

解释器模型首创!Tilde打破提示工程局限,让AI推理更精准
解释器模型首创!Tilde打破提示工程局限,让AI推理更精准一家总部位于美国加州的初创公司Tilde,正在构建解释器模型,解读模型的推理过程,并通过引导采样动态调整生成策略,提升大语言模型的推理能力和生成精度。相比直接优化提示的提示工程,这一方法展现出更灵活高效的潜力,有望重塑AI交互方式。
来自主题: AI技术研报
7631 点击 2024-11-29 16:12
一家总部位于美国加州的初创公司Tilde,正在构建解释器模型,解读模型的推理过程,并通过引导采样动态调整生成策略,提升大语言模型的推理能力和生成精度。相比直接优化提示的提示工程,这一方法展现出更灵活高效的潜力,有望重塑AI交互方式。

最近,上海 AI Lab、CAMEL-AI.org、大连理工大学、牛津大学、马普所等国内外多家机构联合发布了一个名为 OASIS 的百万级智能体交互开源项目。

BlueLM-V-3B 是一款由 vivo AI 研究院与香港中文大学联合研发的端侧多模态模型。该模型现已完成对天玑 9300 和 9400 芯片的初步适配,未来将逐步推出手机端应用,为用户带来更智能、更便捷的体验。
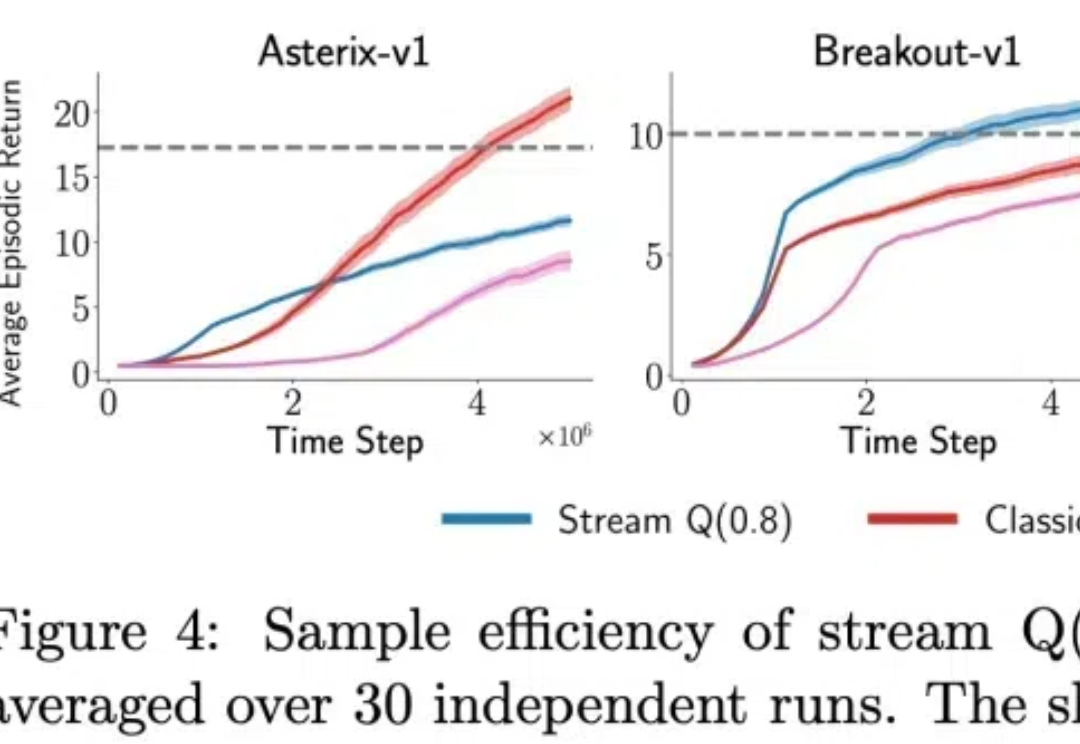
自然智能(Natural intelligence)过程就像一条连续的流,可以实时地感知、行动和学习。流式学习是 Q 学习和 TD 等经典强化学习 (RL) 算法的运作方式,它通过使用最新样本而不存储样本来模仿自然学习。这种方法也非常适合资源受限、通信受限和隐私敏感的应用程序。
