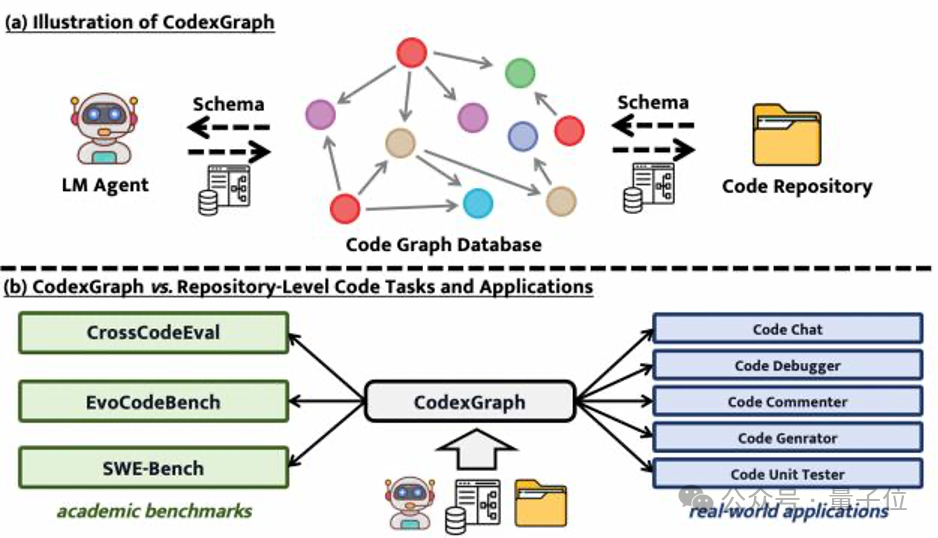
代码生成和补全任务做不完了?!

把Llama 3.1 405B和Claude 3超大杯Opus双双送进小黑屋,你猜怎么着——

在过去的几年中,大型语言模型(Large Language Models, LLMs)在自然语言处理(NLP)领域取得了突破性的进展。这些模型不仅能够理解复杂的语境,还能够生成连贯且逻辑严谨的文本。

自从 Sora 发布以来,AI 视频生成领域变得更加「热闹」了起来。过去几个月,我们见证了即梦、Runway Gen-3、Luma AI、快手可灵轮番炸场。

大模型发展究竟由工程还是科学驱动?

在软件开发的世界里,代码的生成、编辑、测试和调试一直是核心活动。

仅需15秒即可搞定随机规划问题,速度比传统方法快了1440倍!