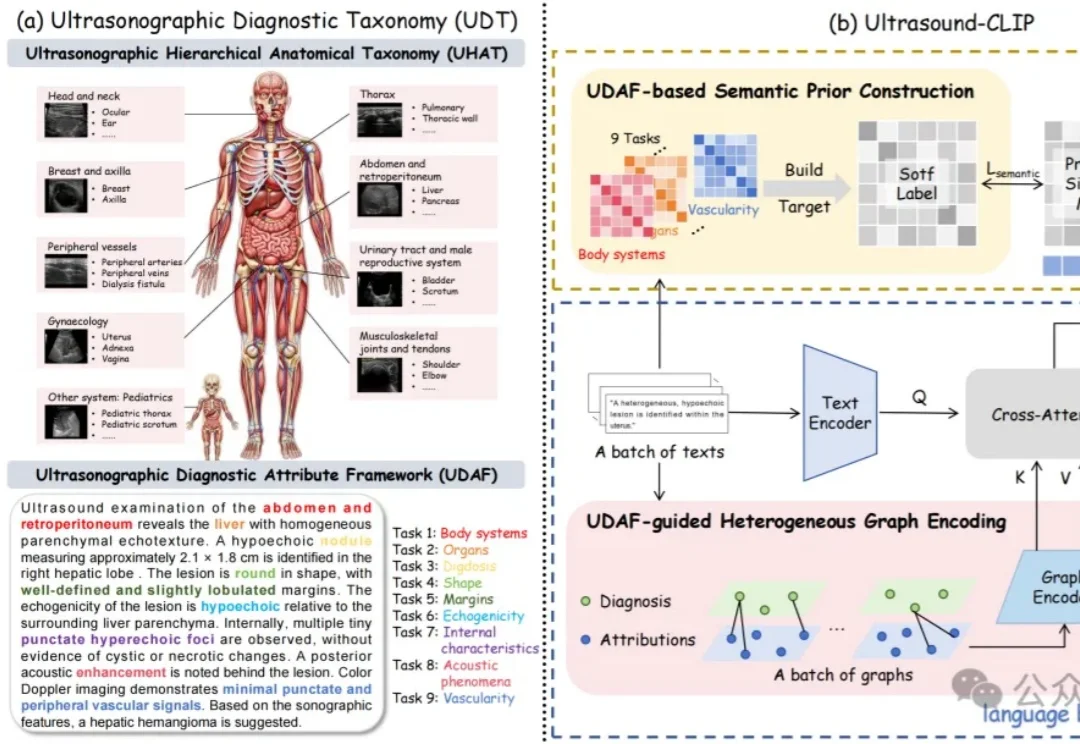
36.4万超声图文对!中国团队构建首个大规模超声专属数据集,让AI真正读懂临床诊断语义丨CVPR'26
36.4万超声图文对!中国团队构建首个大规模超声专属数据集,让AI真正读懂临床诊断语义丨CVPR'26超声领域也有大模型了!
来自主题: AI技术研报
8997 点击 2026-04-13 09:38
 搜索
搜索
超声领域也有大模型了!
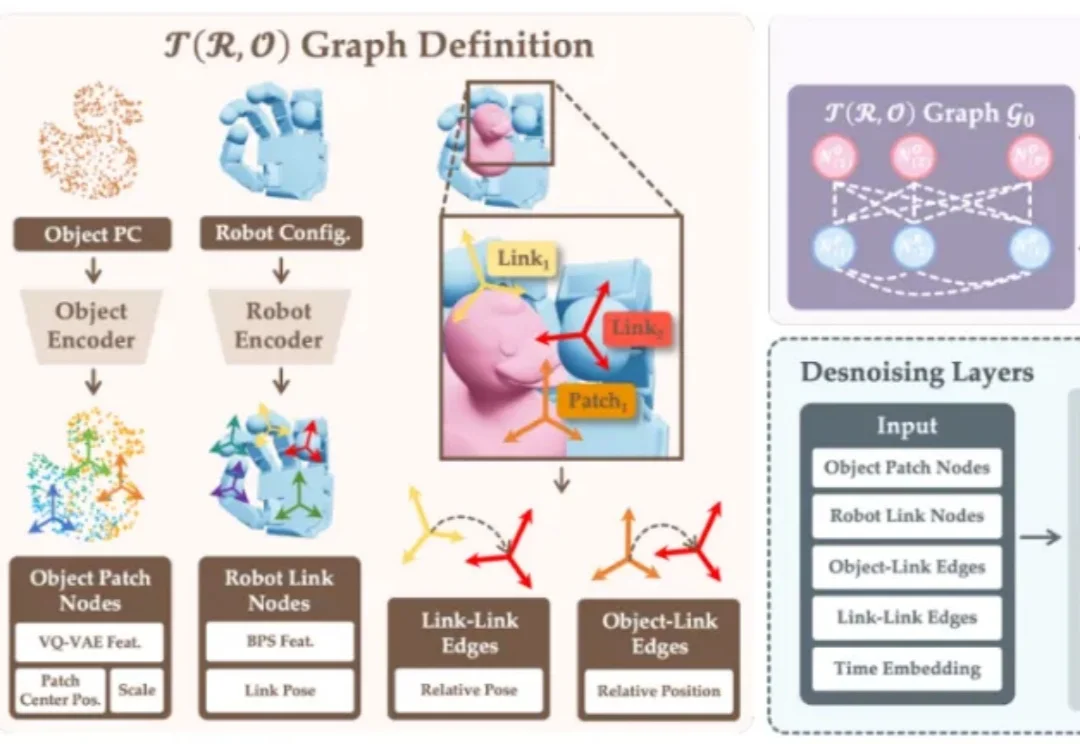
T (R,O) Grasp 是一种基于物体 — 机器手空间关系建模的图扩散架构,具备跨智能体的统一表征能力。在 NVIDIA 40GB A100 GPU 上,该方法可实现 5 FPS 的推理速度和 50 grasp/s 的吞吐量,并在多种智能体上取得 94.83% 的平均抓取成功率,刷新了跨智能体灵巧抓取的 SOTA,具备与动态场景实时交互的能力。

