
开发者火冒三丈炮轰GenAI:垃圾语料太多,模型正在变得越来越笨
开发者火冒三丈炮轰GenAI:垃圾语料太多,模型正在变得越来越笨生成式AI(GenAI),尤其是以OpenAI的ChatGPT为代表,人们发现,这些大模型在一年多后的性能表现远不及刚发布时那样令人惊艳了。
来自主题: AI资讯
4734 点击 2024-10-08 18:59
 搜索
搜索
生成式AI(GenAI),尤其是以OpenAI的ChatGPT为代表,人们发现,这些大模型在一年多后的性能表现远不及刚发布时那样令人惊艳了。

Transformer计算,竟然直接优化到乘法运算了。MIT两位华人学者近期发表的一篇论文提出:Addition is All You Need,让LLM的能耗最高降低95%。

这样一套组合拳打下去,AI厂商大概率就会乖乖向网站付费了。

通用机器人模型,目前最大的障碍便是「异构性」。
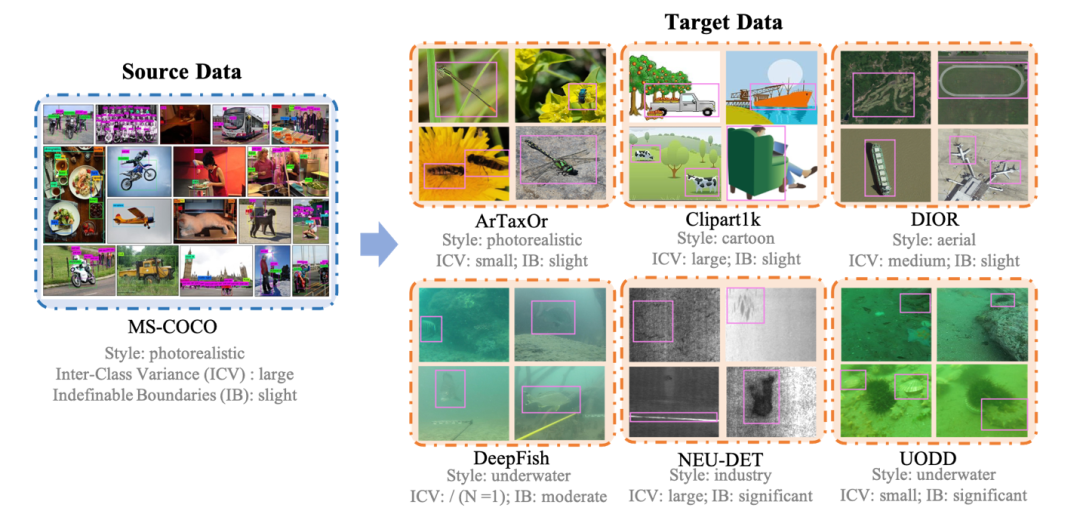
解决跨域小样本物体检测问题,入选ECCV 2024。

挑战Transformer,MIT初创团队推出LFM(Liquid Foundation Model)新架构模型爆火。
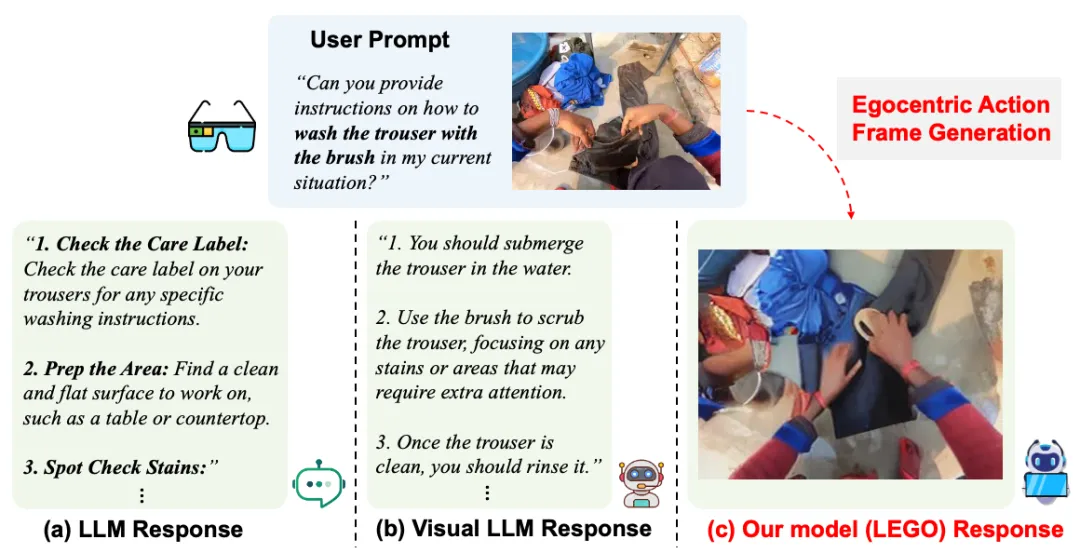
如何基于用户的问题和当前场景的照片,生成同一场景下的第一视角的动作图像,从而更准确地指导用户执行下一步行动?
EMOVA(EMotionally Omni-present Voice Assistant),一个能够同时处理图像、文本和语音模态,能看、能听、会说的多模态全能助手,并通过情感控制,拥有更加人性化的交流能力。

在机器人研究领域,抓取任务始终是机器人操作中的一个关键问题。这项任务的核心目标是控制机械手移动到合适位置,并完成对物体的抓取。近年来,基于学习的方法在提高对不同物体的抓取的泛化能力上取得了显著进展,但针对机械手本身,尤其是复杂的灵巧手(多指机械手)之间的泛化能力仍然缺乏深入研究。由于灵巧手在不同形态和几何结构上存在显著差异,抓取策略的跨手转移一直存在挑战。

大语言模型(Large Language Models, LLMs)的强大能力推动了 LLM Agent 的迅速发展。围绕增强 LLM Agent 的能力,近期相关研究提出了若干关键组件或工作流。然而,如何将核心要素集成到一个统一的框架中,能够进行端到端优化,仍然是一个亟待解决的问题。