
RAG发展图谱:从基础检索到记忆增强,再到自适应RAG的五大范式 | RAG最新综述
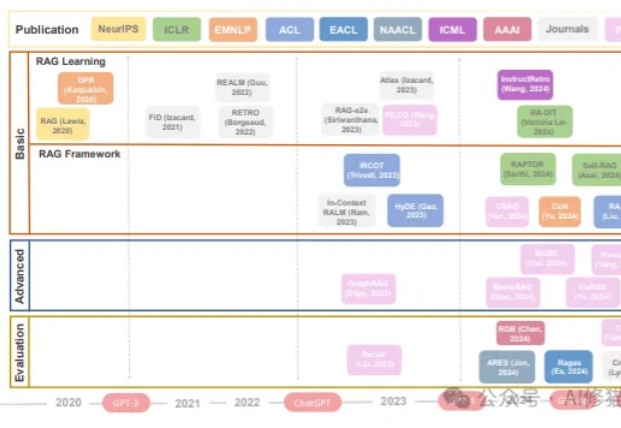
RAG发展图谱:从基础检索到记忆增强,再到自适应RAG的五大范式 | RAG最新综述RAG工作发展时间线(2020年至今)。展示了RAG相关研究的三个主要领域:基础(包括RAG学习和RAG框架)、进阶和评估。关键的语言模型(GPT-3、GPT-4等)发展节点标注在时间线上。
来自主题: AI技术研报
10614 点击 2025-03-21 12:18
RAG工作发展时间线(2020年至今)。展示了RAG相关研究的三个主要领域:基础(包括RAG学习和RAG框架)、进阶和评估。关键的语言模型(GPT-3、GPT-4等)发展节点标注在时间线上。
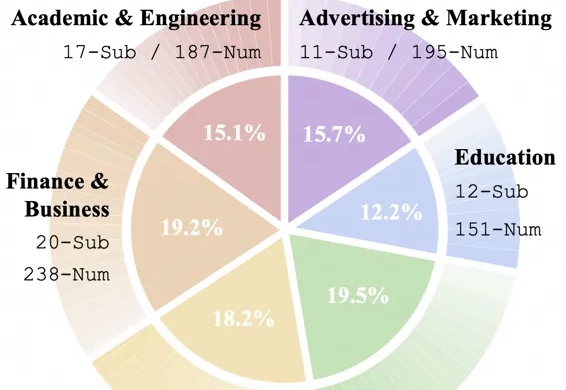
全面评估大模型生成式写作能力的基准来了!
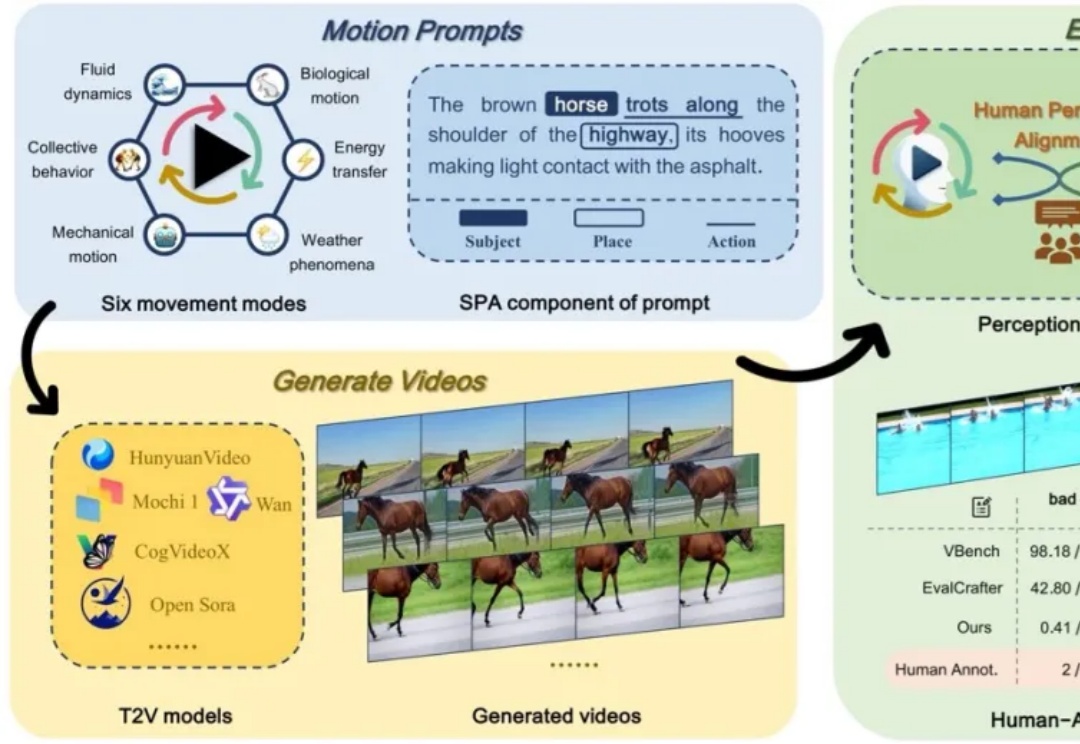
测一测现有AI生成视频是否符合物理运动规律!

