
全模态对齐框架align-anything来了:实现跨模态指令跟随
全模态对齐框架align-anything来了:实现跨模态指令跟随如何全模态大模型与人类的意图相对齐,已成为一个极具前瞻性且至关重要的挑战。
来自主题: AI技术研报
9328 点击 2024-10-18 10:53
 搜索
搜索
如何全模态大模型与人类的意图相对齐,已成为一个极具前瞻性且至关重要的挑战。
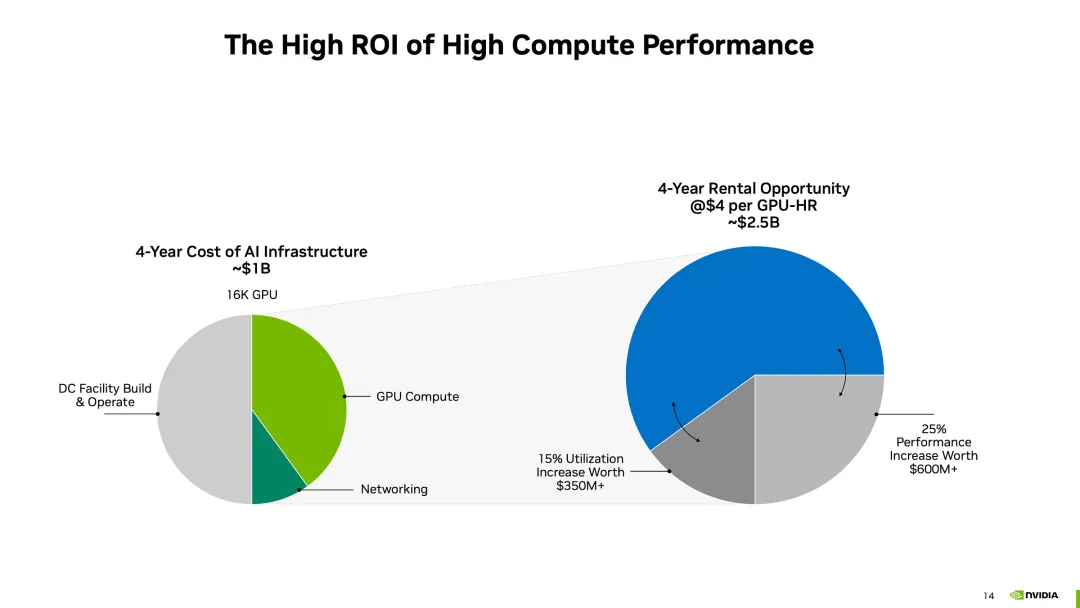
红杉资本的报告曾指出,AI产业的年产值超过6000亿美元,才够支付数据中心、加速GPU卡等AI基础设施费用。而现在一种普遍说法认为,基础模型训练的资本支出是“历史上贬值最快的资产”,但关于GPU基础设施支出的判定仍未出炉,GPU土豪战争仍在进行。

多项改进实现规模空前的连续时间一致性模型。
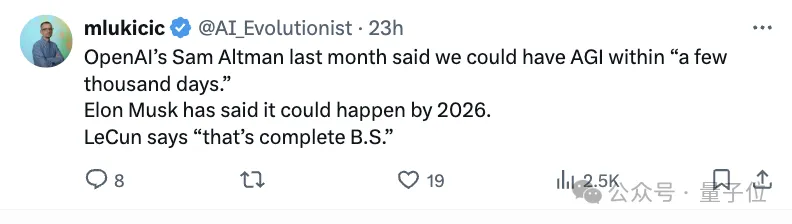
当奥特曼、马斯克、Anthropic CEO都纷纷将AGI实现锚定在2026年前后,LeCun无疑是直接浇了冷水:完全是胡说八道。

近期,LLM领域有不少关于系统1和系统2思考的讨论,在Agent方向上这方面的讨论还很少。如何让AI agents既能快速响应用户,又能进行深度思考和规划,一直是一个巨大的挑战。

我们都知道,OpenAI 最近越来越喜欢发博客了。 这不,今天他们又更新了一篇,标题是「评估 ChatGPT 中的公平性」,但实际内容却谈的是用户的身份会影响 ChatGPT 给出的响应。

OpenAI ο1 模型的发布掀起了人们对 AI 推理过程的关注,甚至让现在的 AI 行业开始放弃卷越来越大的模型,而是开始针对推理过程进行优化了。今天我们介绍的这项来自 Meta FAIR 田渊栋团队的研究也是如此,其从人类认知理论中获得了灵感,提出了一种新型 Transformer 架构:Dualformer。
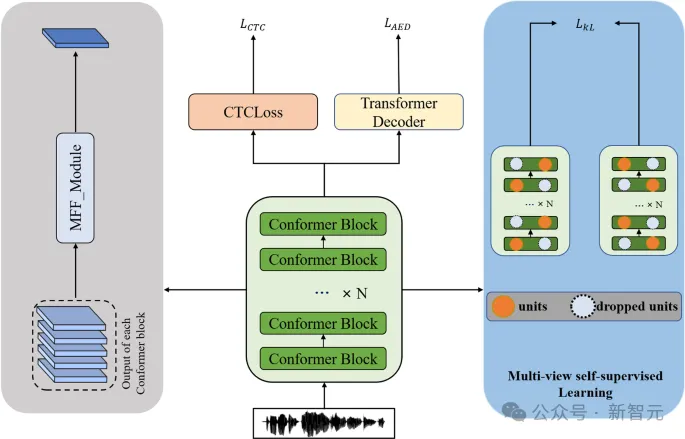
近日,来自斯坦福、MIT、纽约大学和Meta-FAIR等机构的研究人员,通过新的研究重新定义了最大流形容量表示法(MMCR)的可能性。

在自然语言处理、语音识别和时间序列分析等众多领域中,序列建模是一项至关重要的任务。然而,现有的模型在捕捉长程依赖关系和高效建模序列方面仍面临诸多挑战。
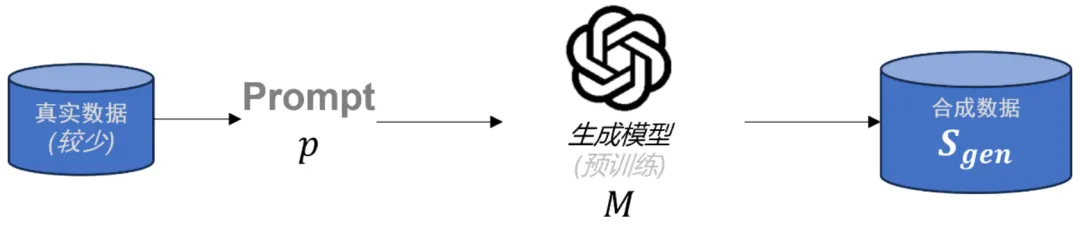
在大语言模型(LLMs)后训练任务中,由于高质量的特定领域数据十分稀缺,合成数据已成为重要资源。虽然已有多种方法被用于生成合成数据,但合成数据的理论理解仍存在缺口。为了解决这一问题,本文首先对当前流行的合成数据生成过程进行了数学建模。