苹果大模型新成果:GPT-4o扮演用户,在场景中考察大模型工具调用,网友:Siri也要努力 | 开源
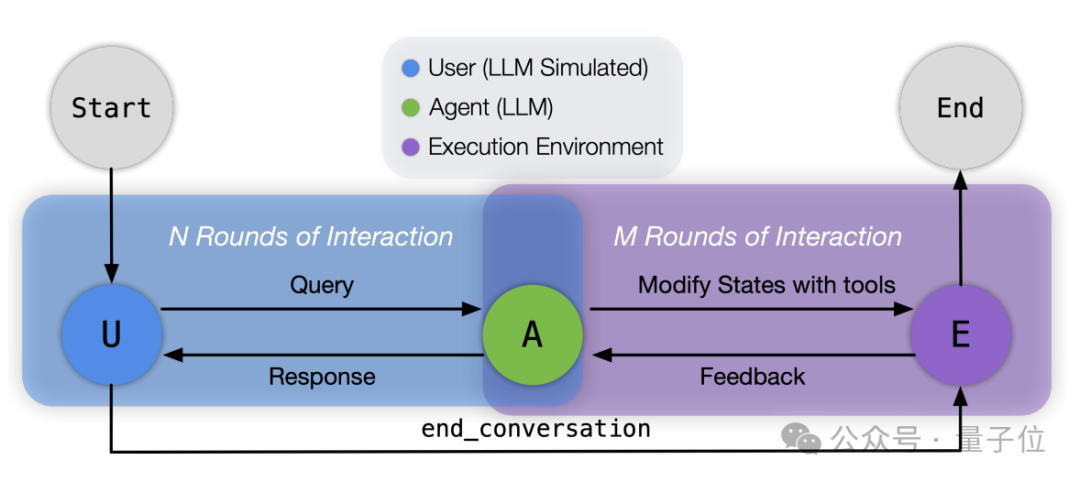
苹果大模型新成果:GPT-4o扮演用户,在场景中考察大模型工具调用,网友:Siri也要努力 | 开源苹果团队,又发布了新的开源成果——一套关于大模型工具调用能力的Benchmark。
来自主题: AI资讯
11476 点击 2024-08-14 17:25
 搜索
搜索
苹果团队,又发布了新的开源成果——一套关于大模型工具调用能力的Benchmark。