任意一张立绘,就可以生成可拆分3D角色!
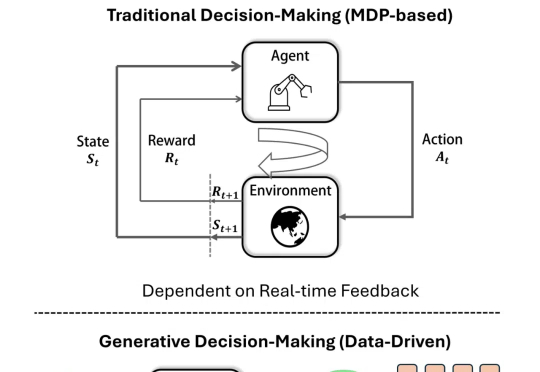
近年来,生成模型在内容生成(AIGC)领域蓬勃发展,同时也逐渐引起了在智能决策中的应用关注。
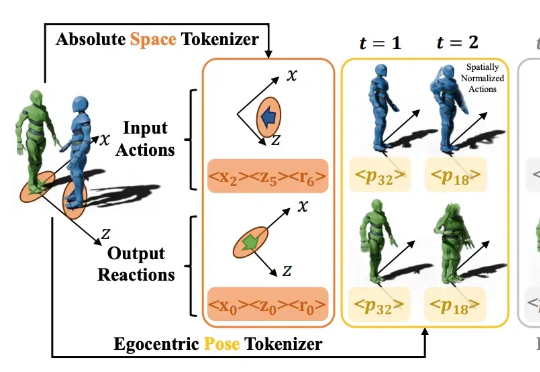
对面有个人向你缓缓抬起手,你会怎么回应呢?握手,还是挥手致意?

本文介绍了Search-R1技术,这是一项通过强化学习训练大语言模型进行推理并利用搜索引擎的创新方法。实验表明,Search-R1在Qwen2.5-7B模型上实现了26%的性能提升,使模型能够实时获取准确信息并进行多轮推理。本文详细分析了Search-R1的工作原理、训练方法和实验结果,为AI产品开发者提供了重要参考。

近年来,扩散模型在图像与视频合成领域展现出强大能力,为图像动画技术的发展带来了新的契机。特别是在人物图像动画方面,该技术能够基于一系列预设姿态驱动参考图像,使其动态化,从而生成高度可控的人体动画视频。
近年来,大型语言模型(LLM)通过大量计算资源在推理阶段取得了解决复杂问题的突破。推理速度已成为 LLM 架构的关键属性,市场对高效快速的 LLM 需求不断增长。

文本到图像(Text-to-Image, T2I)生成任务近年来取得了飞速进展,其中以扩散模型(如 Stable Diffusion、DiT 等)和自回归(AR)模型为代表的方法取得了显著成果。然而,这些主流的生成模型通常依赖于超大规模的数据集和巨大的参数量,导致计算成本高昂、落地困难,难以高效地应用于实际生产环境。