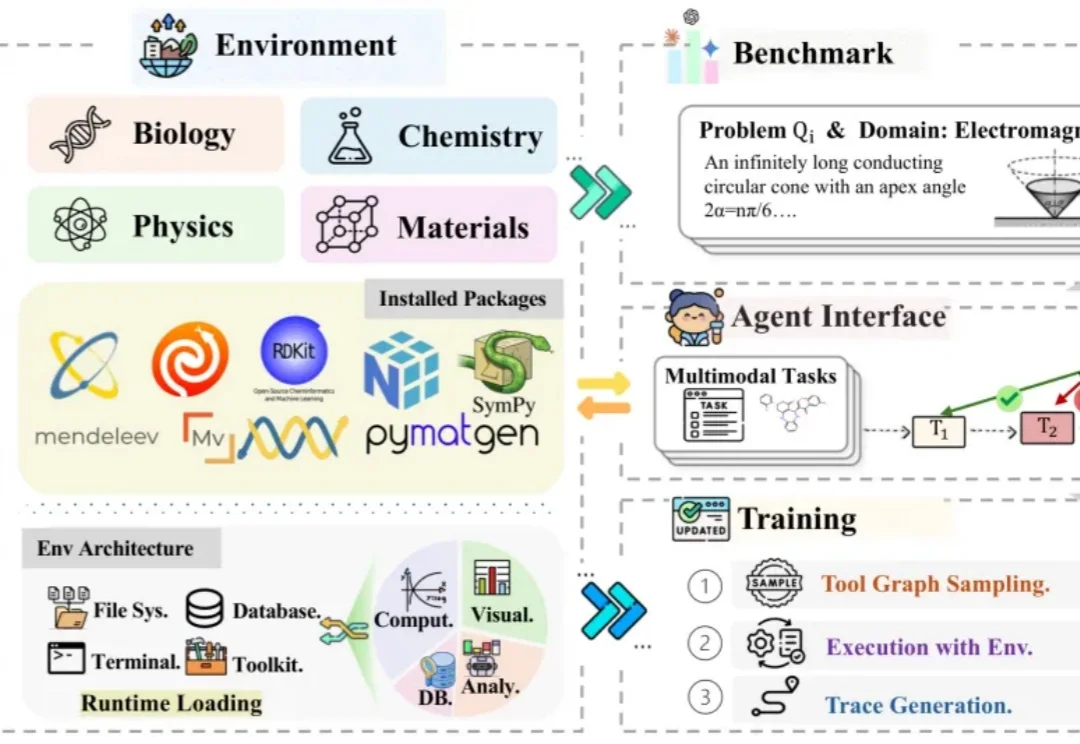
从答题到做实验:SciAgentGym让大模型进入科学工作流
从答题到做实验:SciAgentGym让大模型进入科学工作流DeepMind 联合创始人、2024 年诺贝尔化学奖得主 Demis Hassabis 曾谈到,他一直将 AI 视为推动知识前沿的重要工具。AI 可以帮助科学家处理复杂数据、发现隐藏模式,也可能在未来参与更深层的科学探索。
来自主题: AI技术研报
5629 点击 2026-07-02 10:35
 搜索
搜索
DeepMind 联合创始人、2024 年诺贝尔化学奖得主 Demis Hassabis 曾谈到,他一直将 AI 视为推动知识前沿的重要工具。AI 可以帮助科学家处理复杂数据、发现隐藏模式,也可能在未来参与更深层的科学探索。