长文本处理能力对LLM的重要性是显而易见的。在2023年初,即便是当时最先进的GPT-3.5,其上下文长度也仅限于2k,然而今日,128k的上下文长度已经成为衡量模型技术先进性的重要标志之一。那你知道LLMs的长文本阅读能力如何评估吗?
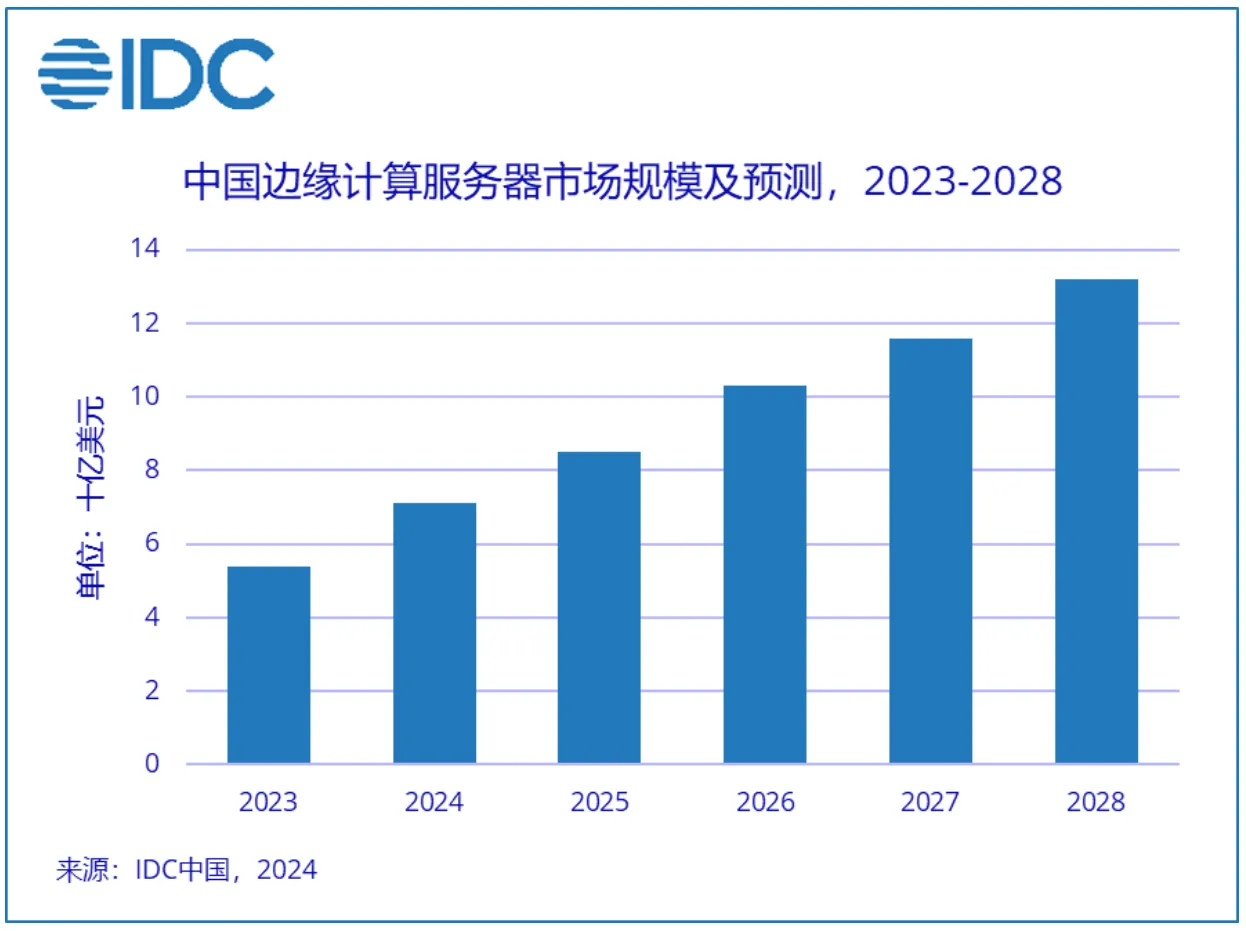
AI 大模型的爆发带动了 GPU 的强劲需求,从云端到边缘渗透的 AI 应用也将带动边缘 AI 服务器及加速处理器的需求。

T-MAC是一种创新的基于查找表(LUT)的方法,专为在CPU上高效执行低比特大型语言模型(LLMs)推理而设计,无需权重反量化,支持混合精度矩阵乘法(mpGEMM),显著降低了推理开销并提升了计算速度。

人工智能系统依靠充足、高质量的训练数据来获得高性能,但MIT等机构最近的一项研究发现,曾经免费提供的数据在多个方面变得越来越难获取。

只用提示词,多模态大模型就能更懂场景中的人物关系了。

关于长文本和 RAG 到底如何选择,一直有争论,从基模公司到应用开发者。 今天这篇文章,是来自基模公司月之暗面和中间层 Zilliz 的技术对话,值得一看。

三维数字人生成和编辑在数字孪生、元宇宙、游戏、全息通讯等领域有广泛应用。传统三维数字人制作往往费时耗力,近年来研究者提出基于三维生成对抗网络(3D GAN)从 2D 图像中学习三维数字人,极大提高了数字人制作效率。

Mini-Monkey 是一个轻量级的多模态大型语言模型,通过采用多尺度自适应切分策略(MSAC)和尺度压缩机制(SCM),有效缓解了传统图像切分策略带来的锯齿效应,提升了模型在高分辨率图像处理和文档理解任务的性能。它在多项基准测试中取得了领先的成绩,证明了其在多模态理解和文档智能领域的潜力。
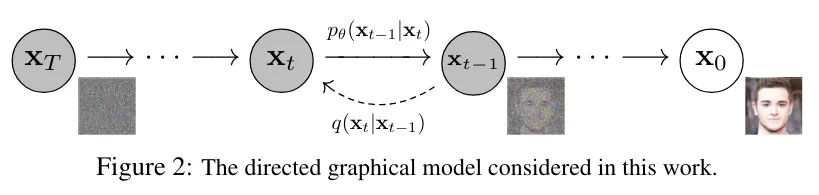
近日,来自加州大学尔湾分校等机构的研究人员,利用延迟掩蔽、MoE、分层扩展等策略,将扩散模型的训练成本降到了1890美元。