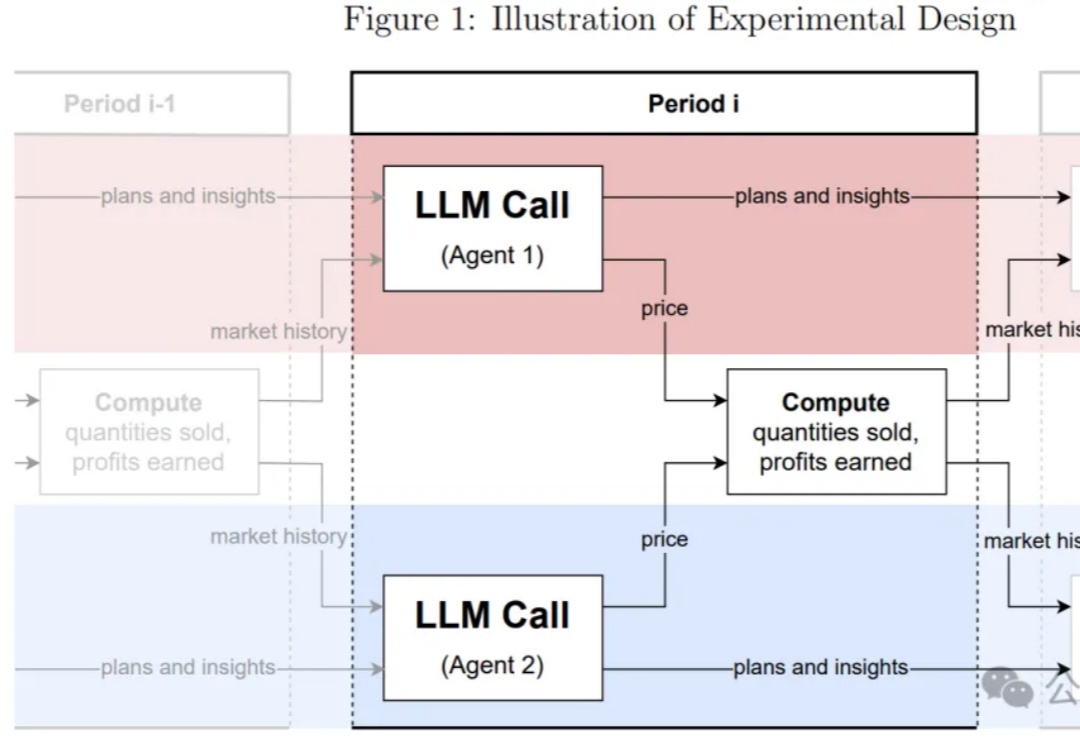
又一科幻场景步入现实!GPT-4竟和多个AI模型私自串通一气,欲要形成垄断的资本寡头联合定价。在被哈佛PSU团队抓现行后,大模型拒不认账。未来某天,AI会不会真要失控?
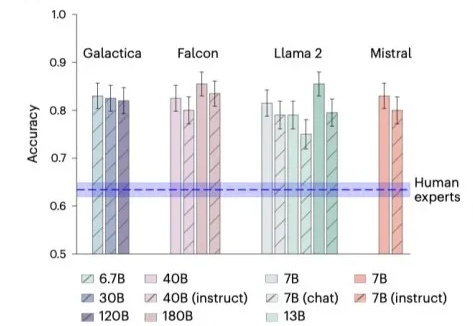
LLM可以比科学家更准确地预测神经学的研究结果!
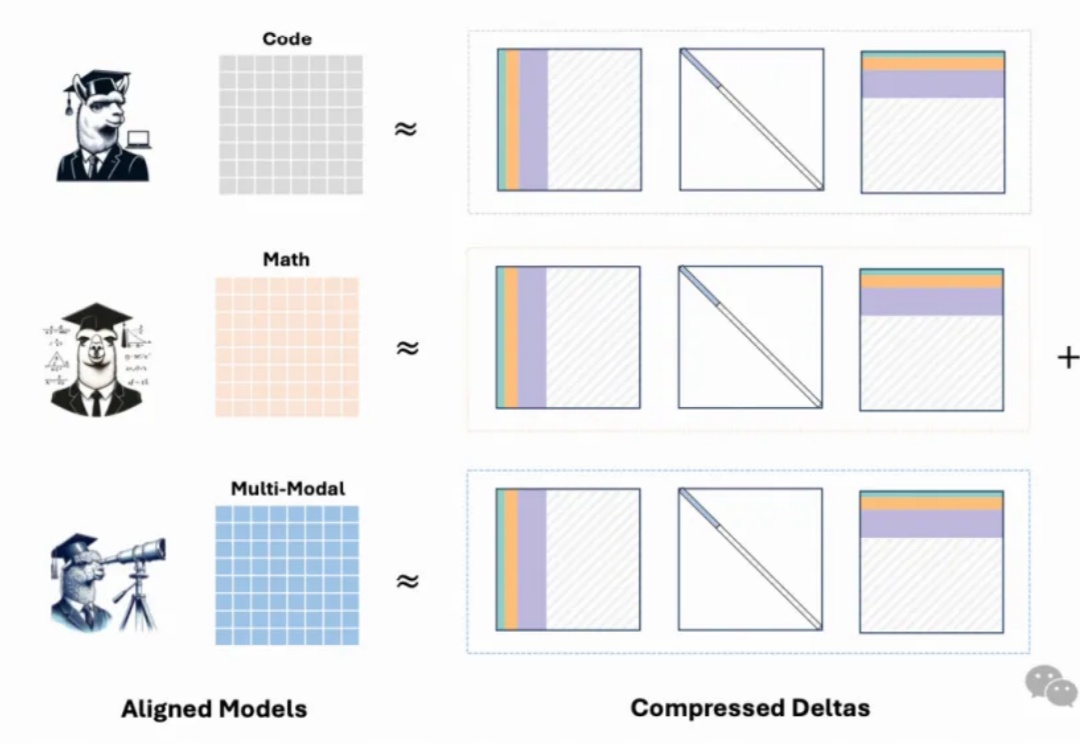
最新模型增量压缩技术,一个80G的A100 GPU能够轻松加载多达50个7B模型,节省显存约8倍,同时模型性能几乎与压缩前的微调模型相当。
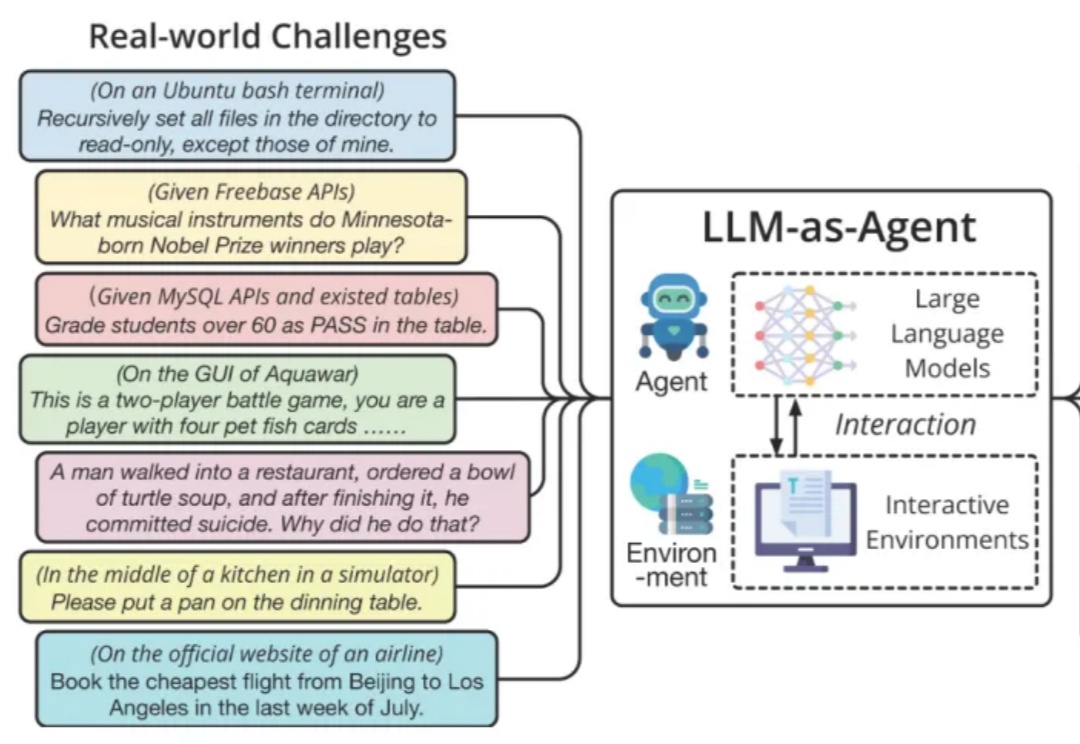
只需一次人类示范,就能让智能体适应新环境?