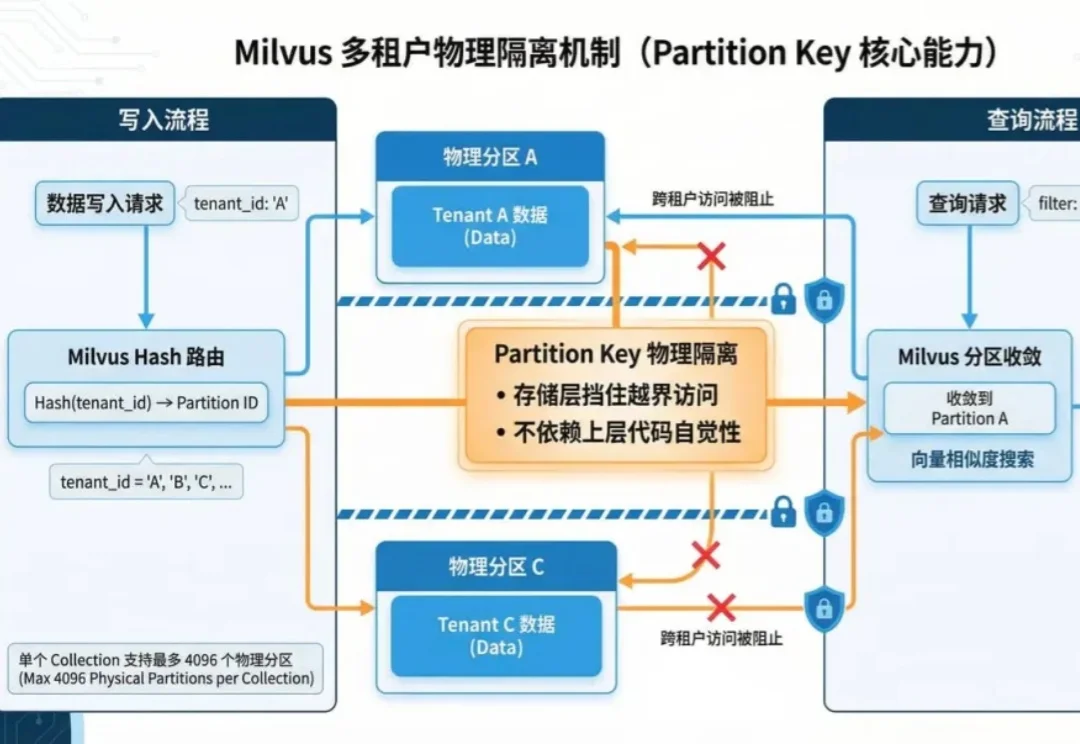
多租户 RAG 与Agent系统的生产实践中,最致命的事故莫过于数据串租,系统将租户 B 的私有数据作为背景知识,回答了租户 A 的提问。
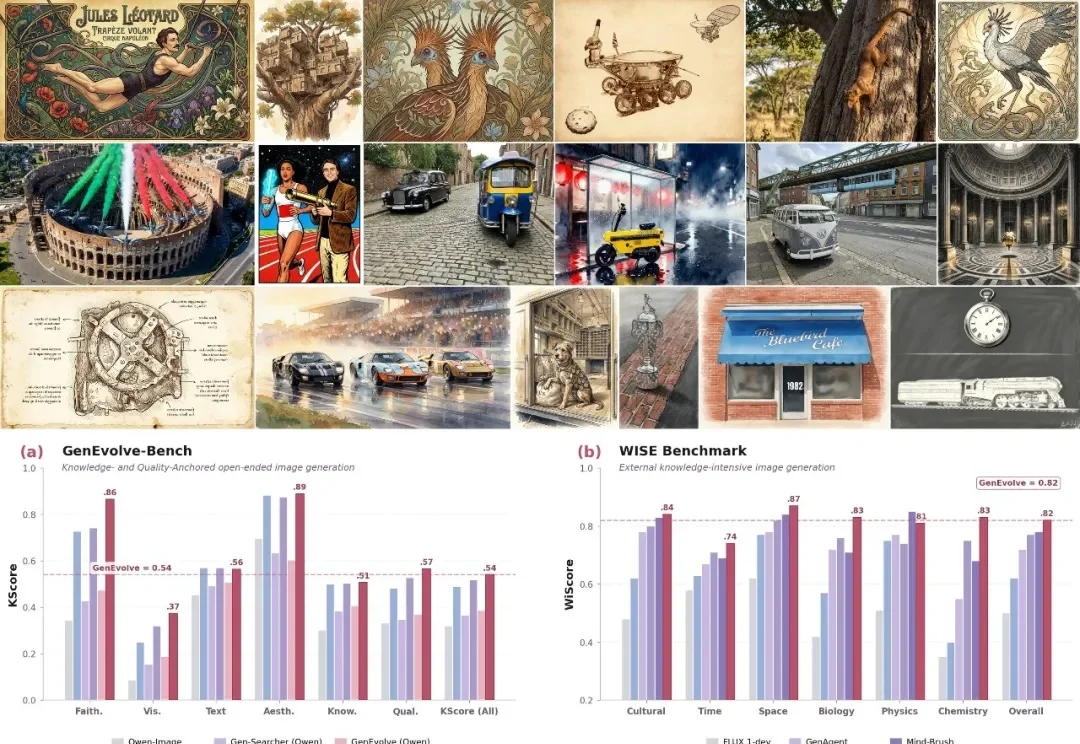
图像生成正在从「一句话生成一张图」,走向更接近真实创作流程的开放任务。
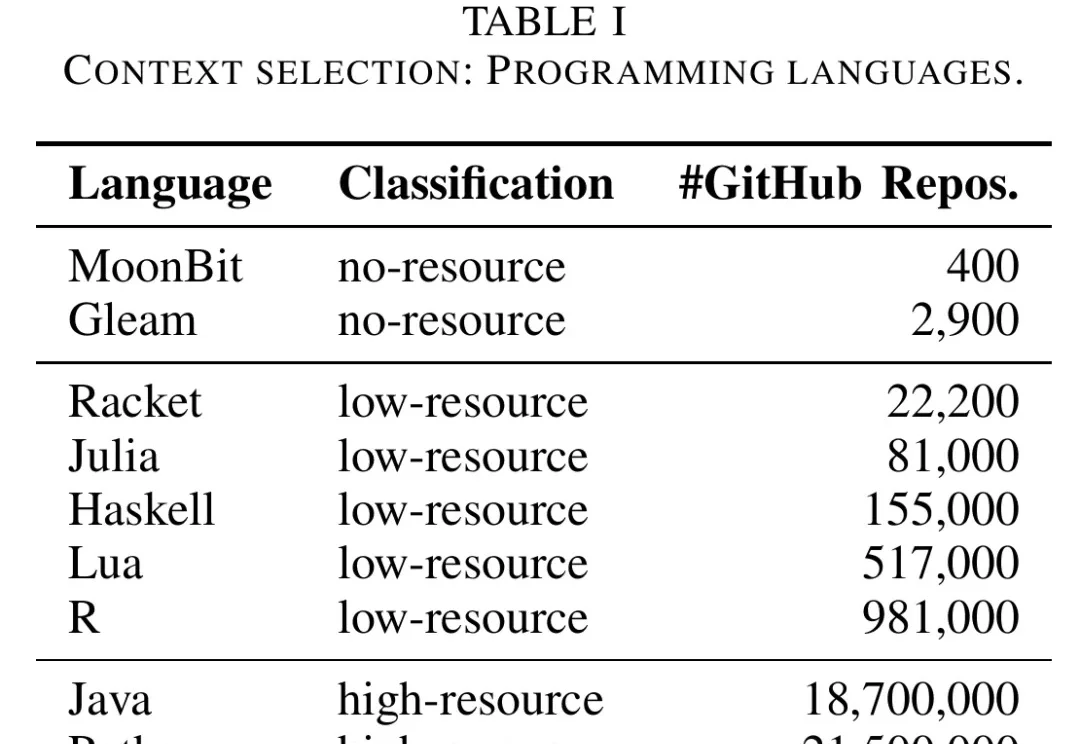
对于Python、Java、JavaScript这些语言,大模型通常能给出相当成熟的答案。
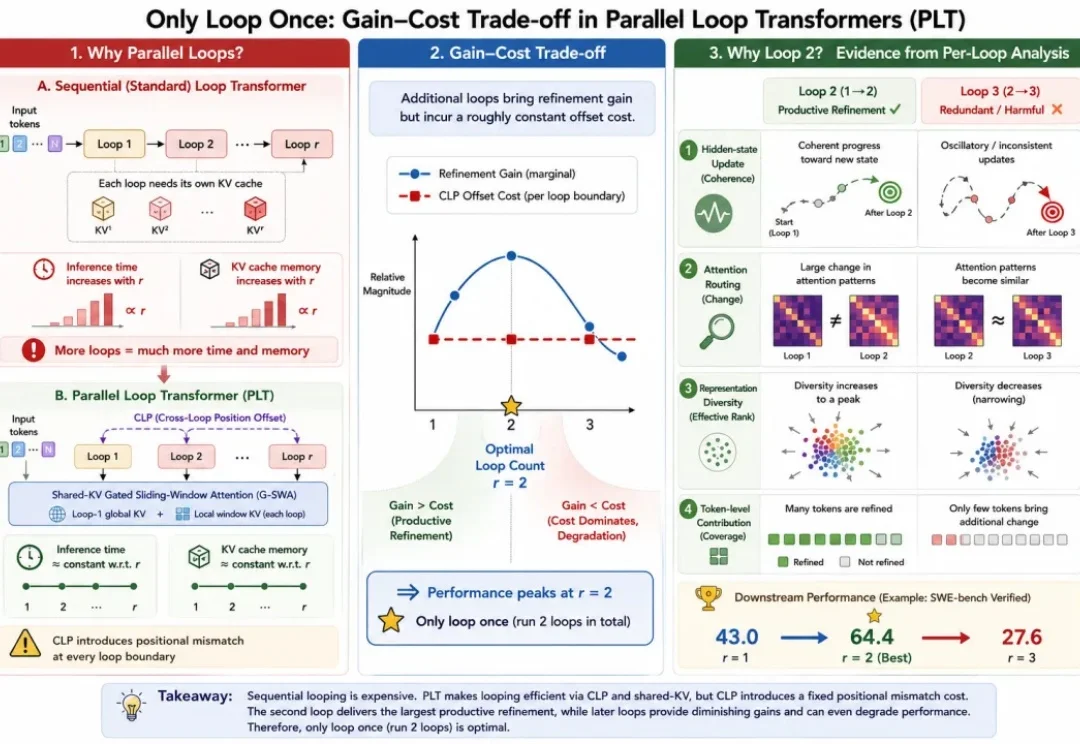
