
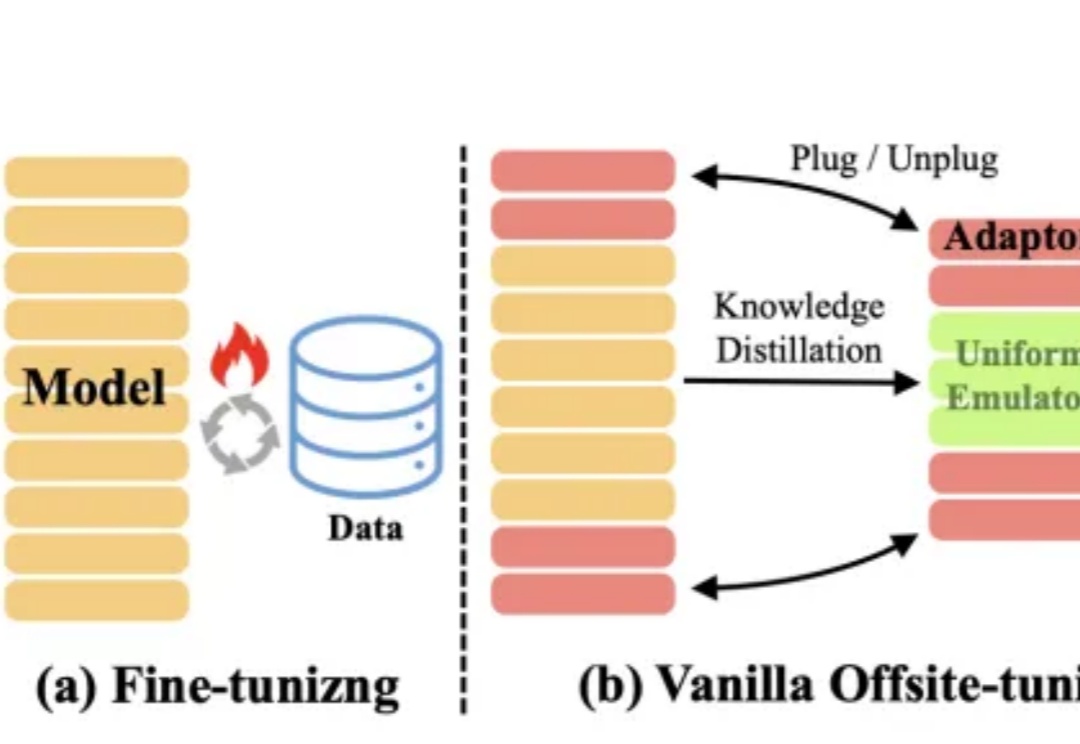
性能无损,模型隐私保护效果提升50%!蚂蚁数科创新跨域微调框架| AAAI 2025 Oral
性能无损,模型隐私保护效果提升50%!蚂蚁数科创新跨域微调框架| AAAI 2025 Oral大模型的快速及持续发展,离不开对模型所有权及数据隐私的保护。
来自主题: AI技术研报
10244 点击 2025-03-04 10:38
大模型的快速及持续发展,离不开对模型所有权及数据隐私的保护。
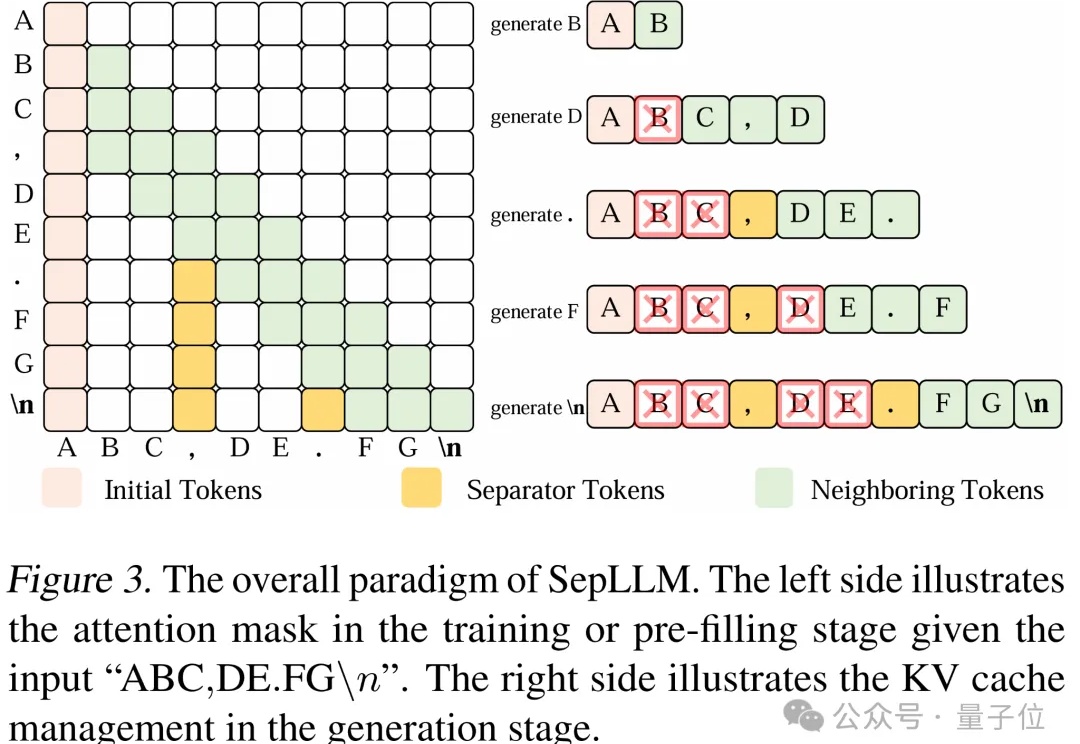
文字中貌似不起眼的标点符号,竟然可以显著加速大模型的训练和推理过程?

