

合成数据也能通吃真实世界?首个融合重建-预测-规划的生成式世界模型AETHER开源
合成数据也能通吃真实世界?首个融合重建-预测-规划的生成式世界模型AETHER开源近日,上海人工智能实验室(上海 AI 实验室)开源了生成式世界模型 AETHER。该模型全部由合成数据训练而成,不仅在传统重建与生成任务中表现领先,更首次赋予大模型在真实世界中的 3D 空间决策与规划能力,
来自主题: AI技术研报
5826 点击 2025-04-22 14:45
近日,上海人工智能实验室(上海 AI 实验室)开源了生成式世界模型 AETHER。该模型全部由合成数据训练而成,不仅在传统重建与生成任务中表现领先,更首次赋予大模型在真实世界中的 3D 空间决策与规划能力,

DeepSeek-R1 展示了强化学习在提升模型推理能力方面的巨大潜力,尤其是在无需人工标注推理过程的设定下,模型可以学习到如何更合理地组织回答。然而,这类模型缺乏对外部数据源的实时访问能力,一旦训练语料中不存在某些关键信息,推理过程往往会因知识缺失而失败。

当前,强化学习(RL)方法在最近模型的推理任务上取得了显著的改进,比如 DeepSeek-R1、Kimi K1.5,显示了将 RL 直接用于基础模型可以取得媲美 OpenAI o1 的性能不过,基于 RL 的后训练进展主要受限于自回归的大语言模型(LLM),它们通过从左到右的序列推理来运行。

o3和o4-mini视觉推理突破,竟未引用他人成果?一名华盛顿大学博士生发出质疑,OpenAI研究人员对此回应:不存在。
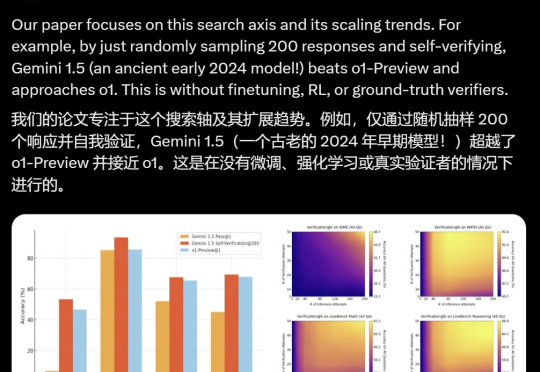
采样多就一定准吗?研究人员用实验告诉你:是的,而且超乎想象!基于采样的搜索不仅能在并行处理中大展身手,还通过隐式扩展让验证更精准。

Hyper-RAG利用超图同时捕捉原始数据中的低阶和高阶关联信息,最大限度地减少知识结构化带来的信息丢失,从而减少大型语言模型(LLM)的幻觉。
近期,大模型智能体(Agent)的相关话题爆火 —— 不论是 Anthropic 抢先 MCP 范式的快速普及,还是 OpenAI 推出的 Agents SDK 以及谷歌最新发布的 A2A 协议,都预示了 AI Agent 的巨大潜力。

具身智能的突破离不开高质量数据。目前,具身合成数据有两条主要技术路线之争:“视频合成+3D重建”or “端到端3D生成”。英伟达在CES 2025指出“尚无互联网规模的机器人数据”,自动驾驶已具备城市级仿真,但家庭等复杂室内环境缺乏3D合成平台。

Nemotron-H模型混合了Transformer和Mamba架构,使长文本推理速度提升3倍,同时还能保持高性能,开源版本包括8B和56B尺寸。训练过程采用FP8训练和压缩技术,进一步提高了20%推理速度

推理模型与普通大语言模型有何本质不同?它们为何会「胡言乱语」甚至「故意撒谎」?Goodfire最新发布的开源稀疏自编码器(SAEs),基于DeepSeek-R1模型,为我们提供了一把「AI显微镜」,窥探推理模型的内心世界。