近日,哈尔滨工业大学(深圳)联合深圳河套学院、Independent Researcher提出了隐式思考模型 LRT(Latent Reasoning Tuning),通过一个轻量级的推理网络,将大模型冗长的「思维链」压缩为紧凑的隐式向量表征,一次前向计算即可完成推理,无需逐 token 生成数千字的中间推理过程。

浙江大学联合美团龙猫团队、清华大学推出全新研究成果——SKILL0,并提出技能内化(Skill Internalization)——小模型真正需要的,或许不是推理时的“外挂技能”,而是将技能内化为本能。
今天 Interesting Engineering++ 发了一篇长文,把这些系统放在同一个分析框架里做了横评,回答的就是这些问题。原文地址:interestingengineering.substack.com/p/the-loop-is-the-lab

近日,上海人工智能实验室联合南京大学、香港中文大学及上海交通大学,将OpenClaw的成功应用于多模态生成领域。他们提出GEMS(Agent-Native Multimodal Generation with Memory and Skills),激发小模型潜力,甚至让6B小模型在部分任务超越了Nano Banana 2。
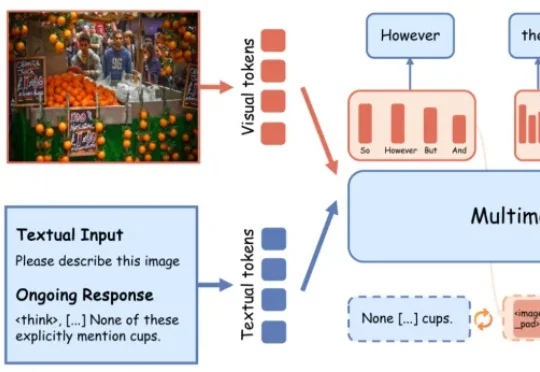
多模态大推理模型的幻觉,很多时候并非「没看见」,而是在最不确定的推理阶段想偏了。最新研究发现,模型在生成because、however、wait等transition words时,往往处于高熵关键节点,更容易脱离图像证据、转向语言脑补。LEAD在高熵阶段不急于输出单一离散token,而是先在潜在语义空间保留多种候选推理方向,并通过视觉锚点持续拉回图像证据,显著缓解幻觉。

最近,来自Meta与University of Copenhagen的研究者提出了OneStory: Coherent Multi-Shot Video Generation with Adaptive Memory(收录于CVPR 2026)。这项工作聚焦于一个核心问题:如何在生成多镜头视频时,有效保留长程跨镜头上下文,从而实现更强的叙事一致性。

超快速 AI 生图领域再破性能天花板!香港科技大学唐靖团队、香港科技大学(深圳分校)胡天阳、小红书 hi-lab 罗维俭提出全新通用强化学习框架 TDM-R1,精准破解超快速扩散生成的核心痛点 —— 仅需 4 步采样(4 NFE),便将组合式生成指标 GenEval 从 61% 飙升至 92%,

过去两年,图像生成模型在质感和审美上一路狂飙,但大多仍是 “直接出图” 的范式。