近年来大语言模型(LLM)的迅猛发展正推动人工智能迈向多模态融合的新纪元。然而,现有主流多模态大模型(MLLM)依赖复杂的外部视觉模块(如 CLIP 或扩散模型),导致系统臃肿、扩展受限,成为跨模态智能进化的核心瓶颈。

Hugging Face发布了「超大规模实战手册」,在512个GPU上进行超过4000个scaling实验。联创兼CEO Clement对此感到十分自豪。

国际可重构计算领域顶级会议 ——FPGA 2025 在落幕之时传来消息,今年的最佳论文颁发给了无问芯穹和上交、清华共同提出的视频生成大模型推理 IP 工作 FlightVGM,这是 FPGA 会议首次将该奖项授予完全由中国大陆科研团队主导的研究工作,同时也是亚太国家团队首次获此殊荣。

LLM在推理任务中表现惊艳,却在自我纠正上的短板却一直令人头疼。UIUC联手马里兰大学全华人团队提出一种革命性的自我奖励推理框架,将生成、评估和纠正能力集成于单一LLM,让模型像人类一样「边想边改」,无需外部帮助即可提升准确性。

现有的可控Diffusion Transformer方法,虽然在推进文本到图像和视频生成方面取得了显著进展,但也带来了大量的参数和计算开销。

大语言模型(LLMs)在当今的自然语言处理领域扮演着越来越重要的角色,但其安全性问题也引发了广泛关注。
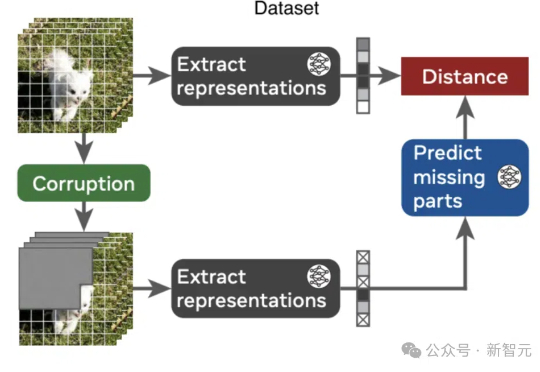
AI如何理解物理世界?视频联合嵌入预测架构V-JEPA带来新突破,无需硬编码核心知识,在自监督预训练中展现出对直观物理的理解,超越了基于像素的预测模型和多模态LLM。
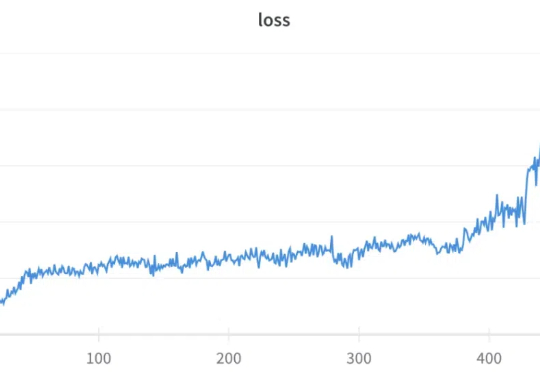
GRPO(Group Relative Policy Optimization)是 DeepSeek-R1 成功的基础技术之一,我们之前也多次报道过该技术,比如《DeepSeek 用的 GRPO 占用大量内存?有人给出了些破解方法》。