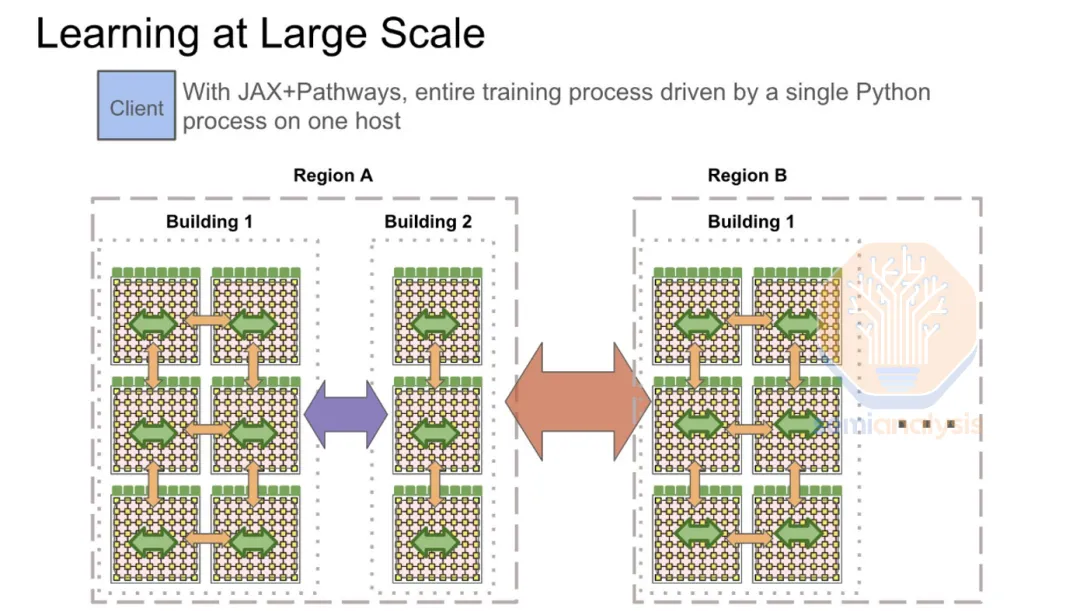
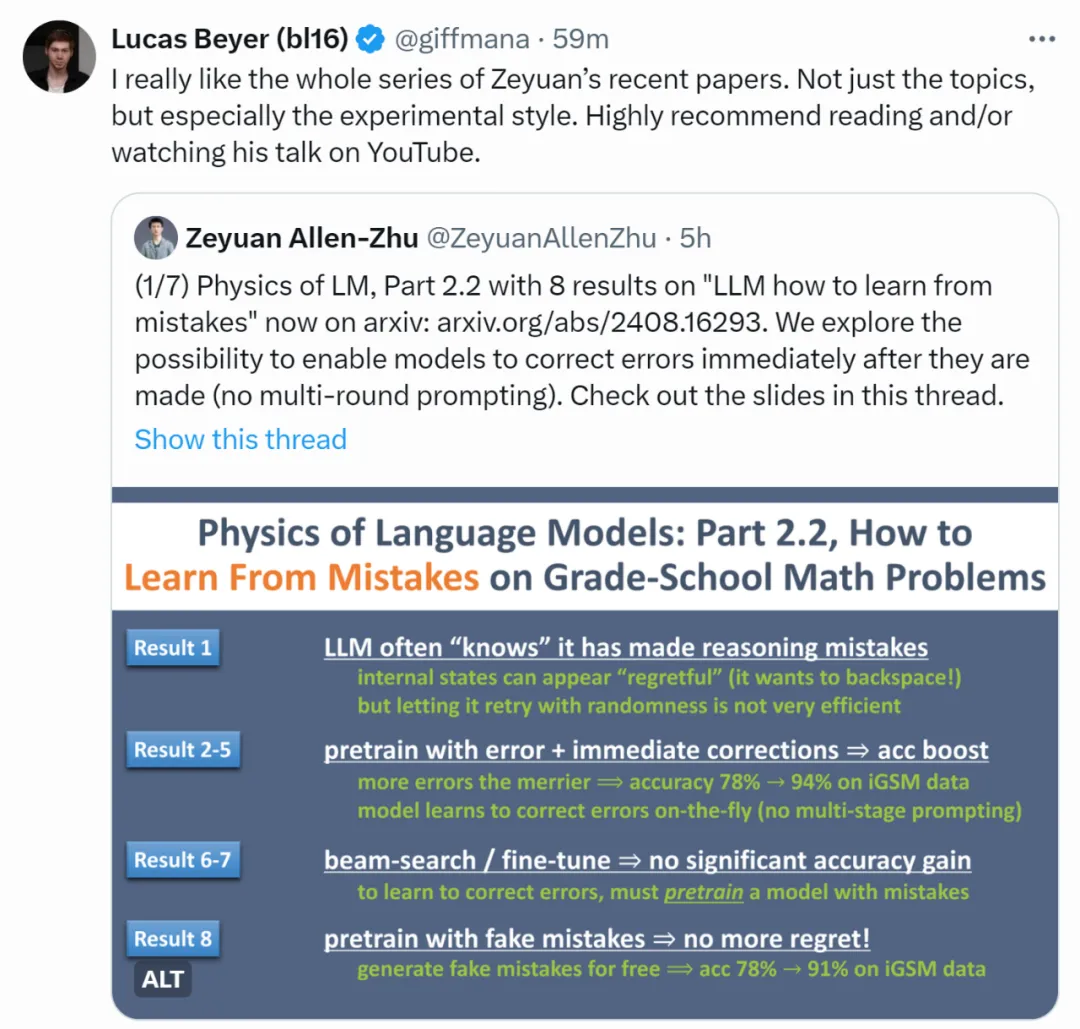
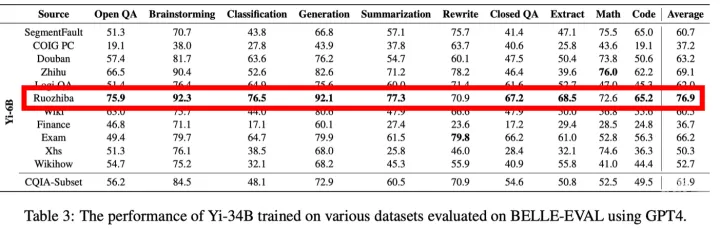
你以为的LLM上下文学习超能力,究竟来自哪里,ICL的内部机制如何 |最新发布
你以为的LLM上下文学习超能力,究竟来自哪里,ICL的内部机制如何 |最新发布上下文学习(In-Context Learning, ICL)是指LLMs能够仅通过提示中给出的少量样例,就迅速掌握并执行新任务的能力。这种“超能力”让LLMs表现得像是一个"万能学习者",能够在各种场景下快速适应并产生高质量输出。然而,关于ICL的内部机制,学界一直存在争议。
来自主题: AI资讯
6077 点击 2024-09-11 10:17