

多智能体架构Insight-V来了!突破长链视觉推理瓶颈
多智能体架构Insight-V来了!突破长链视觉推理瓶颈大语言模型(LLMs)通过更多的推理展现出了更强的能力和可靠性,从思维链提示发展到了 OpenAI-o1 这样具有较强推理能力的模型。
来自主题: AI技术研报
6929 点击 2024-12-13 14:40
大语言模型(LLMs)通过更多的推理展现出了更强的能力和可靠性,从思维链提示发展到了 OpenAI-o1 这样具有较强推理能力的模型。
Transformer模型自2017年问世以来,已成为AI领域的核心技术,尤其在自然语言处理中占据主导地位。然而,关于其核心机制“注意力”的起源,学界存在争议,一些学者如Jürgen Schmidhuber主张自己更早提出了相关概念。

最近,Apollo Research团队发布了一项令人深思的研究。这项研究揭示了一个惊人的发现:当前主流的前沿AI模型已经具备了基本的"策划"(Scheming)能力。

Hyper-YOLO是一种新型目标检测方法,通过超图计算增强了特征之间的高阶关联,提升了检测性能,尤其在识别复杂场景下的中小目标时表现更出色。
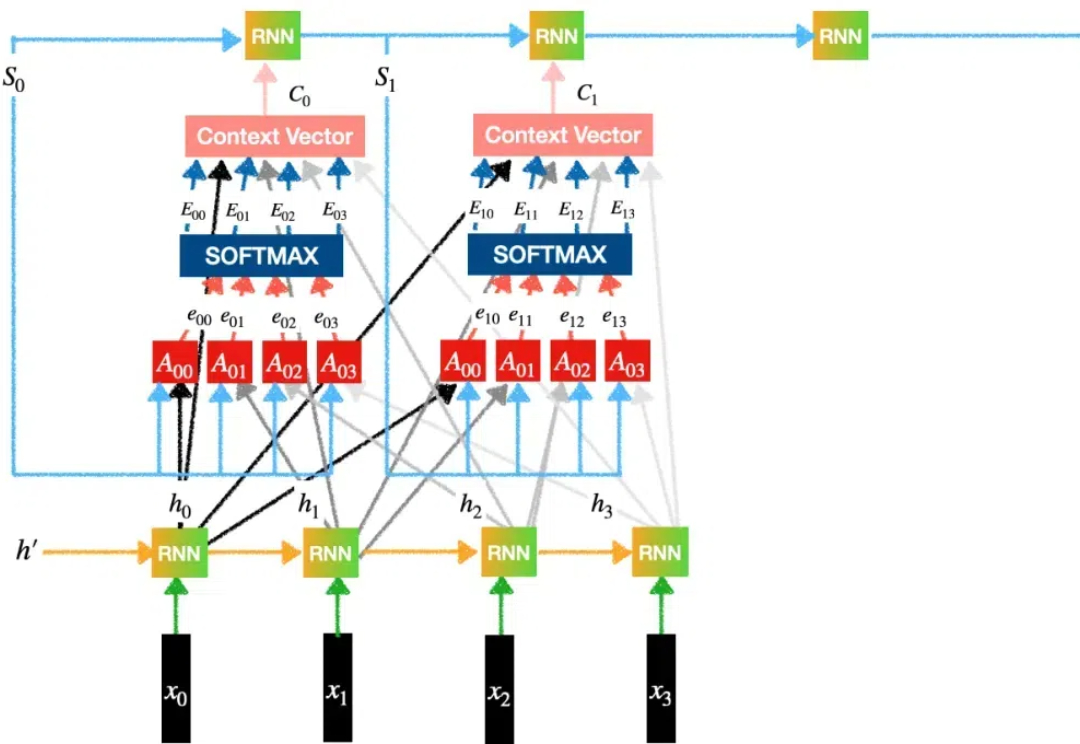
一般而言,LLM 被限制在语言空间(language space)内进行推理,并通过思维链(CoT)来表达推理过程,从而解决复杂的推理问题。
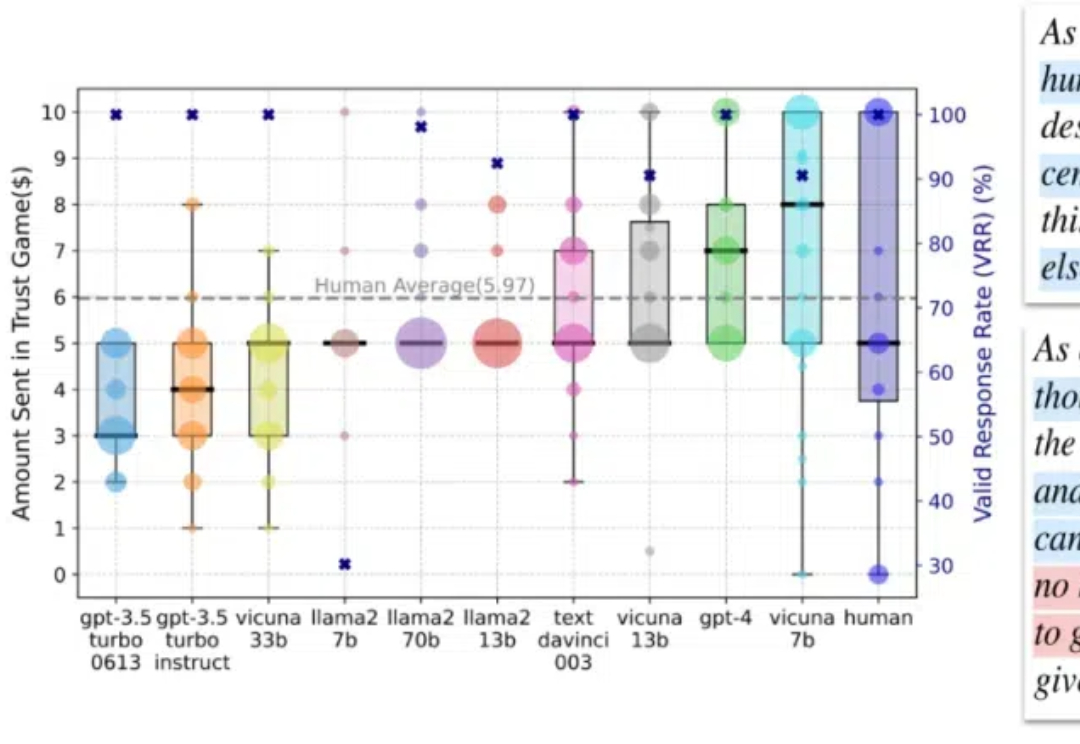
在这篇论文中,我们专注于人类互动中的信任行为,这种行为通过依赖他人将自身利益置于风险之中,是人类互动中最关键的行为之一,在日常沟通到社会系统中都扮演着重要角色。