当所有人都在比谁「想得更久、算得更多」——推理模型动辄输出成千上万个思考 token,循环式架构恨不得在内部反复迭代十遍八遍——一项新研究反手泼了盆冷水:

AgentSociety²是清华大学团队推出的社会科学研究新工具,通过AI智能体模拟社会行为,帮助研究者构建实验环境,直接运行社会假设。它让AI同时扮演研究助手和实验参与者角色,使复杂社会问题能被构造、运行和分析,提升研究效率与可复现性。

卫星和航空影像里的目标,不仅大小相差悬殊,还可能朝向任意方向:一边是细长的桥梁、船舶,一边是密集的小车和大面积运动场。PKINet-v2是一种改进的遥感目标检测模型,能同时处理复杂形状和尺度变化的问题。

如果只看标题,它很容易被归到“又一个万亿参数大模型”的队伍里:1.6 万亿总参数、MoE 架构、100 万 token 上下文、面向代码和 Agent 场景。但这次真正值得看的,不只是模型有多大,而是它背后的三个问题:国产算力能不能支撑前沿级大模型训练?
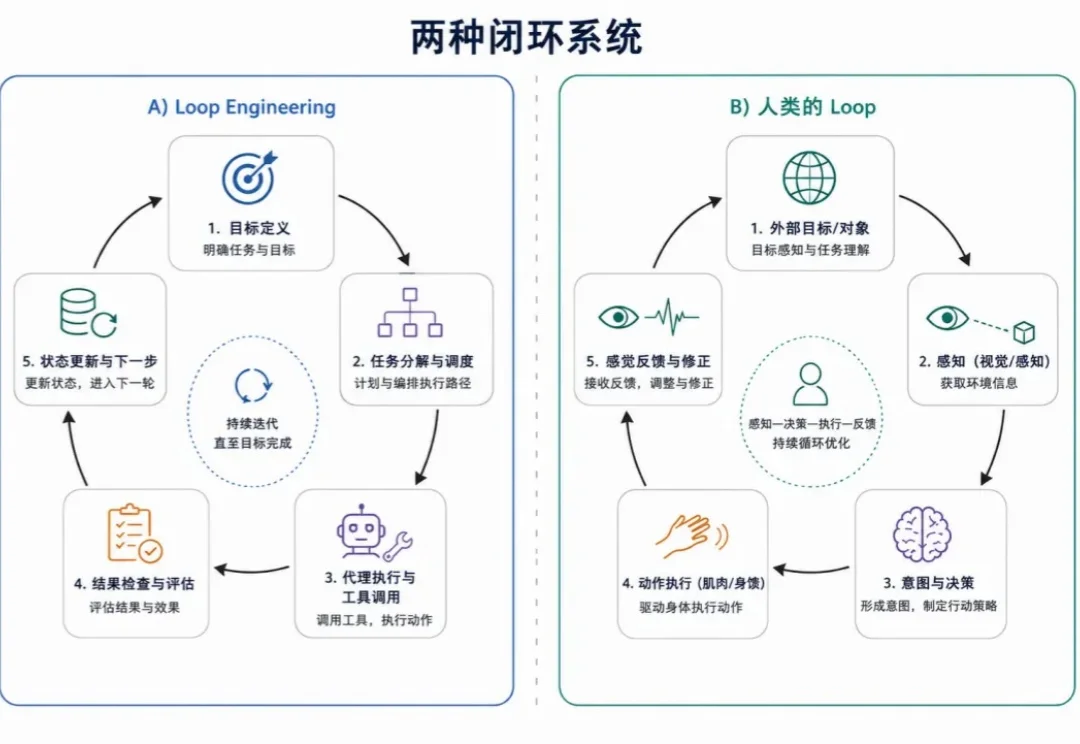
AI 圈最近又热了一个词:Loop Engineering。
长期以来,机制可解释性(mechanistic interpretability)领域有一个几乎从未被明说、却被视为理所当然的前提:模型对于同一种任务的能力或表现,背后对应着一条唯一的、或近乎唯一的内部「电路」(circuit)。该领域的研究者们之所以要做「电路发现」(circuit discovery),是为了要把这些「特定的」电路找出来。