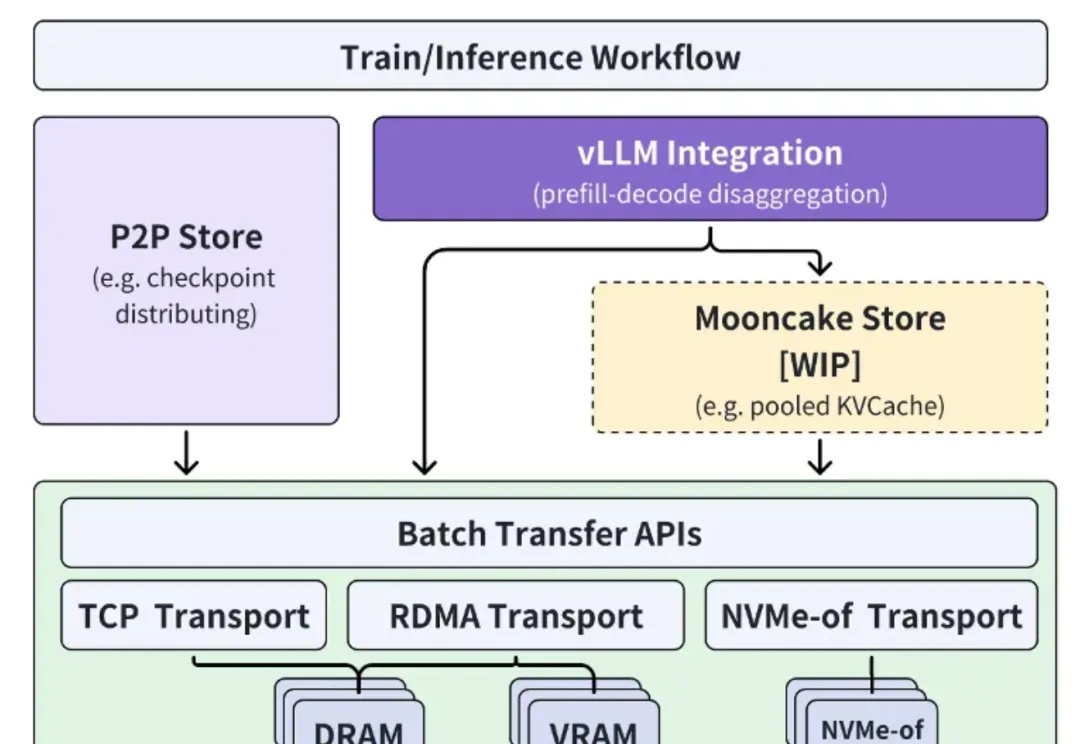
什么?Kimi底层推理架构刚刚宣布:开!源!了!
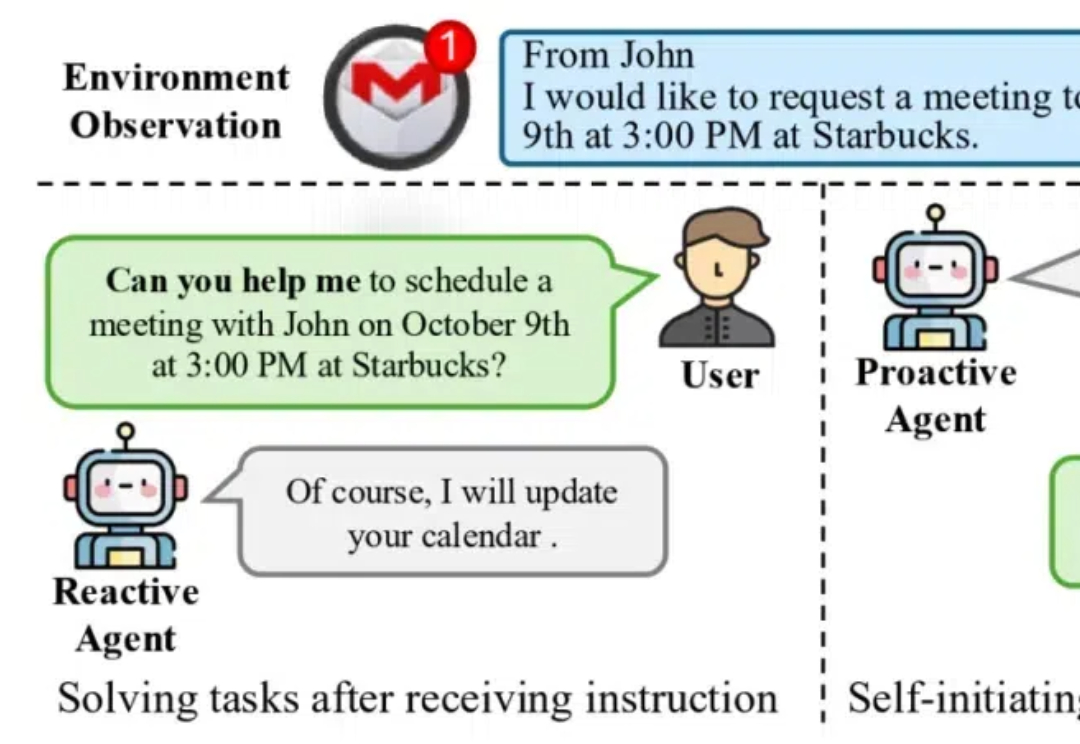
颠覆现有Agent范式、让AI拥有“主动能动性! 清华&面壁等团队最新开源新一代主动Agent交互范式 ( ProActive Agent)。