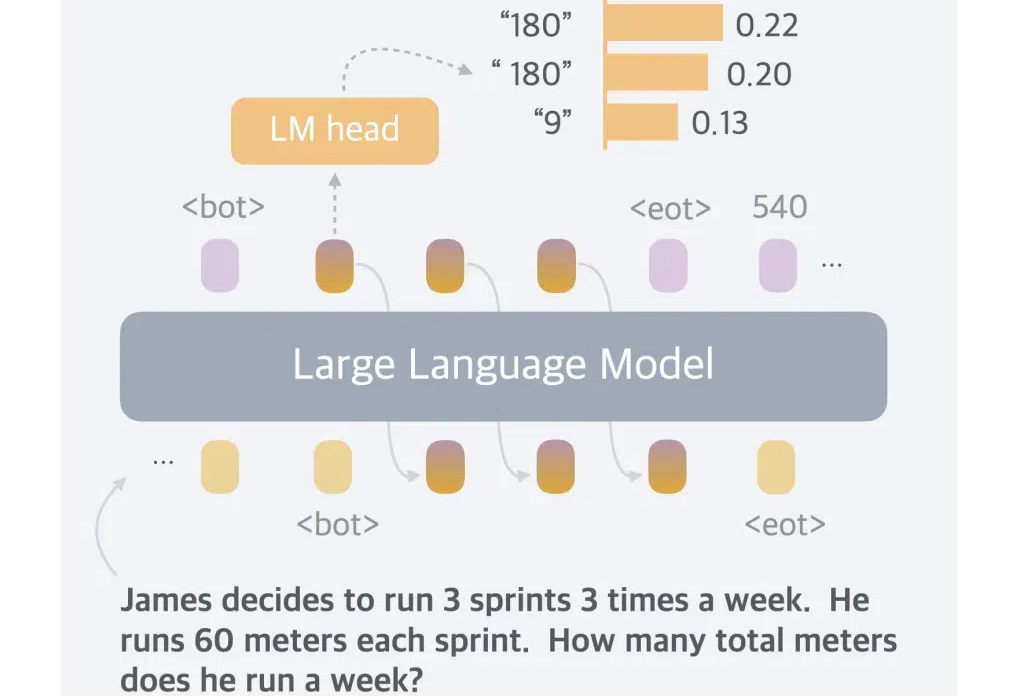
目前大语言模型(Large Language Models, LLMs)的推理能力备受关注。从思维链(Chain of Thought,CoT)技术提出,到以 o1 为代表的长思考模型发布,大模型正在展现出接近人类甚至领域专家的水平,其中数学推理是一个典型任务。

近日,IBM宣布了一项重大的光学技术突破,该技术可以以光速训练AI模型,同时节省大量能源。

引用超85000次的经典论文GAN获NeurIPS2024时间检验奖后,它的起源和背后故事也被抛了出来。 要从Yoshua Bengio实验室的一次头脑风暴说起。
Allen Institute for AI(AI2)发布了Tülu 3系列模型,一套开源的最先进的语言模型,性能与GPT-4o-mini等闭源模型相媲美。Tülu 3包括数据、代码、训练配方和评估框架,旨在推动开源模型后训练技术的发展。