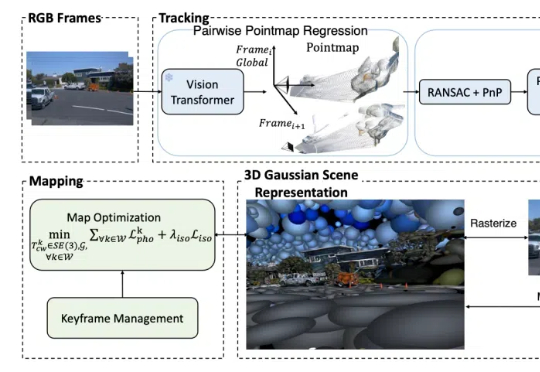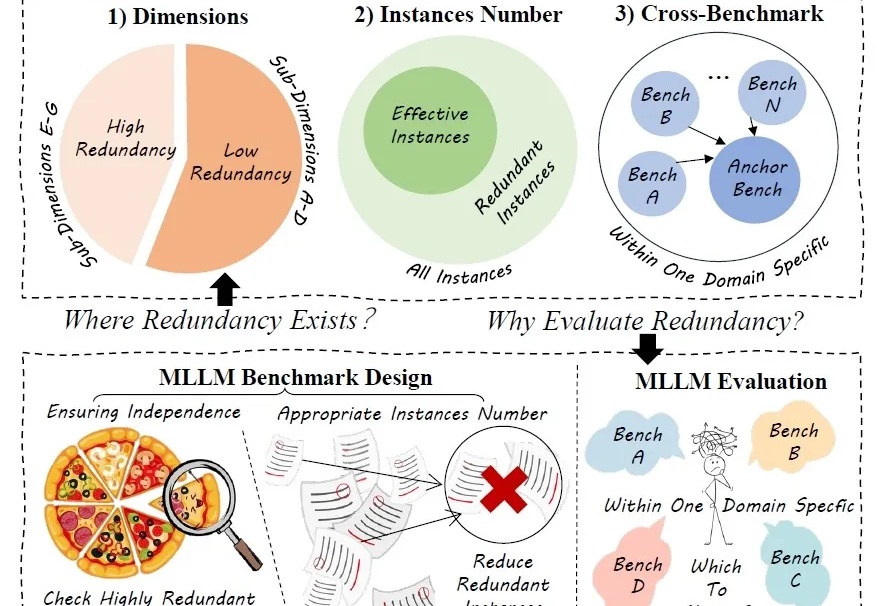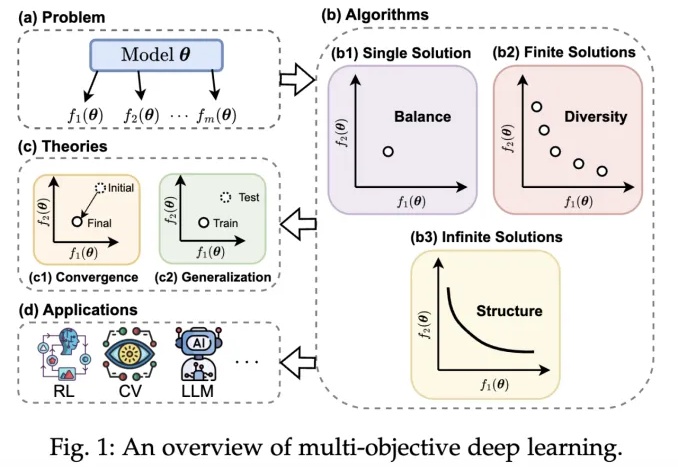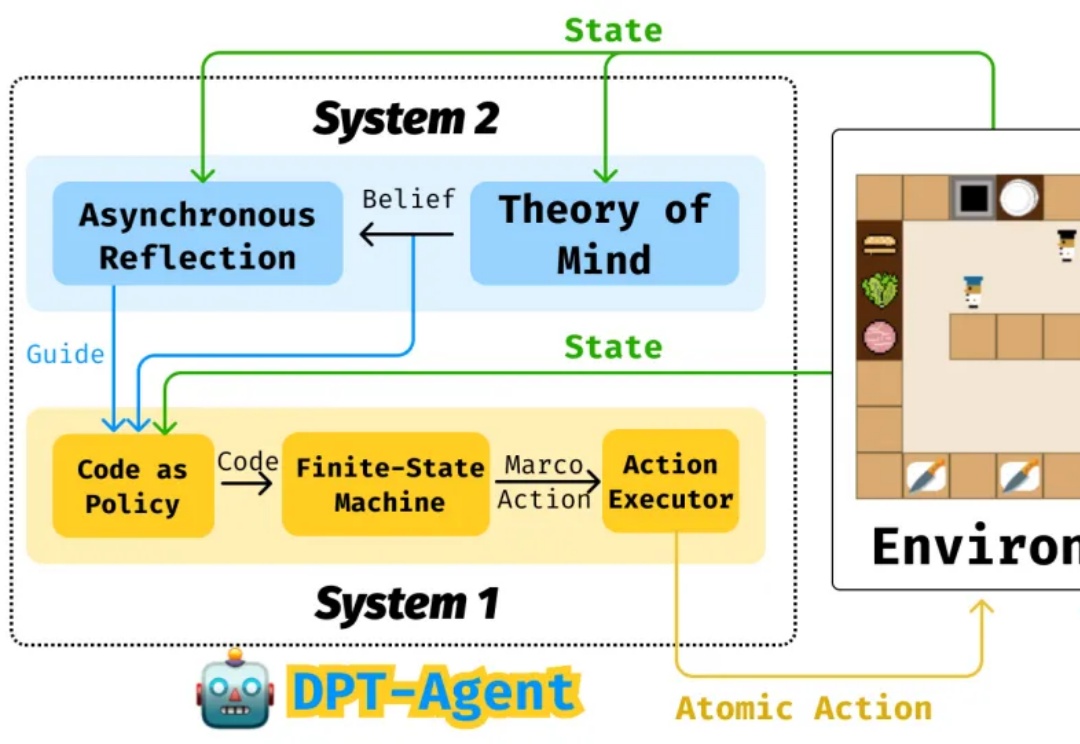
NAACL2025|中国移动九天团队提出大模型调色板:一种可控文本生成的解决方案
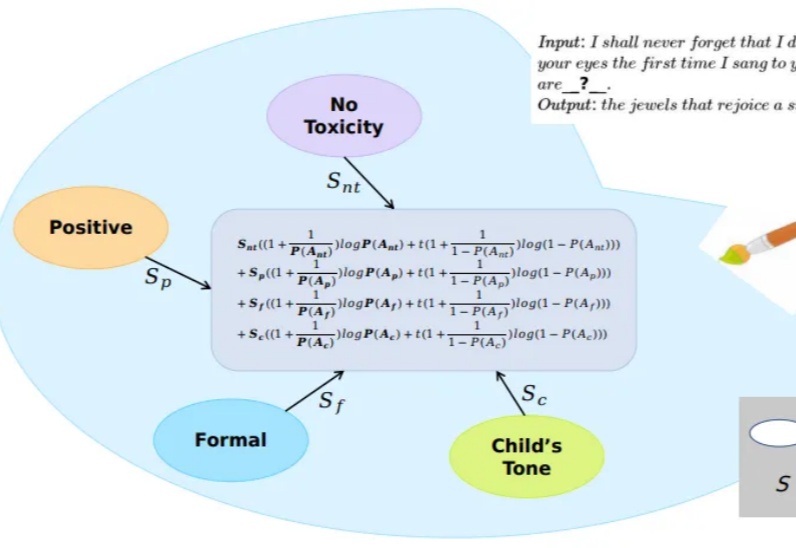
NAACL2025|中国移动九天团队提出大模型调色板:一种可控文本生成的解决方案大模型在文本生成方面取得了卓越的成就,通过合适的prompt设计,往往可以使得生成结果符合特定的需求。但是为属性繁多的任务设计出合适的prompt是很困难的。一种解决方案是通过线性组合方式或者其变种将每个属性对应的模型在生成logits上进行融合。鉴于属性之间可能存在的冲突现象,这种方案无法保证模型的主属性不受其他模型的干扰。
来自主题: AI技术研报
9993 点击 2025-03-19 14:52